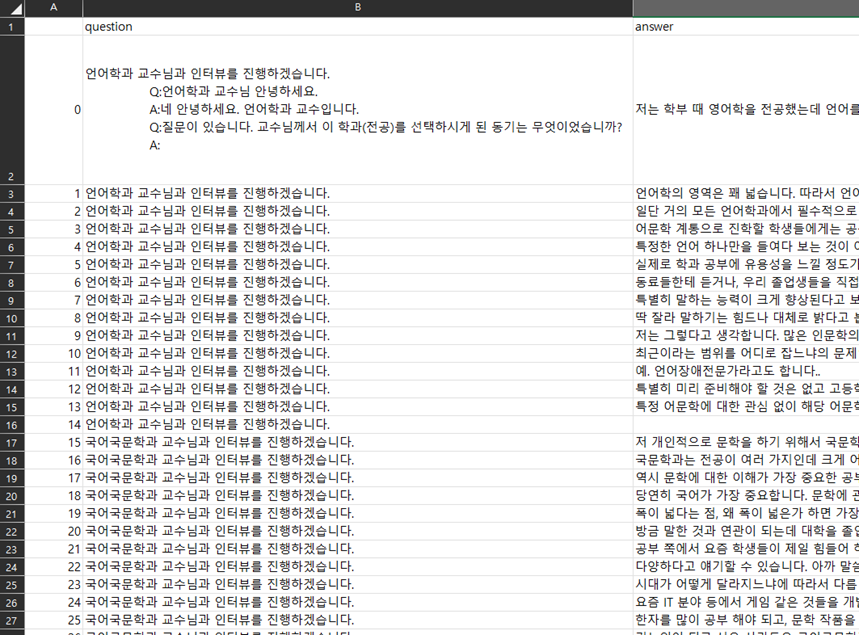
주제 : 중고등학생을 위한 학과 교수님 인터뷰 챗봇
의의 : 대학 진학 전, 유용한 정보를 얻을 수 있음!
결과 미리보기 :

학습에 필요한 데이터셋 :

학과의 개수는 총 320개가 있으며, 평균 질의응답 개수는 11쌍, 최대 19쌍 까지 이어집니다.
데이터셋의 대표 질문:
1.교수님께서 전공 선택한 동기이 무엇인가요
2.어떤 분야에 관심 갖는 사람이 이 학과로 오면 좋을까요3.이 학과에서 가장 중요한 공부는 어떤 내용인가요4.이 학과에서 공부 잘할려면 중고등학생때 어떤 교과목을 공부하면 좋은가요5.이 학과의 장점은 뭔가요6.이 학과의 학생들이 겪는 어려움은 뭔가요7.학과 졸업생이 가장 많이 진출하는 직업분야는 어느 곳인가요8.학과의 앞으로의 전망은 어떤가요9.지금은 없지만 앞으로 새로 생기게 될 직업은 어떤게 있나요10.이 학과를 전공하려는 학생이 진학 전에 공부해야 될것이 있다면 어떤건가요11.이 학과를 지망하는 중고등학생한테 마지막 한말씀 해주세요
추가적인 아이디어

딱딱한 답변이 아닌, 문장을 하나씩 말하듯이 내뱉으면서 감정을 붙이면 좋을 듯 했다!
이걸 어케하느냐
Emotion Recognition in Conversation
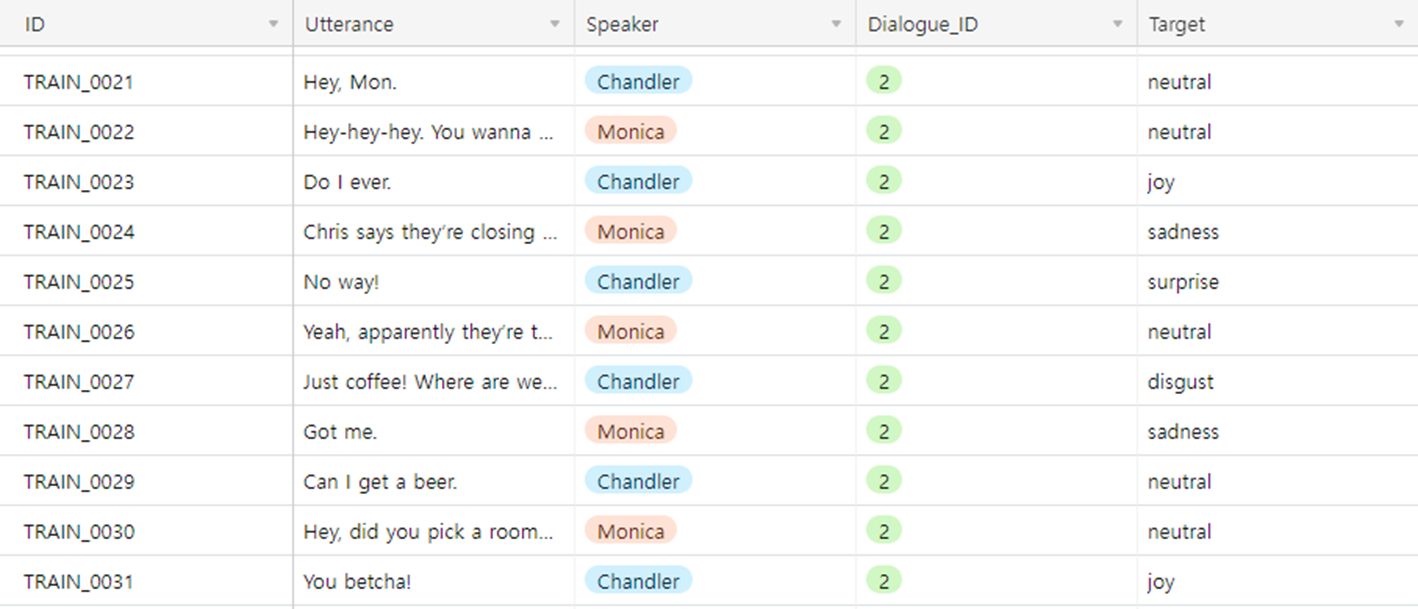
대화 내에서 발화자의 감정을 인식하는 Task가 있음. 이를 ERC라고 함.
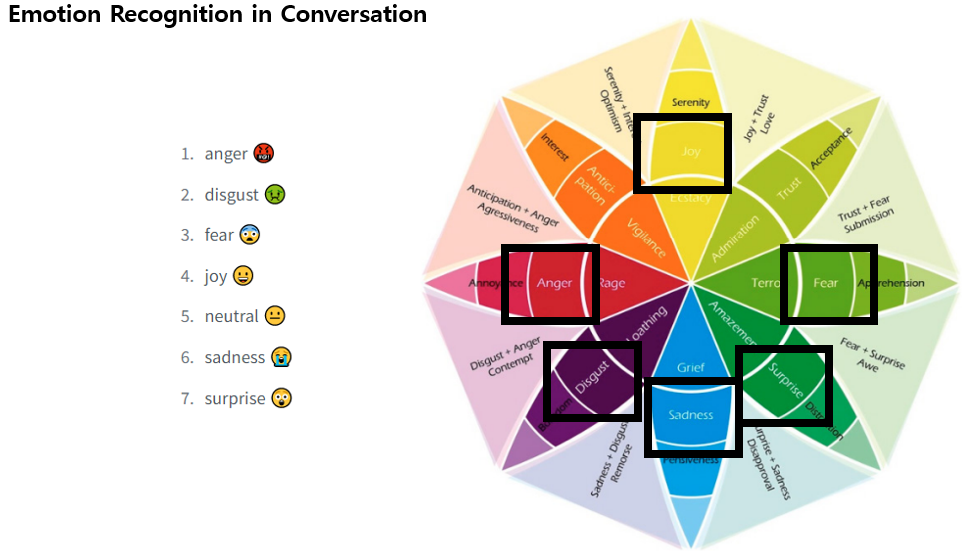
위의 MELD 데이터셋에는 총 7개의 감정이 있는데, 위의 사진과 같음!!
그래서 이러한 ERC 모델을 합치면 감정 표현 가능.
Overview
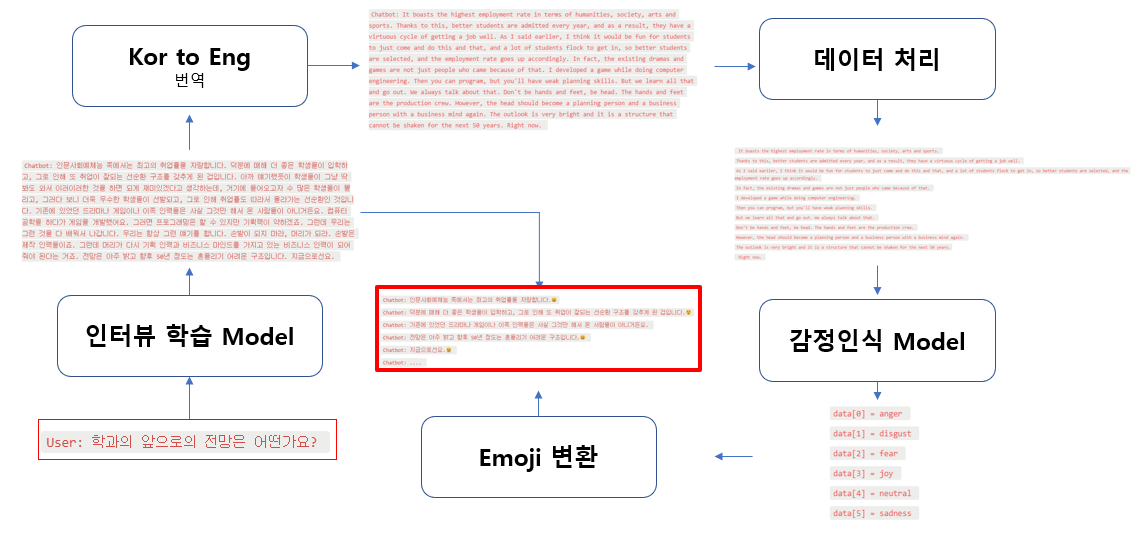
1. 인터뷰 학습
인터뷰를 위해 데이터셋을 학습할 모델이 필요함. 본인은 KoGPT를 선택함!
데이터 전처리해서 질문-답변 총 2개의 column으로 구성했고, 총 4,259개의 쌍이 나옴.
but,

GPU의 한계로 Fine-Tuning 불가했음.
따라서 In-context Learning을 사용해서 추론하기로 함.
2. 번역
감정인식을 하기 위해서 번역작업이 필요했습니다.
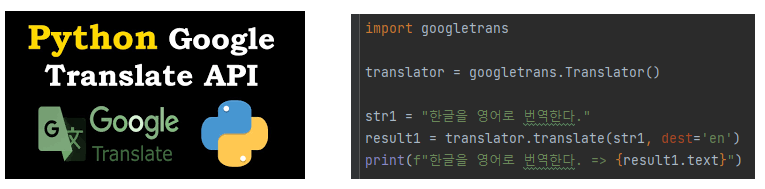
구글의 Translate 라이브러리 사용해서 한국어 > 영어로 변환해주었습니다.
3. 감정 인식

챗봇이 말하는 문장의 감정을 인식해야하니 이와 맞는 모델을 학습하거나 찾아야죠.
저는 허깅페이스에서 Emotion English DistilRoBERTa-base라는 모델을 가지고왔습니다!
얘는 왼쪽에 보이는 데이터셋으로 학습했다고 합니다.
이 모델을 사용한 결과를 보면
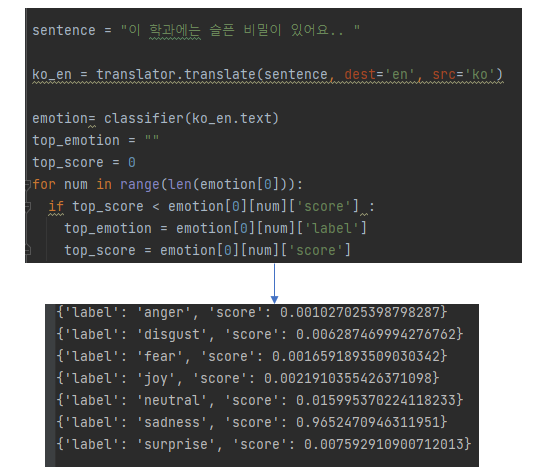
아주 잘 인식 하네요. 예제를 넣으면 번역을 통해 각각의 감정에 따른 확률값을 보여줍니다. sadness가 가장 크네요.
이제 이 감정을 이모지로 표현할거에요
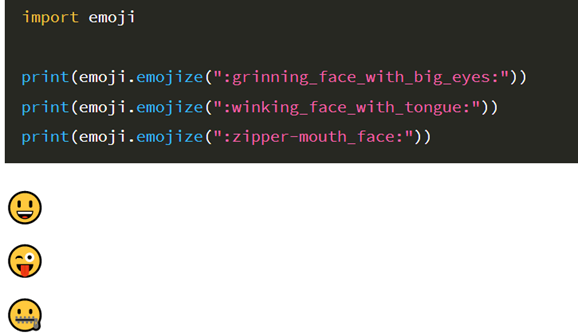
파이썬에는 이런 라이브러리가 있어요! 이모지를 출력해줍니다.
우리가 표현해야하는 감정의 이모지 이름을 찾아보니 아래와 같이 나왔습니다!

이제 아까 구한 최고 확률값과 이 이모지를 1대1 매칭 해주면 이렇게 됩니다!
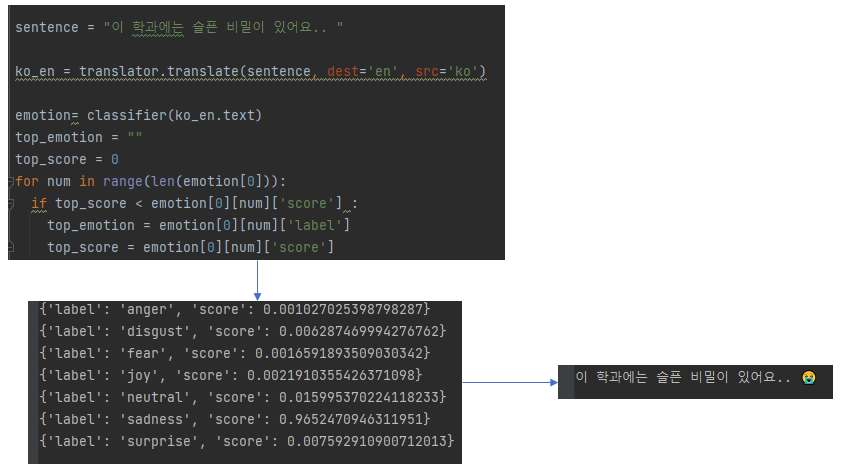
자 이러고 처음에 한글로 출력된 결과값과 이모지를 합쳐주면 전체적인 overview 설명 끝!
이제 결과를 다시볼까요?

진짜 잘 뽑을 땐 놀랍게 잘뽑아요!!
이러고 블로그 업로드를 위해 간결한 코드를 제작하여 첨부하였습니다.
이상 GPT를 사용하여 만든 한국어 학과 인터뷰 챗봇 제작기였습니다.
감사합니다.
구현을 위한 간단한 코드!
100줄도 안되쥬?
import time
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
from transformers import pipeline
import emoji
import googletrans
classifier = pipeline("text-classification", model="j-hartmann/emotion-english-distilroberta-base", return_all_scores=True)
change = {'anger' : ":face_with_symbols_on_mouth:",
'disgust' : ":nauseated_face:",
'fear' : ":fearful_face:",
'joy' : ":grinning_face:",
'neutral' : ":neutral_face:",
'sadness' : ":loudly_crying_face:",
'surprise' : ":astonished_face:"
}
translator = googletrans.Translator()
tokenizer = AutoTokenizer.from_pretrained(
'kakaobrain/kogpt', revision='KoGPT6B-ryan1.5b-float16', # or float32 version: revision=KoGPT6B-ryan1.5b
bos_token='[BOS]', eos_token='[EOS]', unk_token='[UNK]', pad_token='[PAD]', mask_token='[MASK]'
)
model = AutoModelForCausalLM.from_pretrained(
'kakaobrain/kogpt', revision='KoGPT6B-ryan1.5b-float16', # or float32 version: revision=KoGPT6B-ryan1.5b
pad_token_id=tokenizer.eos_token_id,
torch_dtype='auto', low_cpu_mem_usage=True
).to(device='cuda', non_blocking=True)
_ = model.eval()
def gpt_interview(prompt, max_length: int = 256, ends_interview: bool = False):
with torch.no_grad():
model.eval
tokens = tokenizer.encode(prompt, return_tensors='pt').to(device='cuda', non_blocking=True)
gen_tokens = model.generate(tokens, do_sample=True, temperature=0.8, max_length=max_length)
generated = tokenizer.batch_decode(gen_tokens)[0]
generated_answer = generated[len(prompt):]
end_idx = generated_answer.index('Q')
return generated[len(prompt):len(prompt) + end_idx - 1]
try:
major = input("<챗봇이 연결되었습니다.> \n 어느 학과 교수님과 인터뷰 할까요? \n User: ")
time.sleep(2)
first = input(f'{major} 교수님과 인터뷰를 진행하겠습니다. 질문을 해주세요. \n User:')
prompt = f"""{major} 교수님과 인터뷰를 진행하겠습니다.
Q:{first}
A:"""
user = ''
while user!="종료":
chatbot = gpt_interview(prompt, max_length=300)
for sentence in chatbot.split('.'):
try:
ko_en = translator.translate(sentence, dest='en', src='ko')
emotion = classifier(ko_en.text)
top_emotion = ""
top_score = 0
for num in range(len(emotion[0])):
if top_score < emotion[0][num]['score']:
top_emotion = emotion[0][num]['label']
top_score = emotion[0][num]['score']
print(f"\n{major}교수님: {sentence}{emoji.emojize(change[top_emotion])}")
time.sleep(1)
except:
continue
user = input('\nUser: ')
prompt = f"""{major} 교수님과 인터뷰를 진행하겠습니다.
Q:{user}
A:"""