Distributed Representations of Words and Phrases and their Compositionality
Mikolov, Tomas, et al. "Distributed representations of words and phrases and their compositionality."Advances in neural information processing systems26 (2013).
Abstract (Eng.)
The recently introduced continuous Skip-gram model is an efficient method for learning high-quality distributed vector representations that capture a large number of precise syntactic and semantic word relationships. In this paper we present several extensions that improve both the quality of the vectors and the training speed. By subsampling of the frequent words we obtain significant speedup and also learn more regular word representations. We also describe a simple alternative to the hierarchical softmax called negative sampling. An inherent limitation of word representations is their indifference to word order and their inability to represent idiomatic phrases. For example, the meanings of “Canada” and “Air” cannot be easily combined to obtain “Air Canada”. Motivated by this example, we present a simple method for finding phrases in text, and show that learning good vector representations for millions of phrases is possible.
Abstract (Kor.)
최근 도입된 연속 스킵그램 모델은 많은 수의 정밀한 구문 및 의미어 관계를 포착하는 고품질 분산 벡터 표현을 학습하는 효율적인 방법입니다. 본 논문에서는 벡터의 품질과 교육 속도를 향상시키는 몇 가지 확장을 제시합니다. 빈번한 단어들의 서브샘플링을 통해 우리는 상당한 속도를 얻고 또한 보다 규칙적인 단어 표현을 배웁니다. 또한 음성 샘플링이라고 하는 계층적 소프트맥스에 대한 간단한 대안을 설명합니다. 단어 표현의 본질적인 한계는 어순에 대한 무관심과 관용구를 표현할 수 없다는 것입니다. 예를 들어, "Canada"와 "Air"의 의미는 "Air Canada"를 얻기 위해 쉽게 조합될 수 없습니다. 이 예에서 영감을 받아 텍스트에서 문구를 찾는 간단한 방법을 제시하고 수백만 구에 대한 좋은 벡터 표현을 학습할 수 있음을 보여줍니다.
Efficient Estimation of Word Representations in Vector Space
Mikolov, Tomas, et al. "Efficient estimation of word representations in vector space."arXiv preprint arXiv:1301.3781(2013).
Abstract (Eng.)
We propose two novel model architectures for computing continuous vector representations of words from very large data sets. The quality of these representations is measured in a word similarity task, and the results are compared to the previously best performing techniques based on different types of neural networks. We observe large improvements in accuracy at much lower computational cost, i.e. it takes less than a day to learn high quality word vectors from a 1.6 billion words data set. Furthermore, we show that these vectors provide state-of-the-art performance on our test set for measuring syntactic and semantic word similarities.
Abstract (Kor.)
우리는 매우 큰 데이터 세트에서 단어의 연속 벡터 표현을 계산하기 위한 두 가지 새로운 모델 아키텍처를 제안합니다. 이러한 표현의 품질은 단어 유사성 작업에서 측정되며, 결과는 다른 유형의 신경망을 기반으로 한 이전의 최고 성능 기술과 비교됩니다. 훨씬 낮은 계산 비용으로 정확도가 크게 향상되었습니다. 즉, 16억 단어 데이터 세트에서 고품질 단어 벡터를 학습하는 데 하루도 걸리지 않습니다. 또한 이러한 벡터가 구문 및 의미론적 단어 유사성을 측정하기 위한 테스트 세트에서 최첨단 성능을 제공한다는 것을 보여줍니다.
Word2Vec의 기본 구조
첫번째 논문 → CBOW, Skip-gram
두번째 논문 → Negative Sampling
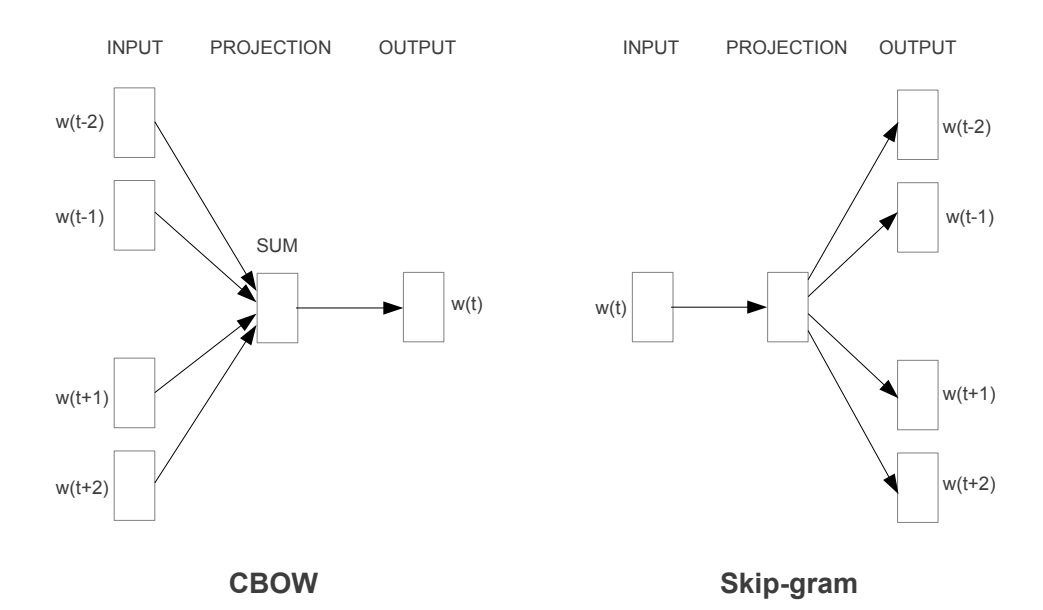
CBOW → 주변의 문맥 단어(Context Word)를 가지고 타깃 단어(Target Word)를 맞히는 과정에서 학습
Skip-gram → 타깃 단어(Target Word)를 가지고 주변 문맥 단어(Context Word)가 무엇일지 예측하는 과정에서 학습
약간 인코딩 디코딩 같은 느낌
이전 NPLM까지만 해도 행렬 곱 연산을 해서 엄청 오래걸렸는데, skip-gram은 행렬곱 연산을 수행하지 않아서 매우 효율적임.
윈도우(Window) 개념 타깃 단어를 중심으로 앞뒤 몇개의 단어를 살펴볼 것인지(=문맥 단어로 둘 것인지) 정하는 범위. 여러단어로 구성된 문장에서 한단어씩 옆으로 옮겨가며 타깃 단어를 바꾸어 나가는 방식은 슬라이딩 윈도우(sliding window).
CBOW
“I like natural language processing” 이라는 예시 문장이 있을 때
→ natural를 타켓단어로 두고 윈도우 사이즈 2라고 한다면,
→ {I, like, language, processing}이 input 데이터가 됨.
랜덤으로 초기화된 히든레이어의 파라미터 출력 값이 {natural}이 되도록 학습됨.
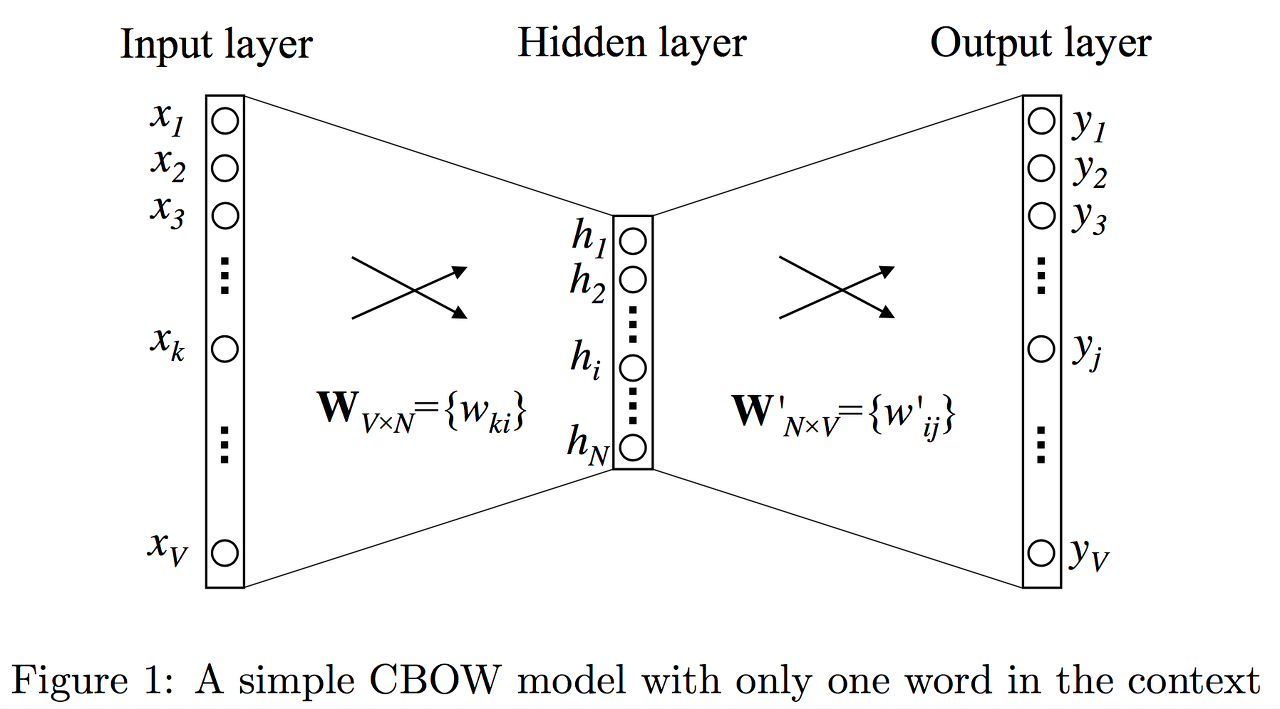
Input과 Output
전부 one-hot encoding 벡터.
1*|V| (어휘 집합의 크기) 를 크기를 갖는 벡터.
W와 W’
모델에서 학습되는 파라미터 행렬.
|V| * d (임베딩 차원수)
h
h로 표현되는 두 행렬의 곱은 W행렬의 한 행과 동일
h는 각 단어 벡터와 W 행렬을 곱한 값들의 평균을 사용
Hidden Layer.
W와 W’ 두 행렬의 곱을 통해 모든 단어 |V|개에 대해 점수를 계산하고,
마지막으로 이 예측 점수를 확률 값으로 바꾸기 위해 softmax를 취해줌.
각 단어의 점수에 비례해 점수를 확률로 바꾸어줌.
Skip-gram
“I like natural language processing” 이라는 예시 문장이 있을 때
같은 크기의 말뭉치에 대해 Skip-gram의 학습량이 더크기에 임베딩 품질이 더 좋고, 따라서 CBOW보다는 Skip-gram방식을 많이 사용함.
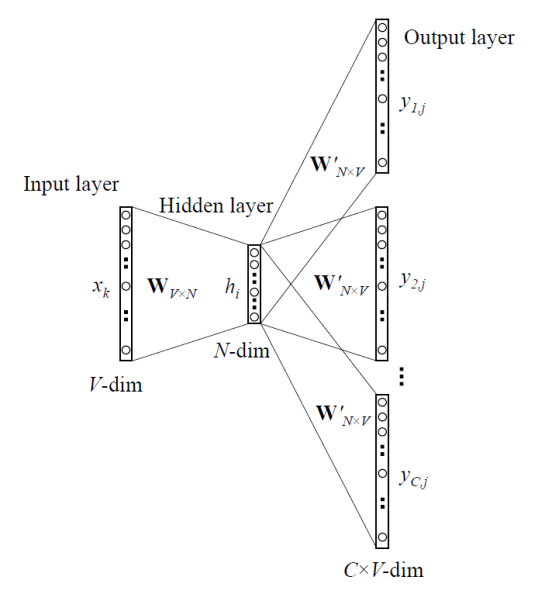
Input과 Output
전부 one-hot encoding 벡터.
1*|V| (어휘 집합의 크기) 를 크기를 갖는 벡터.
W와 W’
모델에서 학습되는 파라미터 행렬.
|V| * d (임베딩 차원수)
u
W’의 열벡터
v
W의 행벡터
좌변 → 조건부 확률. 타겟단어 C가 주어졌을 때, 문맥단어 O가 나타날 확률.
분자를 키울려면 타깃 단어에 해당하는 벡터와 문맥 단어에 해당하는 벡터의 내적을 키운다.
벡터의 내적 = 코사인 값 → 두 단어의 유사도 높이는 것.
파라미터 행렬 W는 단어 임베딩 벡터가 모인 것으로 Word2Vec의 최종 결과물.
타깃 단어를 입력받아 문맥 단어를 출력하는 모델을 학습한다는 것은 정답 문맥 단어가 나타날 확률은 높이고 나머지 단어들은 확률을 낮춰주는 과정. 단어수가 늘어날수록 계산량이 증가하게 된다. 이런 문제점을 해결하기 위한 방법이 네거티브 샘플링.
코드 구현
""" CBOW """## using pytorchimport torch
import torch.nn as nn
EMBEDDING_DIM = 128
EPOCHS = 100
example_sentence = """
Chang Choi is currently an Assistant Professor in the Department of Computer Engineering at Gachon University, Seongnam, Korea, Since 2020.
He received B.S., M.S. and Ph.D. degrees in Computer Engineering from Chosun University in 2005, 2007, and 2012, respectively.
he was a research professor at the same university.
He was awarded the academic awards from the graduate school of Chosun University in 2012.
""".split()
#(1) 입력받은 문장을 단어로 쪼개고, 중복을 제거해줍니다.
vocab = set(example_sentence)
vocab_size = len(example_sentence)
#(2) 단어 : 인덱스, 인덱스 : 단어를 가지는 딕셔너리를 선언해 줍니다.
word_to_index = {word:index for index, word inenumerate(vocab)}
index_to_word = {index:word for index, word inenumerate(vocab)}
#3) 학습을 위한 데이터를 생성해 줍니다.# convert context to index vectordefmake_context_vector(context, word_to_ix):
idxs = [word_to_ix[w] for w in context] #choi chang is currently 넣으면 인덱스값으로 [n,n,n,n](n=정수)형식으로return torch.tensor(idxs, dtype=torch.long)
# make dataset functiondefmake_data(sentence):
data = []
for i inrange(2, len(example_sentence) - 2):
context = [example_sentence[i - 2],
example_sentence[i - 1],
example_sentence[i + 1],
example_sentence[i + 2]
]
target = example_sentence[i]
data.append((context, target))
return data
data = make_data(example_sentence)
#(4) CBOW 모델을 정의해 줍니다.classCBOW(nn.Module):
def__init__(self, vocab_size, embedding_dim):
super(CBOW, self).__init__()
self.embeddings = nn.Embedding(vocab_size, embedding_dim)
self.layer1 = nn.Linear(embedding_dim, 64)
self.activation1 = nn.ReLU()
self.layer2 = nn.Linear(64, vocab_size)
self.activation2 = nn.LogSoftmax(dim = -1)
defforward(self, inputs):
embeded_vector = sum(self.embeddings(inputs)).view(1,-1) #(1,128)
output = self.activation1(self.layer1(embeded_vector))
output = self.activation2(self.layer2(output))
return output
#(5) 모델을 선언해주고, loss function, optimizer등을 선언해줍니다.
model = CBOW(vocab_size, EMBEDDING_DIM)
loss_function = nn.NLLLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.001)
#(6) 학습을 진행합니다.for epoch inrange(EPOCHS):
total_loss = 0for context, target in data:
context_vector = make_context_vector(context, word_to_index)
log_probs = model(context_vector)
total_loss += loss_function(log_probs, torch.tensor([word_to_index[target]]))
print('epoch = ',epoch, ', loss = ',total_loss)
optimizer.zero_grad()
total_loss.backward()
optimizer.step()
#(7) test하고 싶은 문장을 뽑고, test를 진행합니다.
test_data = ['Chang', 'Choi', 'currently', 'an']
test_vector = make_context_vector(test_data, word_to_index)
result = model(test_vector)
print(f"Input : {test_data}")
print('Prediction : ', index_to_word[torch.argmax(result[0]).item()])
"""
Skip-gram
Skip-gram은 CBOW입출력의 반대.
1개를 주었을 때 4개의 아웃풋을 찾아야함
"""import torch
import numpy as np
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.autograd import Variable #자동미분
torch.manual_seed(1)
embedding_dim = 10
raw_text = """
Chang Choi is currently an Assistant Professor in the Department of Computer Engineering at Gachon University, Seongnam, Korea, Since 2020.
He received B.S., M.S. and Ph.D. degrees in Computer Engineering from Chosun University in 2005, 2007, and 2012, respectively.
he was a research professor at the same university.
He was awarded the academic awards from the graduate school of Chosun University in 2012.
""".split()
defmake_context_vector(context, word_to_idx): #텐서로 변환
idxs = [word_to_idx[w] for w in context]
return torch.tensor(idxs, dtype=torch.long)
vocab = set(raw_text) #리스트형식 > 딕셔너리 형식으로 만듬
vocab_size = len(vocab) #47개 있음.#딕셔너리 형태로 만들기
word_to_idx = {word: i for i, word inenumerate(vocab)}
idx_to_word = {i: word for i, word inenumerate(vocab)}
data = []
for i inrange(2, len(raw_text) - 2):
target = [raw_text[i - 2], raw_text[i - 1],
raw_text[i + 1], raw_text[i + 2]]
context = raw_text[i]
data.append((context, target)) #data에다가 저장.#ex> data = (['Chang', 'Choi', 'currently', 'an'], 'is') ...classSkipGram(nn.Module):
def__init__(self, vocab_size, embedding_dim):
super(SkipGram, self).__init__()
self.embeddings = nn.Embedding(vocab_size, embedding_dim) #임베딩차원 설정
self.proj = nn.Linear(embedding_dim, 128)
self.output = nn.Linear(128, vocab_size)
defforward(self, inputs):
out = sum(self.embeddings(inputs)).view(1, -1) #단어 사이즈넣으면 [,,,,,,,] 형식으로 넣음
out = F.relu(self.proj(out))
out = self.output(out)
out = F.log_softmax(out, dim=-1)
return out
model = SkipGram(vocab_size, embedding_dim)
optimizer = optim.SGD(model.parameters(), lr=0.001)
losses = []
loss_function = nn.NLLLoss()
loss_function1 = nn.CrossEntropyLoss()
for epoch inrange(100):
total_loss = 0for context, target in data:
model.zero_grad()
input = make_context_vector(context, word_to_idx) # torch형식으로 만들기 > tensor[n,n,n,n]
output = model(input)
loss = loss_function(output, Variable(torch.tensor([word_to_idx[target]])))
loss.backward()
optimizer.step()
total_loss += loss.item()
losses.append(total_loss)
print(losses)
print("*************************************************************************")
context = ['Chang', 'Choi', 'currently', 'an']
context_vector = make_context_vector(context, word_to_idx)
a = model(context_vector).data.numpy()
print('Raw text: {}\n'.format(' '.join(raw_text)))
print('Test Context: {}\n'.format(context))
max_idx = np.argmax(a)
print('Prediction: {}'.format(idx_to_word[max_idx]))
https://comlini8-8.tistory.com/6 Distributed Representations of Words and Phrases and their Compositionality Efficient_Estimation_of_Word_Representations_in_Vector_Space https://everyday-log.tistory.com/entry/단어-임베딩-2-Iteration-based-methods
Distributed Representations of Words and Phrases and their Compositionality
Mikolov, Tomas, et al. "Distributed representations of words and phrases and their compositionality."Advances in neural information processing systems26 (2013).
Abstract (Eng.)
The recently introduced continuous Skip-gram model is an efficient method for learning high-quality distributed vector representations that capture a large number of precise syntactic and semantic word relationships. In this paper we present several extensions that improve both the quality of the vectors and the training speed. By subsampling of the frequent words we obtain significant speedup and also learn more regular word representations. We also describe a simple alternative to the hierarchical softmax called negative sampling. An inherent limitation of word representations is their indifference to word order and their inability to represent idiomatic phrases. For example, the meanings of “Canada” and “Air” cannot be easily combined to obtain “Air Canada”. Motivated by this example, we present a simple method for finding phrases in text, and show that learning good vector representations for millions of phrases is possible.
Abstract (Kor.)
최근 도입된 연속 스킵그램 모델은 많은 수의 정밀한 구문 및 의미어 관계를 포착하는 고품질 분산 벡터 표현을 학습하는 효율적인 방법입니다. 본 논문에서는 벡터의 품질과 교육 속도를 향상시키는 몇 가지 확장을 제시합니다. 빈번한 단어들의 서브샘플링을 통해 우리는 상당한 속도를 얻고 또한 보다 규칙적인 단어 표현을 배웁니다. 또한 음성 샘플링이라고 하는 계층적 소프트맥스에 대한 간단한 대안을 설명합니다. 단어 표현의 본질적인 한계는 어순에 대한 무관심과 관용구를 표현할 수 없다는 것입니다. 예를 들어, "Canada"와 "Air"의 의미는 "Air Canada"를 얻기 위해 쉽게 조합될 수 없습니다. 이 예에서 영감을 받아 텍스트에서 문구를 찾는 간단한 방법을 제시하고 수백만 구에 대한 좋은 벡터 표현을 학습할 수 있음을 보여줍니다.
Efficient Estimation of Word Representations in Vector Space
Mikolov, Tomas, et al. "Efficient estimation of word representations in vector space."arXiv preprint arXiv:1301.3781(2013).
Abstract (Eng.)
We propose two novel model architectures for computing continuous vector representations of words from very large data sets. The quality of these representations is measured in a word similarity task, and the results are compared to the previously best performing techniques based on different types of neural networks. We observe large improvements in accuracy at much lower computational cost, i.e. it takes less than a day to learn high quality word vectors from a 1.6 billion words data set. Furthermore, we show that these vectors provide state-of-the-art performance on our test set for measuring syntactic and semantic word similarities.
Abstract (Kor.)
우리는 매우 큰 데이터 세트에서 단어의 연속 벡터 표현을 계산하기 위한 두 가지 새로운 모델 아키텍처를 제안합니다. 이러한 표현의 품질은 단어 유사성 작업에서 측정되며, 결과는 다른 유형의 신경망을 기반으로 한 이전의 최고 성능 기술과 비교됩니다. 훨씬 낮은 계산 비용으로 정확도가 크게 향상되었습니다. 즉, 16억 단어 데이터 세트에서 고품질 단어 벡터를 학습하는 데 하루도 걸리지 않습니다. 또한 이러한 벡터가 구문 및 의미론적 단어 유사성을 측정하기 위한 테스트 세트에서 최첨단 성능을 제공한다는 것을 보여줍니다.
Word2Vec의 기본 구조
첫번째 논문 → CBOW, Skip-gram
두번째 논문 → Negative Sampling
CBOW → 주변의 문맥 단어(Context Word)를 가지고 타깃 단어(Target Word)를 맞히는 과정에서 학습
Skip-gram → 타깃 단어(Target Word)를 가지고 주변 문맥 단어(Context Word)가 무엇일지 예측하는 과정에서 학습
약간 인코딩 디코딩 같은 느낌
이전 NPLM까지만 해도 행렬 곱 연산을 해서 엄청 오래걸렸는데, skip-gram은 행렬곱 연산을 수행하지 않아서 매우 효율적임.
윈도우(Window) 개념 타깃 단어를 중심으로 앞뒤 몇개의 단어를 살펴볼 것인지(=문맥 단어로 둘 것인지) 정하는 범위. 여러단어로 구성된 문장에서 한단어씩 옆으로 옮겨가며 타깃 단어를 바꾸어 나가는 방식은 슬라이딩 윈도우(sliding window).
CBOW
“I like natural language processing” 이라는 예시 문장이 있을 때
→ natural를 타켓단어로 두고 윈도우 사이즈 2라고 한다면,
→ {I, like, language, processing}이 input 데이터가 됨.
랜덤으로 초기화된 히든레이어의 파라미터 출력 값이 {natural}이 되도록 학습됨.
Input과 Output
전부 one-hot encoding 벡터.
1*|V| (어휘 집합의 크기) 를 크기를 갖는 벡터.
W와 W’
모델에서 학습되는 파라미터 행렬.
|V| * d (임베딩 차원수)
h
h로 표현되는 두 행렬의 곱은 W행렬의 한 행과 동일
h는 각 단어 벡터와 W 행렬을 곱한 값들의 평균을 사용
Hidden Layer.
W와 W’ 두 행렬의 곱을 통해 모든 단어 |V|개에 대해 점수를 계산하고,
마지막으로 이 예측 점수를 확률 값으로 바꾸기 위해 softmax를 취해줌.
각 단어의 점수에 비례해 점수를 확률로 바꾸어줌.
Skip-gram
“I like natural language processing” 이라는 예시 문장이 있을 때
같은 크기의 말뭉치에 대해 Skip-gram의 학습량이 더크기에 임베딩 품질이 더 좋고, 따라서 CBOW보다는 Skip-gram방식을 많이 사용함.
Input과 Output
전부 one-hot encoding 벡터.
1*|V| (어휘 집합의 크기) 를 크기를 갖는 벡터.
W와 W’
모델에서 학습되는 파라미터 행렬.
|V| * d (임베딩 차원수)
u
W’의 열벡터
v
W의 행벡터
좌변 → 조건부 확률. 타겟단어 C가 주어졌을 때, 문맥단어 O가 나타날 확률.
분자를 키울려면 타깃 단어에 해당하는 벡터와 문맥 단어에 해당하는 벡터의 내적을 키운다.
벡터의 내적 = 코사인 값 → 두 단어의 유사도 높이는 것.
파라미터 행렬 W는 단어 임베딩 벡터가 모인 것으로 Word2Vec의 최종 결과물.
타깃 단어를 입력받아 문맥 단어를 출력하는 모델을 학습한다는 것은 정답 문맥 단어가 나타날 확률은 높이고 나머지 단어들은 확률을 낮춰주는 과정. 단어수가 늘어날수록 계산량이 증가하게 된다. 이런 문제점을 해결하기 위한 방법이 네거티브 샘플링.
코드 구현
""" CBOW """## using pytorchimport torch
import torch.nn as nn
EMBEDDING_DIM = 128
EPOCHS = 100
example_sentence = """
Chang Choi is currently an Assistant Professor in the Department of Computer Engineering at Gachon University, Seongnam, Korea, Since 2020.
He received B.S., M.S. and Ph.D. degrees in Computer Engineering from Chosun University in 2005, 2007, and 2012, respectively.
he was a research professor at the same university.
He was awarded the academic awards from the graduate school of Chosun University in 2012.
""".split()
#(1) 입력받은 문장을 단어로 쪼개고, 중복을 제거해줍니다.
vocab = set(example_sentence)
vocab_size = len(example_sentence)
#(2) 단어 : 인덱스, 인덱스 : 단어를 가지는 딕셔너리를 선언해 줍니다.
word_to_index = {word:index for index, word inenumerate(vocab)}
index_to_word = {index:word for index, word inenumerate(vocab)}
#3) 학습을 위한 데이터를 생성해 줍니다.# convert context to index vectordefmake_context_vector(context, word_to_ix):
idxs = [word_to_ix[w] for w in context] #choi chang is currently 넣으면 인덱스값으로 [n,n,n,n](n=정수)형식으로return torch.tensor(idxs, dtype=torch.long)
# make dataset functiondefmake_data(sentence):
data = []
for i inrange(2, len(example_sentence) - 2):
context = [example_sentence[i - 2],
example_sentence[i - 1],
example_sentence[i + 1],
example_sentence[i + 2]
]
target = example_sentence[i]
data.append((context, target))
return data
data = make_data(example_sentence)
#(4) CBOW 모델을 정의해 줍니다.classCBOW(nn.Module):
def__init__(self, vocab_size, embedding_dim):
super(CBOW, self).__init__()
self.embeddings = nn.Embedding(vocab_size, embedding_dim)
self.layer1 = nn.Linear(embedding_dim, 64)
self.activation1 = nn.ReLU()
self.layer2 = nn.Linear(64, vocab_size)
self.activation2 = nn.LogSoftmax(dim = -1)
defforward(self, inputs):
embeded_vector = sum(self.embeddings(inputs)).view(1,-1) #(1,128)
output = self.activation1(self.layer1(embeded_vector))
output = self.activation2(self.layer2(output))
return output
#(5) 모델을 선언해주고, loss function, optimizer등을 선언해줍니다.
model = CBOW(vocab_size, EMBEDDING_DIM)
loss_function = nn.NLLLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.001)
#(6) 학습을 진행합니다.for epoch inrange(EPOCHS):
total_loss = 0for context, target in data:
context_vector = make_context_vector(context, word_to_index)
log_probs = model(context_vector)
total_loss += loss_function(log_probs, torch.tensor([word_to_index[target]]))
print('epoch = ',epoch, ', loss = ',total_loss)
optimizer.zero_grad()
total_loss.backward()
optimizer.step()
#(7) test하고 싶은 문장을 뽑고, test를 진행합니다.
test_data = ['Chang', 'Choi', 'currently', 'an']
test_vector = make_context_vector(test_data, word_to_index)
result = model(test_vector)
print(f"Input : {test_data}")
print('Prediction : ', index_to_word[torch.argmax(result[0]).item()])
"""
Skip-gram
Skip-gram은 CBOW입출력의 반대.
1개를 주었을 때 4개의 아웃풋을 찾아야함
"""import torch
import numpy as np
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.autograd import Variable #자동미분
torch.manual_seed(1)
embedding_dim = 10
raw_text = """
Chang Choi is currently an Assistant Professor in the Department of Computer Engineering at Gachon University, Seongnam, Korea, Since 2020.
He received B.S., M.S. and Ph.D. degrees in Computer Engineering from Chosun University in 2005, 2007, and 2012, respectively.
he was a research professor at the same university.
He was awarded the academic awards from the graduate school of Chosun University in 2012.
""".split()
defmake_context_vector(context, word_to_idx): #텐서로 변환
idxs = [word_to_idx[w] for w in context]
return torch.tensor(idxs, dtype=torch.long)
vocab = set(raw_text) #리스트형식 > 딕셔너리 형식으로 만듬
vocab_size = len(vocab) #47개 있음.#딕셔너리 형태로 만들기
word_to_idx = {word: i for i, word inenumerate(vocab)}
idx_to_word = {i: word for i, word inenumerate(vocab)}
data = []
for i inrange(2, len(raw_text) - 2):
target = [raw_text[i - 2], raw_text[i - 1],
raw_text[i + 1], raw_text[i + 2]]
context = raw_text[i]
data.append((context, target)) #data에다가 저장.#ex> data = (['Chang', 'Choi', 'currently', 'an'], 'is') ...classSkipGram(nn.Module):
def__init__(self, vocab_size, embedding_dim):
super(SkipGram, self).__init__()
self.embeddings = nn.Embedding(vocab_size, embedding_dim) #임베딩차원 설정
self.proj = nn.Linear(embedding_dim, 128)
self.output = nn.Linear(128, vocab_size)
defforward(self, inputs):
out = sum(self.embeddings(inputs)).view(1, -1) #단어 사이즈넣으면 [,,,,,,,] 형식으로 넣음
out = F.relu(self.proj(out))
out = self.output(out)
out = F.log_softmax(out, dim=-1)
return out
model = SkipGram(vocab_size, embedding_dim)
optimizer = optim.SGD(model.parameters(), lr=0.001)
losses = []
loss_function = nn.NLLLoss()
loss_function1 = nn.CrossEntropyLoss()
for epoch inrange(100):
total_loss = 0for context, target in data:
model.zero_grad()
input = make_context_vector(context, word_to_idx) # torch형식으로 만들기 > tensor[n,n,n,n]
output = model(input)
loss = loss_function(output, Variable(torch.tensor([word_to_idx[target]])))
loss.backward()
optimizer.step()
total_loss += loss.item()
losses.append(total_loss)
print(losses)
print("*************************************************************************")
context = ['Chang', 'Choi', 'currently', 'an']
context_vector = make_context_vector(context, word_to_idx)
a = model(context_vector).data.numpy()
print('Raw text: {}\n'.format(' '.join(raw_text)))
print('Test Context: {}\n'.format(context))
max_idx = np.argmax(a)
print('Prediction: {}'.format(idx_to_word[max_idx]))
https://comlini8-8.tistory.com/6 Distributed Representations of Words and Phrases and their Compositionality Efficient_Estimation_of_Word_Representations_in_Vector_Space https://everyday-log.tistory.com/entry/단어-임베딩-2-Iteration-based-methods