양자역학을 간단하게 공부하였었습니다. 이를 어느정도 이해한 다음 양자컴퓨팅, 양자AI에 대해서 관련된 여러 논문들을 찾아보고 공부하였는데, 자연어를 양자역학과 융합한 논문이면서 동시에 NAACL에서 Award받은 논문이라 읽게 되었습니다.
Paper Description
- 제목 : CNM: An Interpretable Complex-valued Network for Matching
- 저자 : Li et al.
- Date : 2021.06
- 인용수 : 53
- Publisher : Association for Computational Linguistics
- Venue : NAACL(North American Chapter of the Association for Computational Linguistics)
- Award : Best Explainable NLP Paper
Abstract
- 양자역학의 수학적 틀로 자연어 모델링 해보자!
- 양자역학에서 잘 설계된 수학적 공식 사용해서 single complex-valued vector space 에서 다양한 언어 단위 통합
- 이 모델링이 효과있는지 검증 하기 위한 CNM(Complex-valued Network for Matching)구축
- 본 방안은 QA Task에서 CNN과 RNN 이기는 성능 달성함
Introduction
Cognition(인식,인지)의 새로운 연구 분야는 인간의 인지, 특히 "언어 이해에 양자 유사 현상이 존재함"을 시사함.
문장은 여러 단어(particles 입자와 같은)를 가진 물리적인 시스템으로 취급될 수 있으며, 이러한 단어들은 일반적으로 다의어(중첩)이며 서로 상관관계(얽힘)가 있음.
<논문에서 제시하는 주요 질문 2가지>
1. 양자 물리학의 수학적 틀로 자연어 모델링이 가능할까?
2. 현실 세계의 자연어 처리 시나리오에서 자연어를 complex-valued로 Representation하는 게 benefit 있을까?
1번 질문을 풀기위해서 언어를 모델링하는 새로운 양자 이론적 프레임워크를 구축하였고, 이를통해 자연어의 인지적 측면에서 양자성을 포착하였다고 한다.
본 논문에서 제시하는 새로운 양자 이론적 프레임워크는 균일한 의미론적 힐베르트 공간에서 양자 확률을 채택해 서로 다른 언어 단위를 양자 상태로 모델링 하는 것이다.

두번째 질문을 해결하기 위해 언어 단위를 복소수 벡터로 공식화하였고, 길이를 각 단어간의 weight, 방향을 중첩상태로 연결하였다고 함.
추가적으로 중첩 상태는 진폭 위상 방식으로 표현 가능하다고 하는데, 이는 주파수 개념과 파동 개념을 알아야 할듯 함.
언어적 의미에 해당하는 진폭과, 감정과 같은 더 높은 수준의 의미적 측면을 암시적으로 반영하는 위상으로 표현 가능하다고 함.
그러면서 QA Task에서 복소수 임베딩이 일반적인 단어 임베딩 대비 우수한 성능을 뽑아내는 것을 확인하면서, 자연어는 복소수로부터 이점을 얻는다고 주장함.
결론적으로 이 두 질문에 대해 효과를 검증하기 위해 CNM (Complex-valued Network for Matching)이라는 네트워크를 구축하고 QA Task에서 검증을 진행함.

추가적으로 본 논문에서는 RNN과 CNN 모델들이 현재 QA Task에서 높은 성능을 보인다고 하였는데, 옛날 기준임. 요즘은 트랜스포머 기반의 모델들이 많이 올라옴. 어쨌든 이런 RNN과 CNN 기반의 모델들은 불투명한 구조여서 사람들이 이를 분석하고 해석하기 어려움. 본 논문에서 제시하는 CNM은 양자역학에서 영감받아서 자연어 모델링을 하였고, 해석가능성과 투명성있는 네트워크라고 주장하였음. 사후 해석 가능성은 모델이 실행된 후에 설명 가능한 것이고, 투명성은 모델이 설계단계에서 설명 가능한 것임. 둘다 통합해서 그냥 설명가능한 인공지능(XAI)라고 말하는 듯함. 그래서 이 논문이 Explainable award 받은 듯.
양자역학 기반 자연어 모델링
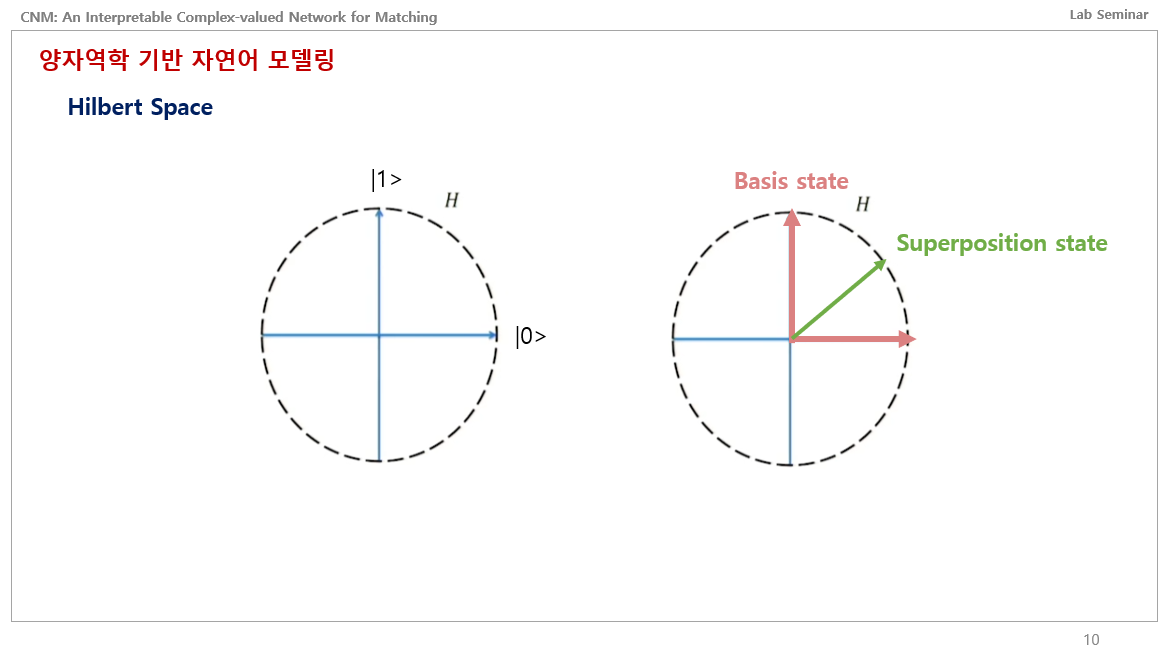
일단 양자역학을 알기 위해서는 얽힘, 중첩, 관측 이 3가지가 가장 중요함.
몇 주간 이와 관련되서 여러 유튜브 영상과 논문들, 교육 블로그 보면서 어느정도 공부했음.
어찌됐든 힐베르트 공간을 이렇게 평면상으로 본다고 하였을 때, 윗방향과 오른쪽방향은 큐빗이 완벽하게 1일 확률, 0일 확률을 나타내는 Basis State임. 그러면 이 사이에 있는 큐빗은 중첩 상태인 것임.
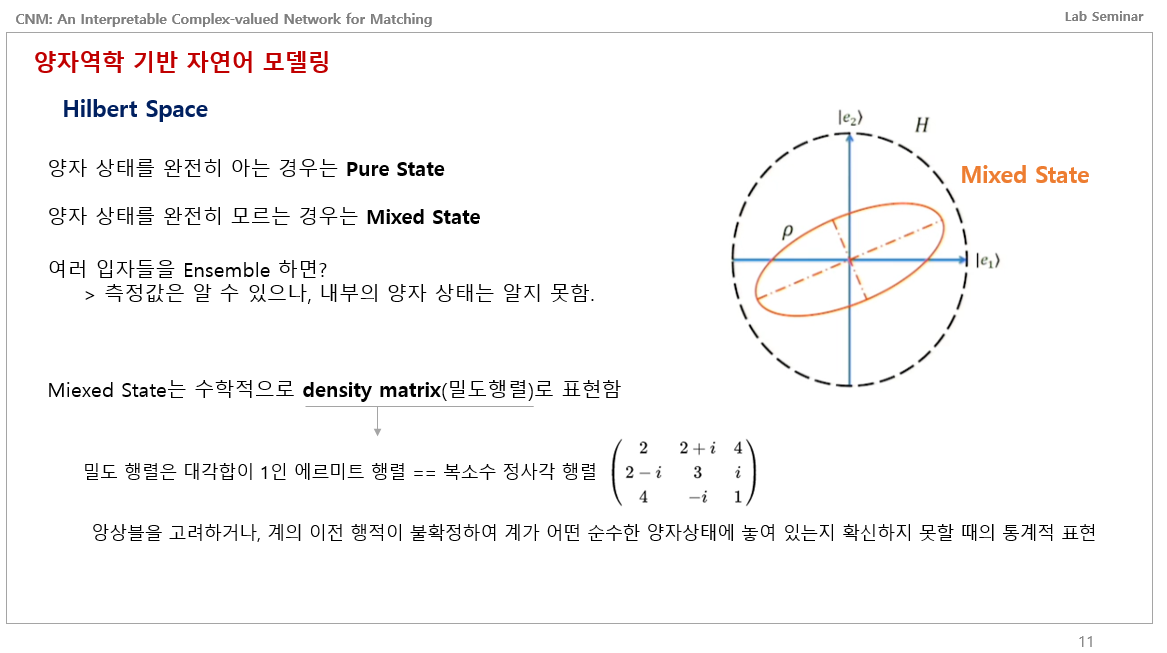
이제 이를 기반으로 Mixed State를 알아야하는데, 양자 상태를 완전히 알면 Pure State라고 하고, 양자 상태를 완전히 모르면 Mixed State라고 말한다고 함.
여러 양자들을 Ensemble하면 표면적으로는 0이다 1이다 알수 있지만, 내부적으로 양자들이 무슨 상태인지는 알 수 없다고 함.
그래서 이런 Mixed State는 Density matrix라고 밀도 행렬로 표현한다고 함.
밀도 행렬은 대각합이 1인 에르미트 행렬이며 다른말로 복소수 정사각 행렬이라고 함.
위키백과를 보면 이런 밀도행렬은 앙상블을 고려하거나 계의 이전 행적이 불확정해서 계가 어떤 순수한 양자상태에 놓여있는지 확실하게 모를 때 쓰는 통계적인 표현이라고 함.

자 이제 힐베르트 공간에서 시맨틱 힐베르트 공간으로 넘어옵니다. 의미론적 힐베르트 공간은 Sememes의 orthogonal basis 상태에 의해 확장된다고 가정한다 합니다. 이게 무슨말이냐면, 예를 들어서 husband라는 단어가 있을 때, 왼쪽처럼 명사로는 남편, 동사로는 절약하다 라는 뜻이 있습니다. 이 단어는 두개의 sense로 나뉩니다. 하나는 결혼한 남자, 반대편은 조심히 사용한다 즉 절약한다. 이들을 또 나누면 결혼한 남자는 사람이자, 가족, 남자, 배우자이며, 반대편은 절약하다를 뜻하는 economize 임.
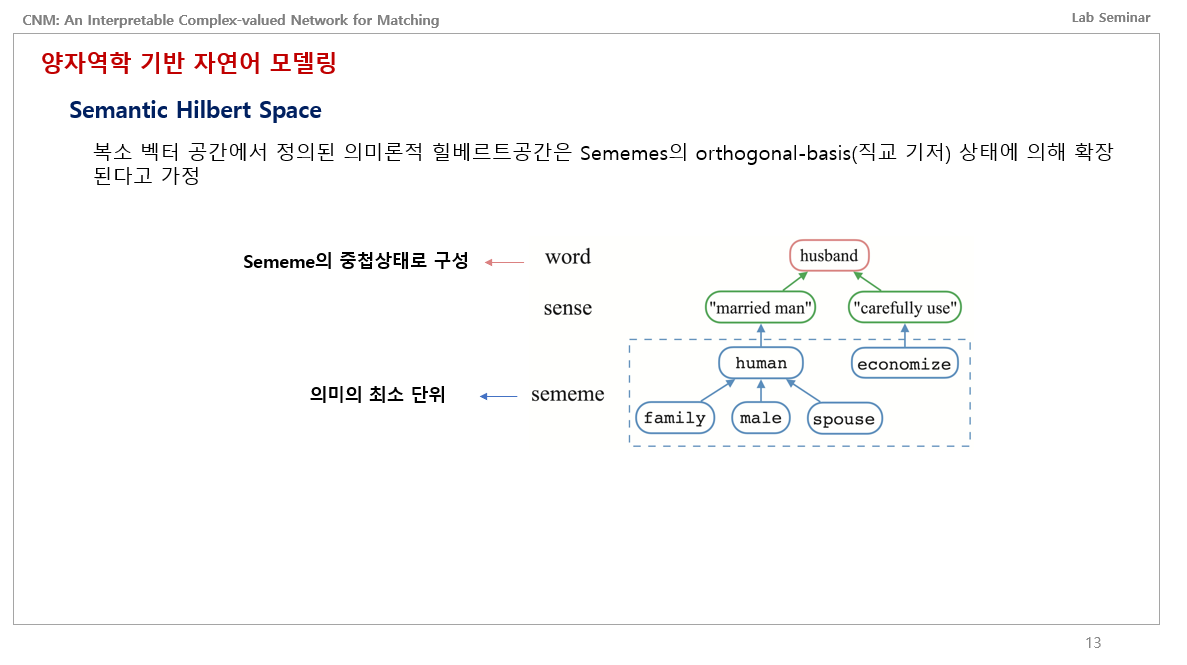
즉, Sememe라는 것은 의미의 최소 단위를 뜻하는 것이며, Word는 Sememe의 중첩 상태로 구성되는 것임.
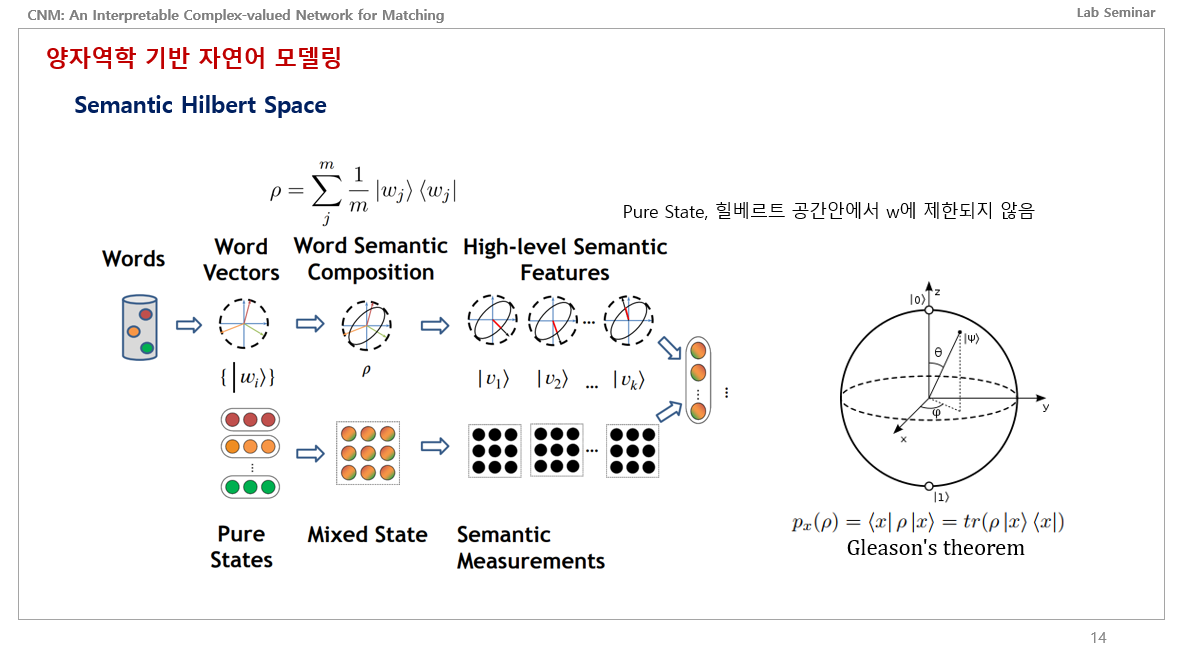
그림을 보면 Words가 있죠. 단어들. 즉 문장을 뜻하는 겁니다. 문장안에 있는 하나하나의 단어들을 힐베르트 공간에 매칭시키면 각각의 단어 백터가 있을 거고, 이들은 아까 말한 확실히 알 수 있는 Pure States에 존재합니다.
이런 단어 백터들을 의미론적으로 하나로 합쳐버리면 이들은 중첩상태가 될 것이고, 이는 곳 Mixed State에 존재합니다.
이런 Mixed State는 밀도행렬 p로 표현이 가능한데 위의 식에서 m은 문장에서의 단어 개수이고, 오른쪽은 중첩상태를 의미합니다.
이런 중첩 상태의 mixed state에서는 high level semantic features를 관측할 수 있다고 하는데, 이를 Semantic Measurements라고 합니다.
완벽하게 이 수식을 이해하진 못했는데 제가 해석하기론, 이런 중첩상태에 있는 값을 관측 할떄마다 어떠한 값으로 수렴될 것이고, 이 수렴된 값은 Pure States에 존재하며 힐베르트 공간안에서 word 하나에 국한되지 않는다는 의미로 해석하였습니다.
그러고 얘네들을 사용해서 확률값을 얻는데 이는 오른쪽에 Gleason의 이론 방정식을 사용해서 구한다고 합니다.
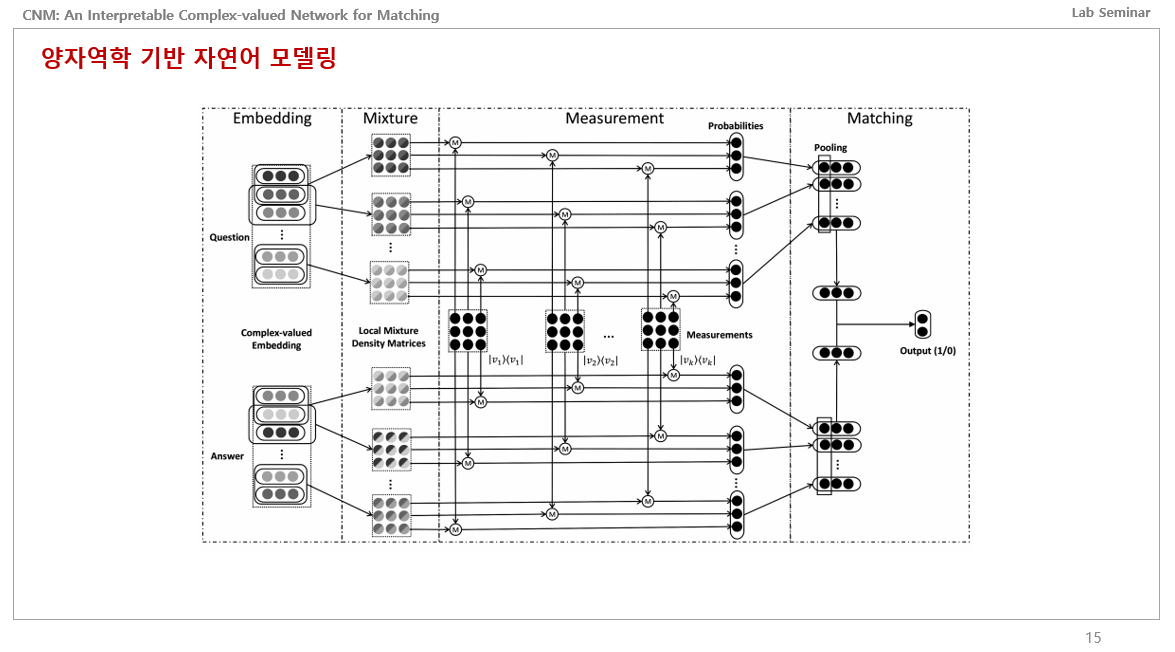
이게 논문에서 제안하는 CNM 네트워크의 전체적인 구조입니다.
처음 봤을땐 진짜 이해안가고 난생 처음보는 설계도 같았습니다. 이게 전자 회로쪽이 합쳐지다 보니 그림을 이렇게 표현하는 것 같습니다.
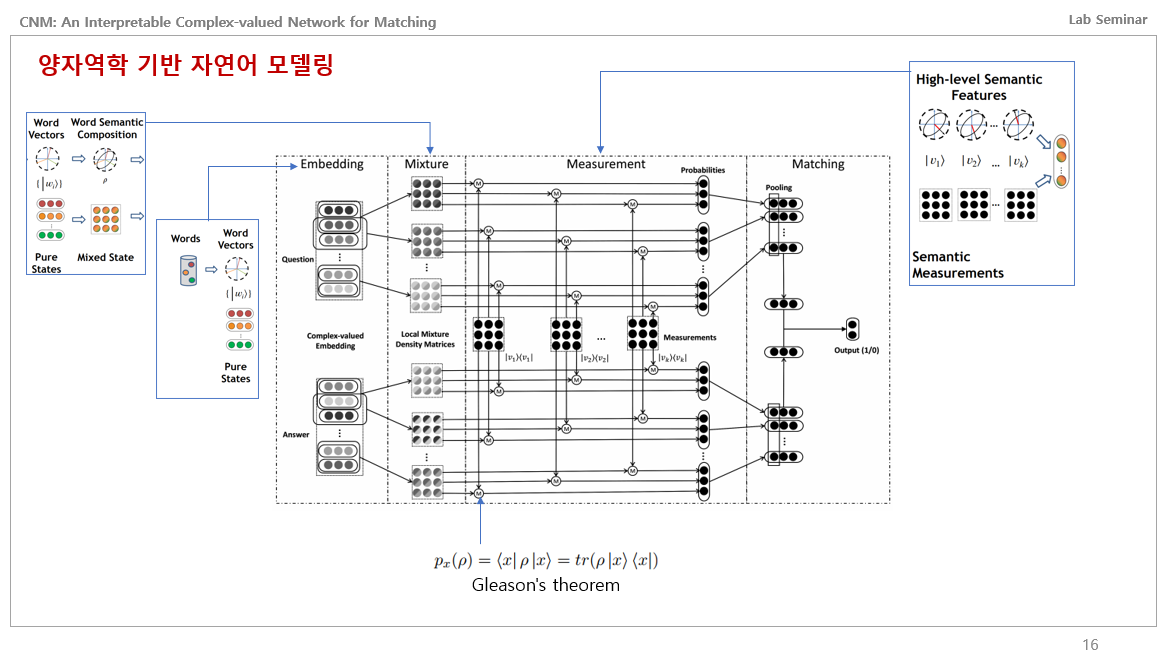
그래서 이해하기 쉽게 방금 전에 설명했던 그림으로 매칭을 해보자면, 임베딩 같은 경우에는 문장에서의 단어들을 각각의 벡터로 매칭하여 Pure States에 존재하게 임베딩하는 것이고,
Mixture같은 경우는 이 Pure States에 존재하는 단어들을 각각 묶어서 중첩상태로 만들어 Mixed State로 매칭시키고 이를 밀도행렬로 표현하는 것 같습니다.
Measurement는 이 Mixture에서의 Mixed State에 있는 각각의 벡터값들을 관측해서 하이레벨 의미론적 피쳐값들을 뽑아낸 다음, 각각의 밀도행렬들과 Gleason 방정식을 통해 확률을 뽑아내고, 이들을 입출력 차원을 맞춰주고 pooling하고 계산해서 output값이 나오도록 하는 네트워크인 듯 합니다.
수식이 엄청 많은데, 이해하기 쉽게 거의 사용하지 않고 설명하였습니다. 물리학 전공이 아니여서 투영같은 개념이 단기간 내에 학습할 수 있어보이진 않습니다..
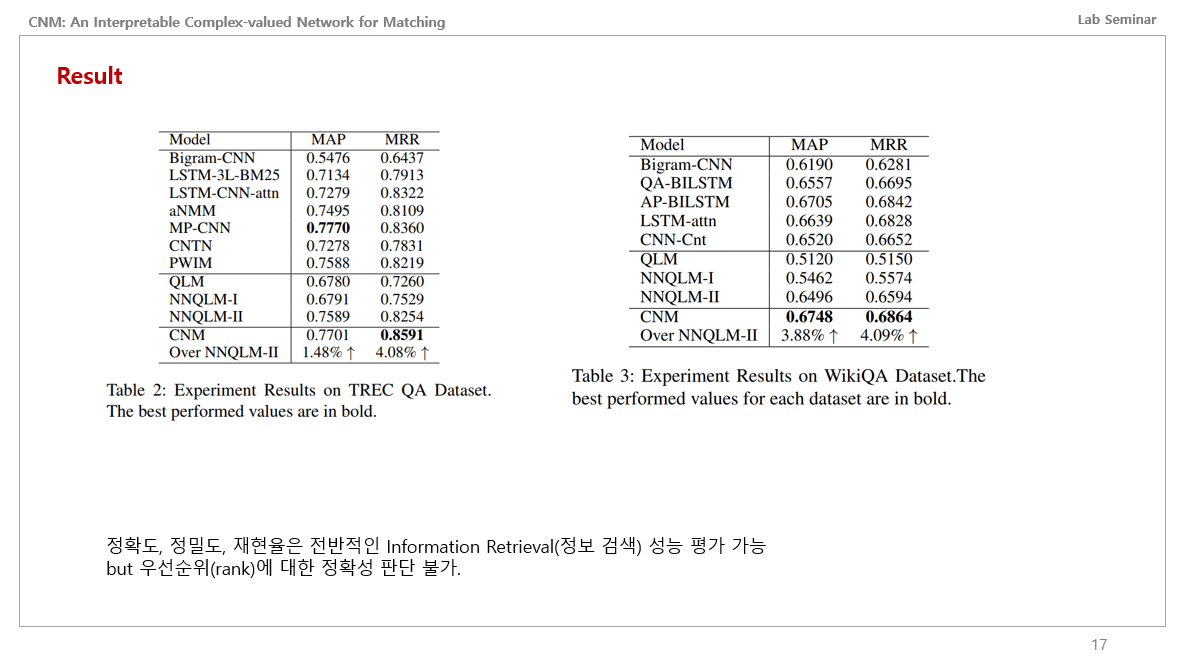
어찌됐든 이런 메커니즘을 통해서 QA Task를 풀어보니 CNN과 RNN 기반의 모델들에 비해 아주 살짝 높은 성능을 얻은 것을 확인할 수 있었습니다.
여기서 MAP와 MRR 성능지표는, 우선순위에 대한 정확성을 판단하는 성능지표라고 합니다. 이는 추천시스템에서 많이 쓰는 성능지표라고 하는데 정확도, 정밀도, 재현율은 전반적인 정보검색(Information Retrieval) 성능 평가가 가능하지만 Rank에 대해서는 고려하지 않기에 이를 쓴다고 합니다.
데이터셋을 보자면 이런식으로 되어있습니다. 참고하면 될듯합니다.

근데 이게 결과를 보면 알겠지만 유의미하게 높은 성능은 아닙니다. 여기서는 성능을 올리는 기술이다가 중점이 아니라, 의의를 중요시 합니다. 논의를 보자면 첫번째로 본 논문에서 제안하는 프레임워크는 투명성있다고 합니다. 단일 복소수 벡터 공간에서 많은 의미 단위를 통합하는 것을 목표로 합니다. 훈련 가능한 투영 측정이 단어, 문장에 대한 높은 수준의 표현을 추출한다고 합니다.
위의 표를 보면, 현실세계에서의 Sememe와 word, Abstraction 를 양자역학 세계에 매칭했다는 것이 첫번째 의의입니다.

두번째는 해석가능성입니다. 단어 가중치 체계 면에서 보자면, 가장 중요한 상위 50개 단어, 하위 50개 단어의 가중치를 뽑아보았을 때, 중요한 단어는 특정 주제에 대한 것들, 혹은 고유명사를 중요하다 판단하였고, 중요하지 않은 단어는 의미없는 숫자나 너무 많이 쓰이는 단어들을 선택하였다고 합니다.

해석 가능성의 두번째로는 매칭 패턴인데, 각 단어에 대해 상대적인 가중치를 시각화 했을 때 의미론적 힐베르트 공간에서 단어를 유사한 단어로 대체하는 것이 강력하다고 하며, 경험적인 관점에서 특정 일치 패턴이 문장 의미에 중요한 상황에서 다른 모델들 (RNN, CNN) 을 능가한다고 합니다. [ ]는 N그램 윈도우 경게이며, 색이 진할수록 weight가 큰 것 입니다. Local 면에서 보자면 Qustion과 Answer을 잘 매칭한다고 하는 것 같습니다.

사후 해석 가능성의 세번째는 차별적인 Semantic Measurements 라고 합니다.
TREC QA 데이터셋에서 10개의 Measurements를 뽑고 이 중에서 랜덤으로 5개를 선택해서 예제로 보여주는데,
랜덤으로 선택된 5개의 Measurements에서 가장 유사한 단어의 일부들을 보여준 표라고 합니다.
위쪽은 위치, 이동 동사, 사람이름에 관한 단어들이고
아래쪽은 역사와 rebellion에 관한 내용이였다고 합니다.
이를 보아서, 측정값에 대한 명확한 설명은 안되지만, 측정값에 대해 대략적인 의미를 이해할 수 있다고 합니다.
제가 이해한 것을 쉽게 말하자면, 양자역학의 프레임워크에서 뭔가 있는데 이를 뽑았을 때 그게 뭔지 정확히 설명은 안된다만, 유사한 단어들을 출력해볼 수 있고, 이를 통해 Measurement 값을 추정가능하다고 하는 듯 합니다.
결론으로 가서, 처음에 제시한 두가지 질문에 대해 해답을 얻을 수 있었고, 추가적으로 두가지를 더 보여주었음.
이 논문을 읽어보니 양자AI, 양자컴퓨팅에서 자연어처럼 의미론적으로 중첩 상태가 될 수 있는 개념을 인코딩, 임베딩 하는 아이디어 괜찮아보임. 근데 이게 물리학 개념이 너무 강해서 이런 수식을 이해하고 구현할 수 있는 것이 관건인 듯 함.