DQN (Deep Q Network)
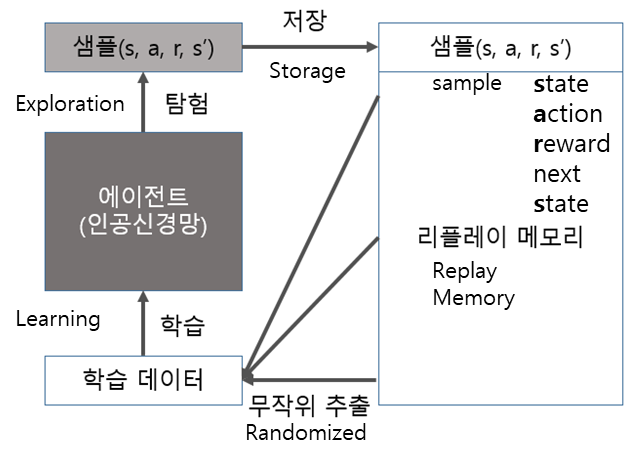
DQN is learning using deep learning neural networks such as CNN.
Method of storing samples obtained from each time step, randomly selecting these samples to configure and update them into mini-batches.
Existing RL, once it start learning in a bad way, it continue learning in a bad way.
The problem is solved by randomly extracting and breaking the correlation between samples.
DQN이란 CNN같은 딥러닝 신경망을 사용하여 학습을 하는 것.
타임스텝별로 얻은 sample(experience)을 저장하여 랜덤으로 뽑아 미니배치로 구성하고 업데이트하는 방법.
랜덤추출함으로써, 한번 안좋은 쪽으로 빠지면 계속 안좋은 쪽으로 학습되던 샘플들의 상관관계가 깨짐.
A3C(Asynchronous Advantage Actor-Critic)
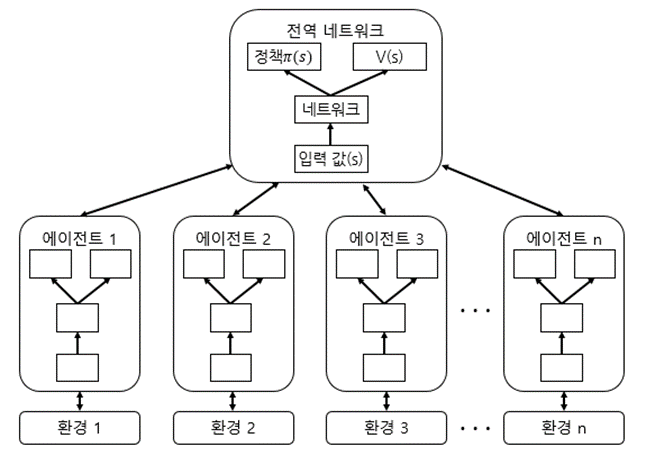
Actor-learner = Each agent that collects samples.
- The same neural network model.
- Different environments.
- Created to break the correlation between learning data for the same reason as DQN.
- Each Actor-learner asynchronously collects a sample during a time-step.
Update the collected samples to the global neural network.
Then, global model is learned, and it is synchronized with the Actor-learner again.
- The speed is fast using multiple agents, so time is shortened and learning performance is excellent.
DQN과 같은 이유로 학습 데이터간의 상관관계를 깨기 위해 만들어짐.
엑터러너들은 각각 비동기적으로 타임스텝 동안 모은 샘플을 글로벌 신경망에 업데이트하고, 모델을 학습하고, 이를 다시 각 엑터러너로 업데이트하여 반복하는 방식.
여러개의 에이전트를 사용하여 속도가 빨라서 시간 단축되고 학습성능이 뛰어남.
Actor 액터 = 상태가 주어지면 행동을 결정
Critic 크리틱 = 그 상태의 가치를 평가 Evaluate the value of State.
DQN (Deep Q Network)
DQN is learning using deep learning neural networks such as CNN.
Method of storing samples obtained from each time step, randomly selecting these samples to configure and update them into mini-batches.
Existing RL, once it start learning in a bad way, it continue learning in a bad way.
The problem is solved by randomly extracting and breaking the correlation between samples.
DQN이란 CNN같은 딥러닝 신경망을 사용하여 학습을 하는 것.
타임스텝별로 얻은 sample(experience)을 저장하여 랜덤으로 뽑아 미니배치로 구성하고 업데이트하는 방법.
랜덤추출함으로써, 한번 안좋은 쪽으로 빠지면 계속 안좋은 쪽으로 학습되던 샘플들의 상관관계가 깨짐.
A3C(Asynchronous Advantage Actor-Critic)
Actor-learner = Each agent that collects samples.
- The same neural network model.
- Different environments.
- Created to break the correlation between learning data for the same reason as DQN.
- Each Actor-learner asynchronously collects a sample during a time-step.
Update the collected samples to the global neural network.
Then, global model is learned, and it is synchronized with the Actor-learner again.
- The speed is fast using multiple agents, so time is shortened and learning performance is excellent.
DQN과 같은 이유로 학습 데이터간의 상관관계를 깨기 위해 만들어짐.
엑터러너들은 각각 비동기적으로 타임스텝 동안 모은 샘플을 글로벌 신경망에 업데이트하고, 모델을 학습하고, 이를 다시 각 엑터러너로 업데이트하여 반복하는 방식.
여러개의 에이전트를 사용하여 속도가 빨라서 시간 단축되고 학습성능이 뛰어남.
Actor 액터 = 상태가 주어지면 행동을 결정
Critic 크리틱 = 그 상태의 가치를 평가 Evaluate the value of State.