- Greedy Search
- 현재 단어 다음에 나올 단어 후보 중 가장 확률이 높은 것 선택
- (장점) 비교적 간단한 알고리즘
- (단점) 동어 반복 현상 발생
- (단점) 현재 시점 바로 다음 단어만 고려.
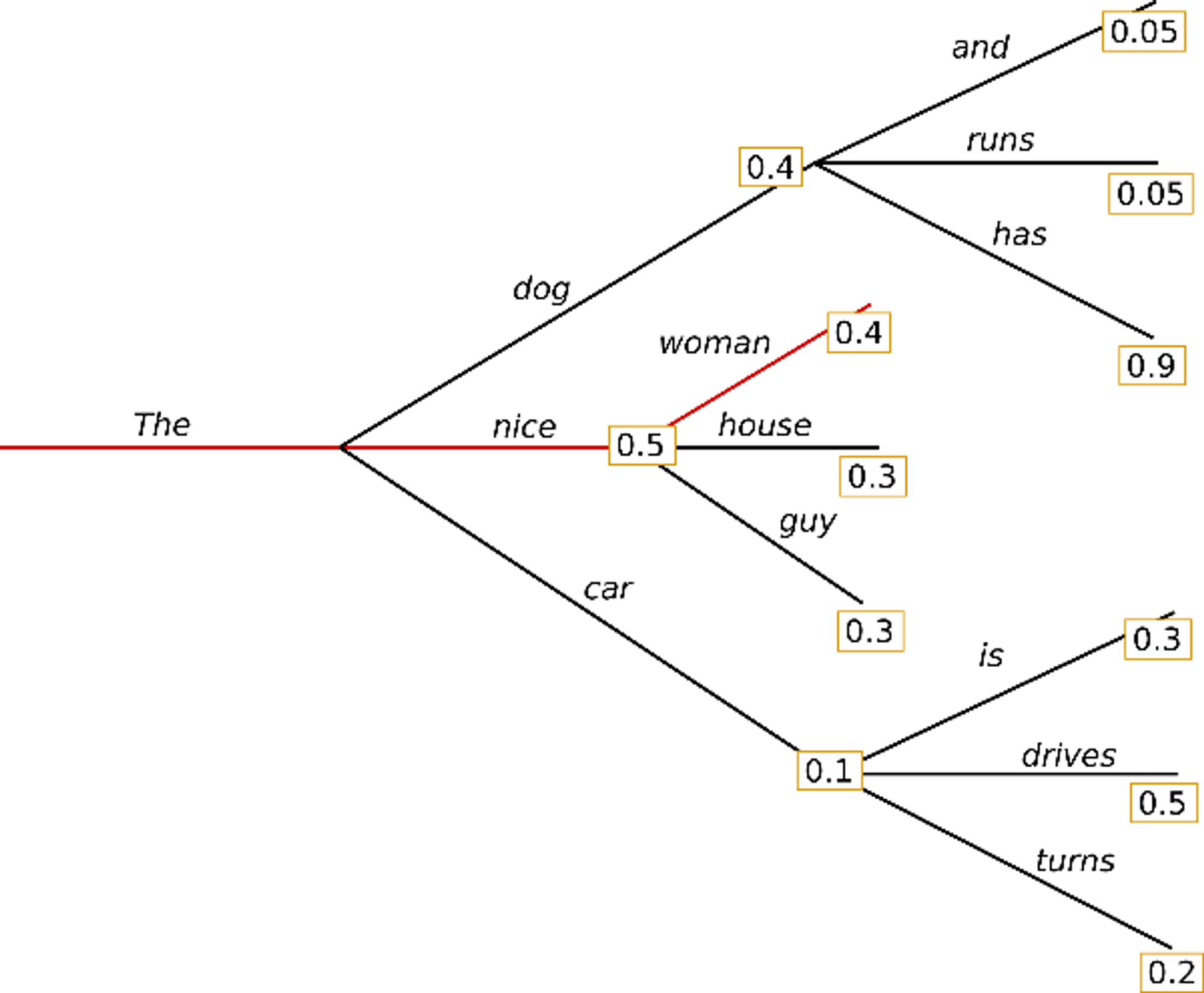
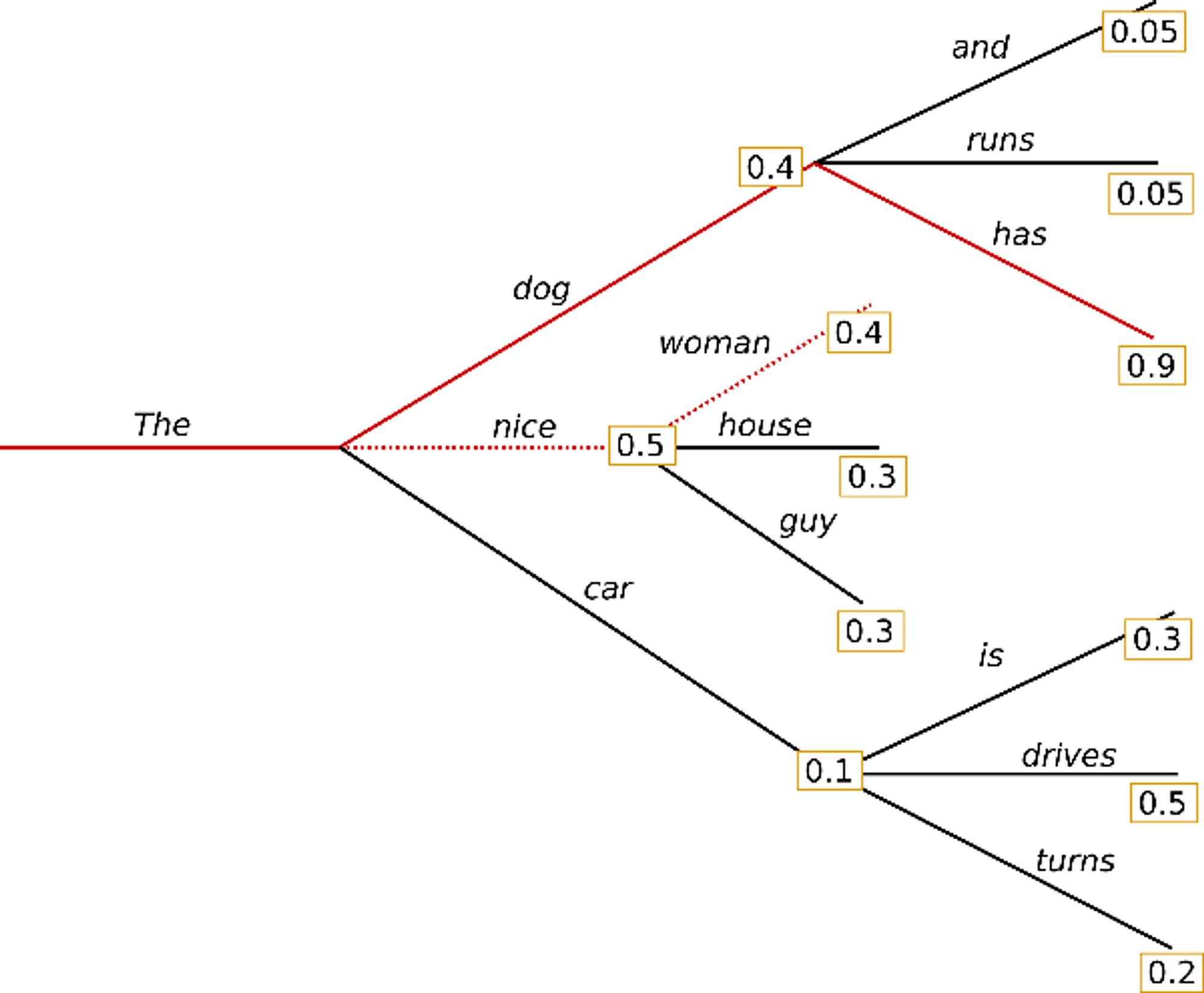
- Beam Search
- 현재시점 이후 여러 step의 단어 조합을 keep 해놓고 해당 확률을 곱하여 점수를 내고 다른 조합과 비교하여 가장 높은 것 선택
- (장점) 뒤에 나올 확률이 높은 단어를 선택하여 좀 더 좋은 문장 생성
- (단점) 연산속도 증가
- (단점) 반복문제 여전히 존재 → n-gram(연속된 단어 개수 허용범위) 사용
- num_beams → Beam Search에 쓰이는 beam의 개수
- no_repeat_ngram_size → 특정 n-gram이 생성문장 내에서 반복되지 않도록 함
- num_return_sequences → 아웃풋 몇 개 받을지
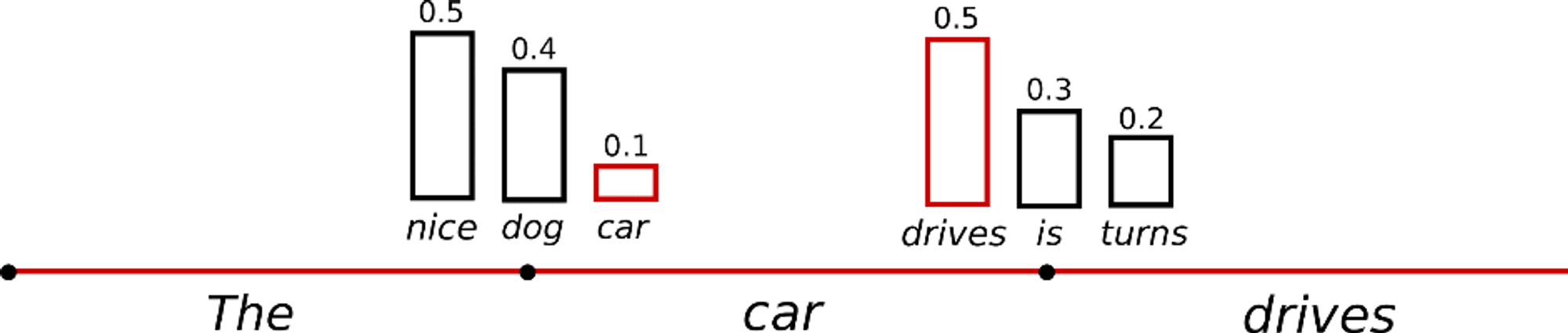
- Sampling
- 조건부 확률 분포에 따라 다음 단어를 랜덤으로 선택
- (장점) 표현력 풍부 및 다양한 단어 사용
- (단점) 말이안되거나 어색한 문장 나올 수 있음
- do_sample → sampling 쓸지 말지 boolean
- temperature → 무작위성 조정 (0에 가까울 수록 Greedy와 유사)
- Top-K Sampling
- K개의 후보 단어를 먼저 필터링 후 확률분포 계산 후 샘플링 진행
- (장점) 높은 단어를 선정하기 때문에 어색한 단어 거를 수 있음
- (단점) 후보에 오를만한 단어여도 top-k안에 못들어서 걸러질 수 있고, 확률이 낮은 단어여도 상위 확률 단어가 몇개 없으면 top-k안에 들어갈 수 있음

- Top-P Sampling (Nucleus Sampling)
- Top-K는 상위 K개의 단어를 선정한다면, Top-P는 누적확률을 기준으로 단어를 선정함. 예를들어 p=0.92로 설정하면 누적확률이 92% 넘으면서, 토큰의 수가 가장 적은 문장을 내뱉는 것.
경험적 관점에서 top-p와 top-k를 같이쓰거나, Beam search가 가장 좋은 아웃풋을 냈었음.