colab.research.google.com/drive/1vcBfl192NDGJ2_c2u01tAa65NGSJmrw8?usp=sharing
Google Colaboratory
colab.research.google.com
원문입니다. 코랩으로 보는거 추천.
%tensorflow_version
#텐서플로우 라이브러리 설치되어있는지 확인.import keras케라스는 텐서플로를 이용하기 더 쉽게만들어주는 도구임.
심층 신경망을 만들기 위한 텐서플로, 테아노, CNTK와 같은 도구를 더욱 쉽게 사용할 수 있게 도와주는 도구임.
따라서 케라스를 사용하려면 먼저 텐서플로 라이브러리를 불러온 상태여야함.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Activation
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.datasets import mnist
import numpy as np
import matplotlib.pyplot as pltfrom tensorflow.keras.models import Sequential
기본적인 인공 신경망은 레이어가 순차적으로 구성되어 있음.
이렇게 순차적인 신경망을 구성할 때 사용할 수 있는 함수가 케라스의 모델 도구 중 시퀀셜 모델 함수임.
Dense는 전결합층(fully-cinnected layer)을 의미.
입력층 은닉층 출력층과 같은 각 층이 있을때, 그 층과 바로 앞의 층과 서로 연결되어 있는 것이 전결합층이라함.
Dense를 사용하여 각 레이어의 뉴런 개수를 설정할 수 있고,
Activation은 활성화 함수를 의미함.
from tensorflow.keras.utils import to_categorical
유틸 도구중에 to_categorical라는 함수를 불러오는 명령어로, 원-핫 인코딩을 구현할 수 있는 함수임.
여기서 one-hot incoding은 하나의 값만 1로 나타내고 나머지 값들은 전부 0 으로 표시하는 방법이다.
정답레이블을 첫번째, 두번째, ... 와 같이 순서로 나타내도록 데이터의 형태를 바꾸는 것.
케라스를 사용히여 딥러닝 모델 개발을 연습할 수 있는 데이터가 여러 개 있음.
그 데이터들은 데이터셋 도구(datasets)에 있고, mnist는 그 데이터셋 중에 직접 손으로 쓴 숫자 db를 불러오는 명령어임.
mnist는 훈련데이터와 검증데이터로 구성되어있음.
numpy는 수학, 배열등 계산에 필요한 라이브러리.
as는 에일리어싱으로 별명 별칭임. 앞으로 numpy라고 쓰지않고 np라 부르겠다는 뜻임.
matplotlib는 그래프 라이브러리임.
막대그래프나 꺽은선그래프, 히스토그램등 다양한 그래프를 쉽게 그릴 수 있게 만든 함수로, 그 중에서 그림을 그리는 pyplot을 사용하고 이걸 plt라 부르겠다는 뜻임.
(x_train, y_train), (x_test, y_test) = mnist.load_data()
print(x_train.shape)
print(y_train.shape)
print(x_test.shape)
print(y_test.shape)
load_data() 는 mnist 데이터셋에서 데이터를 불러오라는 명령임.
mnist 데이터는 4부분으로 나누어져 있음.
이 값들을 numpy 라이브러리를 사용하여 배열형태(shape)로 가져옴.
train 은 훈련데이터, test는 검증데이터를 뜻하는 변수임.
x_train에는 6만개의 데이터가 있고, 각 그림의 픽셀이 가로와 세로가 28개씩 있음.
훈련 데이터와 검증 데이터에는 손글씨 그림과 그 그림이 무슨 숫자인지(정답)이 같이 들어있음.
y_train 은 x_train 데이터의 정답임. 따라서 똑같이 6만개가 들어있다.
,뒤에 아무것도 안뜨는 것은 1차원 배열이라는 것을 뜻한다.
28*28 형태의 데이터를 인공지능 모델에 넣으려면 1차원 배열로 바꿔야함.
인공 신경망의 입력층에 데이터를 넣을 떄는 한줄로 만들어서 넣어야한다.
현재 mnist의 입력값이 28 * 28 이니 1* 784로 바꿔야한다.
X_Train = x_train.reshape(60000,784) #784개가 한줄(행), 60000개의 데이터(열)
X_Test = x_test.reshape(10000,784)
X_Train = x_train.astype('float32') # 타입이 int형이라 실수형으로 바꿈. 데이터값이 0~1 사이의 값으로 정규화하려면 실수로 표현해야함. 정수로 표현안됌.
X_Test = x_test.astype('float32')
X_Train /= 255 #검은색=0, 흰색 =255, 회색 =1~254 이니 0~1사이로 정규화를 하기위해 255로 나누어줌.
X_Test /= 255
print(X_Train.shape)
print(X_Test.shape)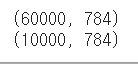
이제 여기서 각 숫자를 몇 번째라고 알려주면 인공지능은 더 높은 성능으로 분류할 수 있음.
그래서 예측이 아닌 분류 문제에서는 보통 정답 레이블을 첫번째, 두번째, 세번쨰 등 순서로 나타내도록 데이터의 형태를 바꿈. 이게 one-hot incoding임.
타입또한 데이터값이 0~1 사이의 값으로 정규화해야하니 int형에서 float형으로 형변환을 시켜줘야함.
Y_train = to_categorical(y_train, 10) #수치형 데이터를 범주형 데이터로 만들어주는 케라스 내부의 유틸 도구.
Y_test = to_categorical(y_test,10) # 변경전 데이터(y_test), 원-핫 인코딩할 숫자(몇 개로 구분할건지 > 10)
print(Y_train.shape)
print(Y_test.shape)
Y_train
to_categorical 함수는 수치형 데이터를 범주형 데이터로 변경시켜주는 함수임.
첫번째 인자는 변경 전 데이터를 넣고,
두번째 인자에는 원-핫 인코딩할 숫자. 즉, 몇 개로 구분할 것인지 값을 넣음.
숫자판단 인공지능은 0~9까지 총 10가지의 숫자를 분류해야하니 10을 넣어줌.
인공지능을 만들기 위해서는 데이터를 만들기 원하는 방향으로 변환하는 것이 중요한 것을 알 수 있음. 그렇기에 데이터 분석 및 변환은 인공지능 개발에서 매우 중요함.