Introduction
- Classification, Prediction using RL like DQN.
- Different
Existing deep learning is a method of increasing the accuracy of a model through a network.
DQN is a reinforcement learning method in which Q values are selected and acted through a model.
- Usually, RL does not used to solve classification or Prediction problems.
DQN code used in the game is analyzed and refactored to be used.
- 강화학습 알고리즘인 DQN을 사용해서 분류 및 예측을 시도함
- 일반 딥러닝과 다른 점
기존 딥러닝은 네트워크를 통해 모델의 정확도를 올리는 방식이라면
DQN은 모델을 통해 Q값을 골라서 행동을 하는 강화학습 방식이다.
- 강화학습으로는 보통 게임, 로봇과 같은 문제를 해결한다.
강화학습으로 보통 classification이나 prediction 문제를 해결하지 않기에 게임에서 사용되는 DQN 코드를 분석하고 리팩토링하여 사용함.
Data
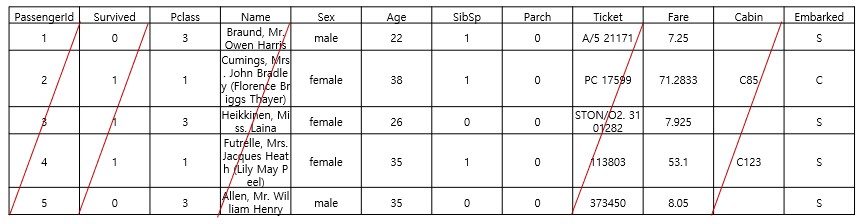
Using Titanic Dataset in the Kaggle.
total of 12 attribute values and 891 data.
Using 7 attributes excluding 5 attributes.
데이터셋은 캐글에 타이타닉으로 실험해봄
총 12개의 속성값이 있고, 891개의 데이터가 있음
이 중에서 5개의 속성 빼고 7개의 속성만 가지고 진행해봄
Only DNN
preprocess it to compare.
Train : Validation = 7:3 to share data.
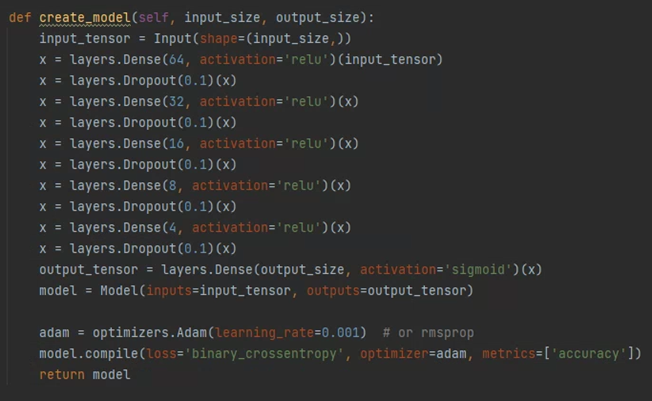
It proceeds under the same conditions using a simple DNN model.
When using a general DNN model using only 7 attribute values,
Train accuracy : 91.493%
Validation accuracy : 74.254%
Test : 62.20%
비교를 하기위해 전처리하고,
Train : Validation = 7:3으로 데이터를 나눔.
간단한 DNN 모델을 사용하여 같은 조건으로 진행함
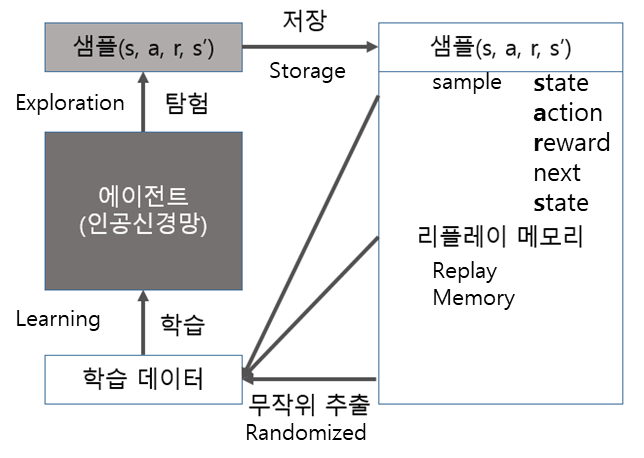
With DQN
When learning with a Deep Q-Network (DQN) model using DNN
Two Q values according to behavior are received through DNN and output.
Among these values, behavior according to a large value or random behavior according to the set epsilon probability.
Try this action and set +100 reward if it get it right and -100 reward if it get it wrong.
This is stored in the replay memory as [Environment, Action, Correct Answer, Reward].
When it becomes larger than the set value of the replay memory, the model is updated by randomly selecting a sample and learning it.
- Using DQN
Train Accuracy : 92.616%
Validation Accuracy : 79.85%
Test : 73.444%
DNN을 사용한 DQN(Deep Q-Network) 모델로 학습하였을 때
DNN을 거쳐 output으로 행동에 따른 2가지의 Q값을 받음.
이 값 중에서 큰 값에 따른 행동을 하거나, 설정한 epsilon 확률에 따른 랜덤한 행동을 함.
이 행동을 해보고 맞추면 +100, 틀리면 -100 reward를 설정함.
이를 리플레이 메모리에 [환경, 행동, 정답, 리워드]로 저장함.
리플레이 메모리 설정한 값보다 커지면 그중에서 랜덤으로 샘플을 뽑아서 학습을 하여 모델을 업데이트함.
Result

Next
Previously, 4,000 pieces of fresh_orange and rotten_orange data were obtained through Crawling.
There is a code that was classified as an Inception model and received about 95% of Test Accuracy.
If we apply the DQN and DDQN algorithms, we will experiment to see if the accuracy will increase further.
- only use the pre-training model,
- DQN algorithm using pre-training model.
이전에 크롤링으로 fresh_orange, rotten_orange 데이터 4천장을 얻고,
Inception 모델로 분류해서 Test Accuracy 약 95% 받은 코드가 있는데,
이를 DQN, DDQN 알고리즘을 적용하면 정확도가 더 올라가나 실험해볼 예정입니다.
- pre-training model만 사용했을 때
- pre-training model을 사용하는 DQN 알고리즘