아무것도 안알려주고 일단 시도해보고 시행착오 겪으면서 실력을 키워나가게 하는 방법임.
Agent가 올바른 행동을 하면 보상(rewards)을 주고, 불리한 행동을 하면 벌점을 부여해줌.
이렇게 행동 하나하나가 쌓여서 보상이 최대화가 되게 만드는 학습방법임.
Agent가 자신이 잘하고 있는 것인지, 잘 못하고 있는 것인지 확실하게 알아야하기에 무조건 scalar feedback을 해야함.
ex) +1, -3, +2.6, +2 ...
환경에 대한 사전지식이 없는 상태로 학습이 시작되고, 보상을 통하여 학습을 함. 어떠한 행동을 했을 때 환경이 어떻게 반응하는지에 따른 보상이 주어짐. 어떻게 보상이 최대화가 될 수 있는지 학습을 하는 것이 강화학습.
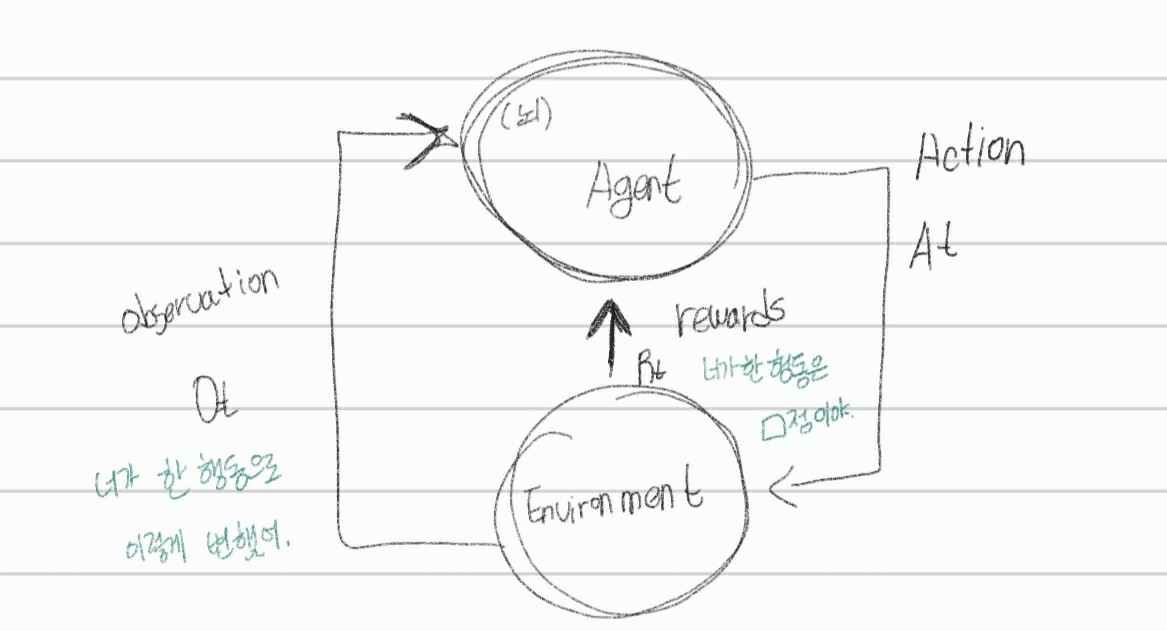
Agent : 주어진 문제 내에서 행동을 하는 주체.
State (상태) : 현재 시점에서 상황이 어떤지 알려주는 값. 가능한 모든 상태의 집합을 state space라고 부름. 다음 행동을 결정하는 정보를 확인하는 것이다.
Markov state : 바로 직전 State만 고려함. 지금의 상태가 중요함. 과거는 보지 않고 현재의 state를 보면서 결정함.
Action (행동) : agent가 취할 수 있는 선택지들.
Reward (보상) : agent가 어떠한 Action을 취하였을 때 따라오는 보상.
현재 상태와 현재 행동에 대해서만 평가하는 즉각적인 값임.
Policy (정책) : 상태에 따른 행동의 조건부 확률. MDP(순차적 행동 결정문제) 에서 구해야할 답.
모든 상태에 대해 agent가 어떤 action을 취해야하는지 정해놓은 것.
최적의 정책(Optimal Policy)를 찾아야 함.
Environment (환경) : agent가 취할 수 있는 행동에 대해 보상을 주는 문제 세팅. 대부분의 정해진 것들.
아무것도 안알려주고 일단 시도해보고 시행착오 겪으면서 실력을 키워나가게 하는 방법임.
Agent가 올바른 행동을 하면 보상(rewards)을 주고, 불리한 행동을 하면 벌점을 부여해줌.
이렇게 행동 하나하나가 쌓여서 보상이 최대화가 되게 만드는 학습방법임.
Agent가 자신이 잘하고 있는 것인지, 잘 못하고 있는 것인지 확실하게 알아야하기에 무조건 scalar feedback을 해야함.
ex) +1, -3, +2.6, +2 ...
환경에 대한 사전지식이 없는 상태로 학습이 시작되고, 보상을 통하여 학습을 함. 어떠한 행동을 했을 때 환경이 어떻게 반응하는지에 따른 보상이 주어짐. 어떻게 보상이 최대화가 될 수 있는지 학습을 하는 것이 강화학습.
Agent : 주어진 문제 내에서 행동을 하는 주체.
State (상태) : 현재 시점에서 상황이 어떤지 알려주는 값. 가능한 모든 상태의 집합을 state space라고 부름. 다음 행동을 결정하는 정보를 확인하는 것이다.
Markov state : 바로 직전 State만 고려함. 지금의 상태가 중요함. 과거는 보지 않고 현재의 state를 보면서 결정함.
Action (행동) : agent가 취할 수 있는 선택지들.
Reward (보상) : agent가 어떠한 Action을 취하였을 때 따라오는 보상.
현재 상태와 현재 행동에 대해서만 평가하는 즉각적인 값임.
Policy (정책) : 상태에 따른 행동의 조건부 확률. MDP(순차적 행동 결정문제) 에서 구해야할 답.
모든 상태에 대해 agent가 어떤 action을 취해야하는지 정해놓은 것.
최적의 정책(Optimal Policy)를 찾아야 함.
Environment (환경) : agent가 취할 수 있는 행동에 대해 보상을 주는 문제 세팅. 대부분의 정해진 것들.