
오늘은 트랜스포머의 인코더 부분을 쉽게 설명하고자함.
많은 사람들이 트랜스포머의 기법에 대해서 물어보면 "Self-attention 기법 사용... 특정 단어에 포커싱.." 혹은 "Q,K,V 사용해서...조합해서 가중치주는 기법..." 정도로만 대답함.
실제 어떤 식으로 돌아가는지 쉽고 자세하게 설명하기 위해 본 포스팅을 진행함.
애매하게 아는 분 환영
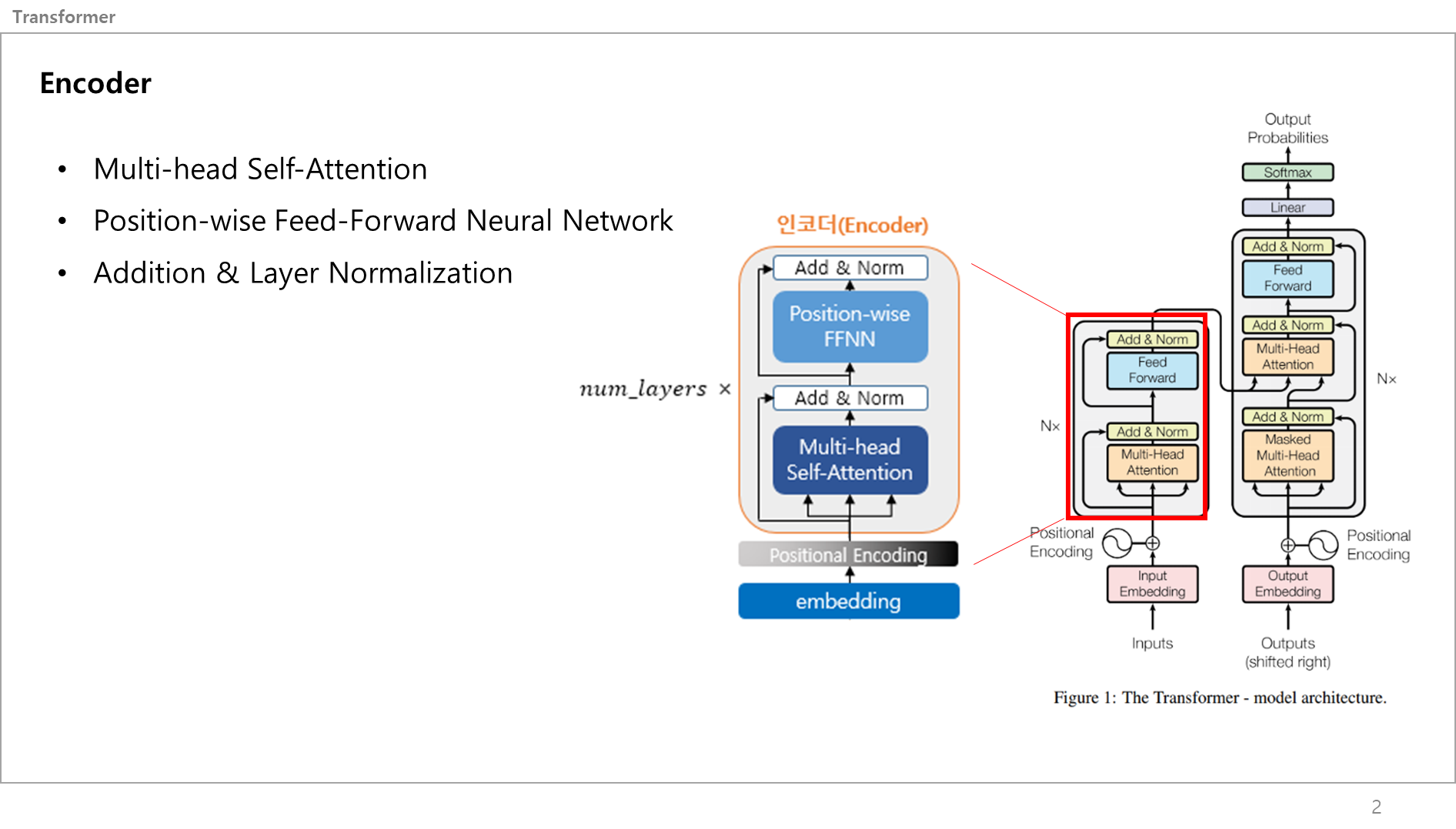
트랜스포머의 인코더 레이어는 그림에서 보이다 싶이 크게 3가지로 나눠볼 수 있음.
- 멀티헤드 셀프어텐션
- 포지셔닝 와이즈 피드포워드 뉴럴네트워크
- 에디션 앤 레이어 노말리제이션
한글로 쓰니 형편없어 보이긴 하지만 그냥 넘어가겠음.
일단 입력 문장이 모델에 입력되면 > 포지셔닝 인코딩을 통과 > 벡터화(각 단어의 위치정보가 포함)된 입력 문장이 들어옴.
이 벡터값은 트랜스포머의 인코더로 들어옴.
그러면 그림의 가장 좌측처럼 입력값이 하나는 바로 Add&Norm으로 가고, 하나는 3개로 나눠져서 Multi-head self attention 서브레이어로 들어감. 이 서브레이어를 통과하니 다시 하나의 출력값으로 변하고, 곧바로 Add&Norm으로 갔던 입력값과 멀티헤드셀프어텐션 서브레이어에서 나온 출력값이 더해지고 일반화됨. 이 값을 또 둘로 나눠서 하나는 다이렉트로 가고 하나는 Position-wise FFNN 서브레이어를 갔다가 또 합쳐짐. 이게 트랜스포머의 Encoder 끝임.
이제 하나씩 설명하겠음.
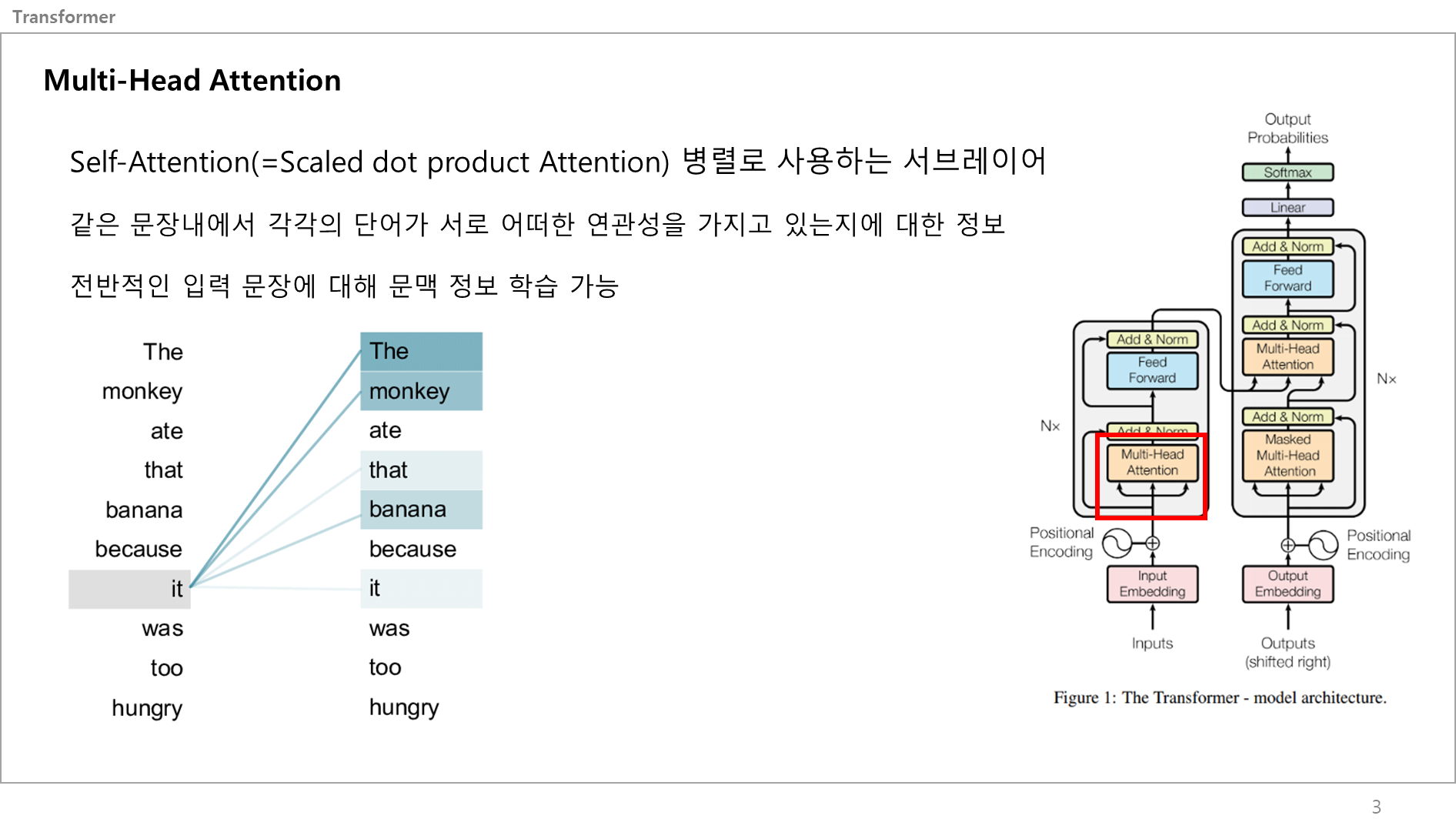
먼저 Attention이 뭔지부터 알아야함.
어텐션(Attention)이란 각 문장에서 각각의 단어가 서로 어떤 연관성을 가지고 있는지에 대한 정보인데, 쉽게말해서 특정 단어에 집중하는 거임. 어라? It이 뭘 뜻하는 거지? 아, The Monkey 혹은 that banana에 집중하고 있구나. 이런 느낌.
이 Attention 기술을 적용하면 전반적인 입력 문장에 대해 모델이 문맥 정보를 학습할 수 있음.
Transformer은 어텐션 기법을 사용하는데, 왜 앞에 Self-attention이라고 하냐면, 하나의 문장 내에서 어텐션을 취하고 있는거라서 앞에 셀프가 붙음. 즉, 각각의 문장간의 집중이 아닌, 하나의 문장 내에서 각 단어가 뭐에 집중하는지를 보는거임.
이런 셀프 어텐션은 다른말로 (Scaled dot product Attention)이라고 말함.
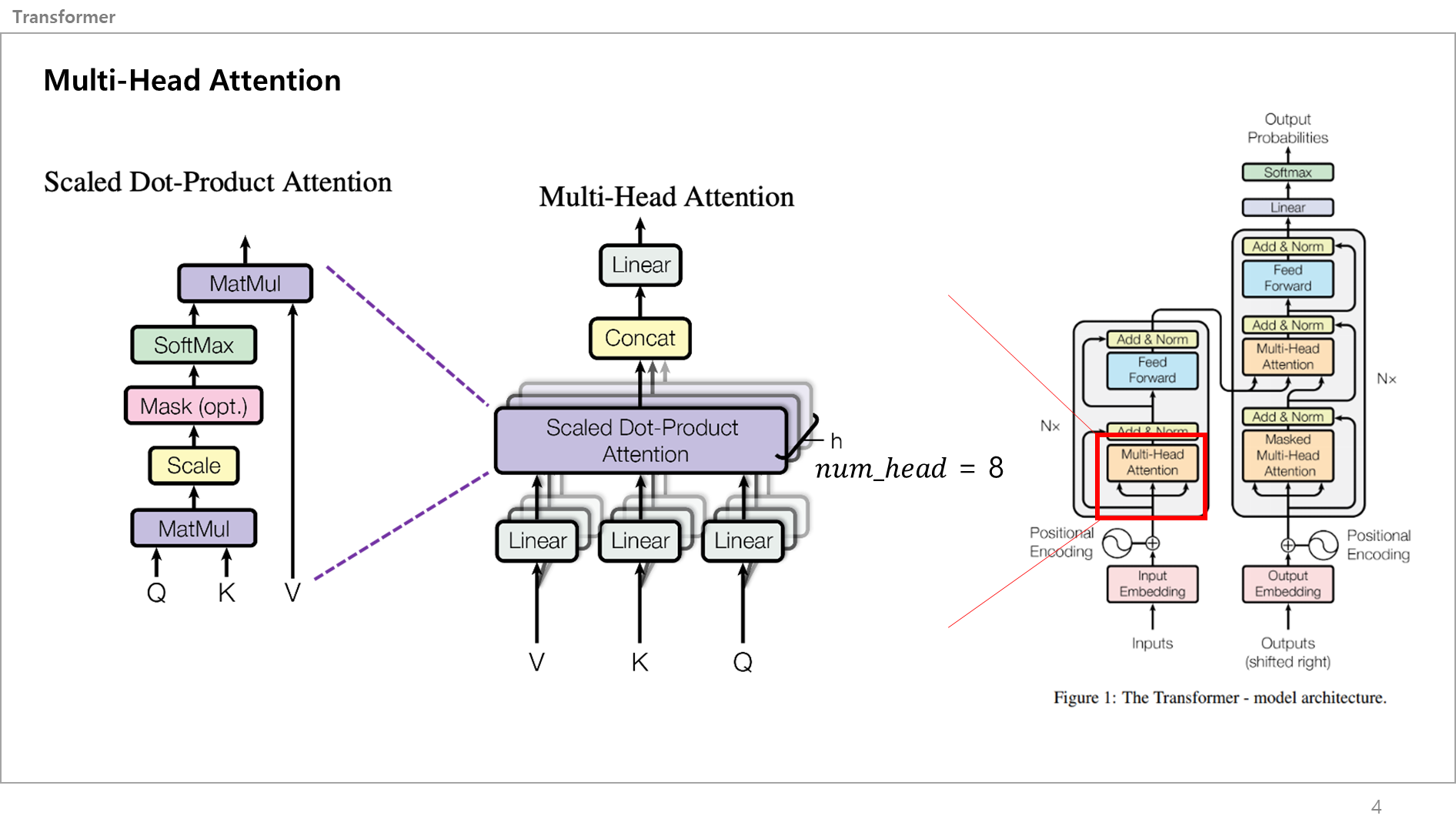
자, 오른쪽 그림과 같이 입력 문장이 벡터화 되고 가장 먼저 가는 서브레이어는 Multi-Head Attention 레이어임.
이를 크게보면 가운데 그림처럼 되고, 여기서 Scaled Dot product attention (=Self-Attention) 레이어를 확대해보면 좌측의 그림처럼 표현할 수 있음.
먼저 용어부터 간단히 설명할게요.
좌측 그림 상하단을 보면 MatMul이라고 있는데, 이건 Matrix Multiplication의 약자로 한국어는 "행렬곱셈"임.
Scale은 스케일링(Scailing)하는건데, 이게 행렬곱셈하면서 벡터값이 점점 커지는데 이게 그 위에 Softmax를 통과할때 문제가 됌. 이게 벡터값이 크면 출력값이 Gradient Vanishing(가중치 소실) 문제가 발생할 수 있기 때문에 저기 Scale 서브레이어에서는 Scale Factor라는 특수 값을 벡터에 곱해서 입력값을 작게만들어줌. 이러면 소프트맥스 함수 출력값이 안정적이게 됌.
이해안되었다면 이따 더 쉽게 설명할테니 일단 패스

자 각각의 서브레이어를 하나씩 자세하게 봐봅시다.
논문에서 모델의 입력차원은 512로 설정하였고, num_head는 8로 정했어요.
이말이 뭐냐, 쉽게 설명하자면 입력된 문장에서 하나의 단어를 하나의 벡터라고 생각했을 때, 각 벡터의 길이가 512라는 얘기입니다. 즉, Student라는 단어는 512개의 길이를 가진 벡터로 치환된다 생각하면 굳.
num_head는 각각의 이 셀프 어텐션을 총 몇개를 병렬로 계산할거냐 라는 값인데, 논문에서는 한번에 8개가 동시에 병렬적으로 계산되도록 설정하였음.
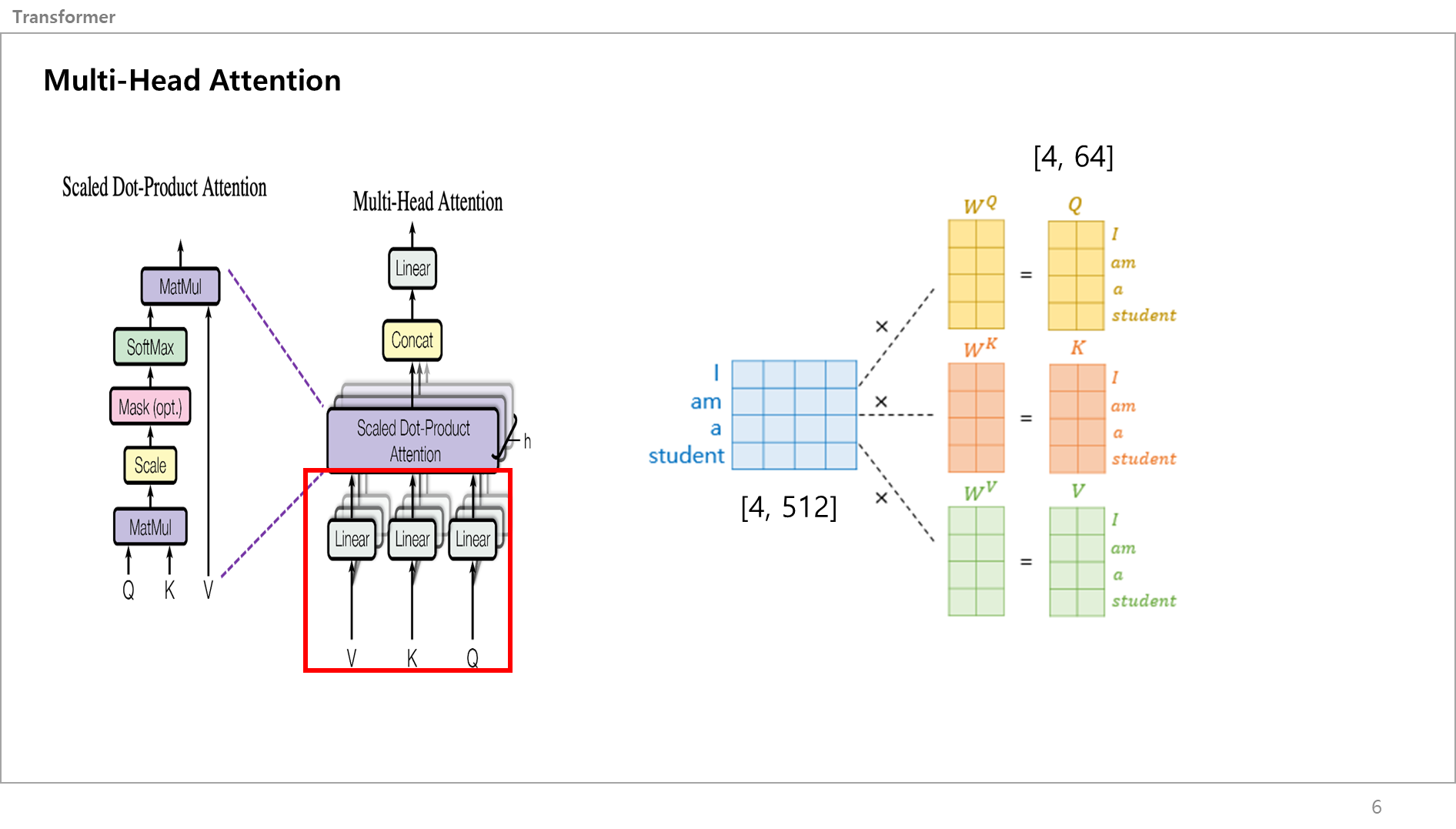
512 차원의 단어벡터를 [모델의 dimension, 모델의 dimension/numhead]값인 [512,512/8] = [512, 64]의 크기를 가지는 가중치 행렬을 만들어서 이를 곱해줘서 Q,K,V를 만듬.
이게 다른 설명같은데서 보면 가중치 행렬을 원래 값에 곱해서 만든다 정도로만 설명하는데 더 쉽게 이해할려면 다음과 같음.
그림 아래에 있는 코드처럼, 512차원의 입력데이터를 넣으면 64차원으로 나오도록 하는 것임.
케라스 텐서플로우에서는 일반적인 Dense층으로 생각하면됌.
각각의 Linear 레이어를 만들어서 64차원의 Query, Key, Value 벡터값을 만드는게 끝임.
그림을 예시로 보면 [1,512] 짜리 벡터 (=Student) 가 각 레이어 통과해서 서로 다른 [1,64] 크기를 가지는 벡터가 3개 만들어지는거임.
방금 전에는 1개의 단어 벡터에 대해서 얘기한거고, 실제 멀티헤드어텐션은 모든 입력에 대해 병렬적으로 동시에 진행함.
똑같은 원리로 하나의 입력 문장에 대해 512차원을 각각 다른 64차원 벡터로 나오게 하면 이 서브레이어의 역할은 끝임.
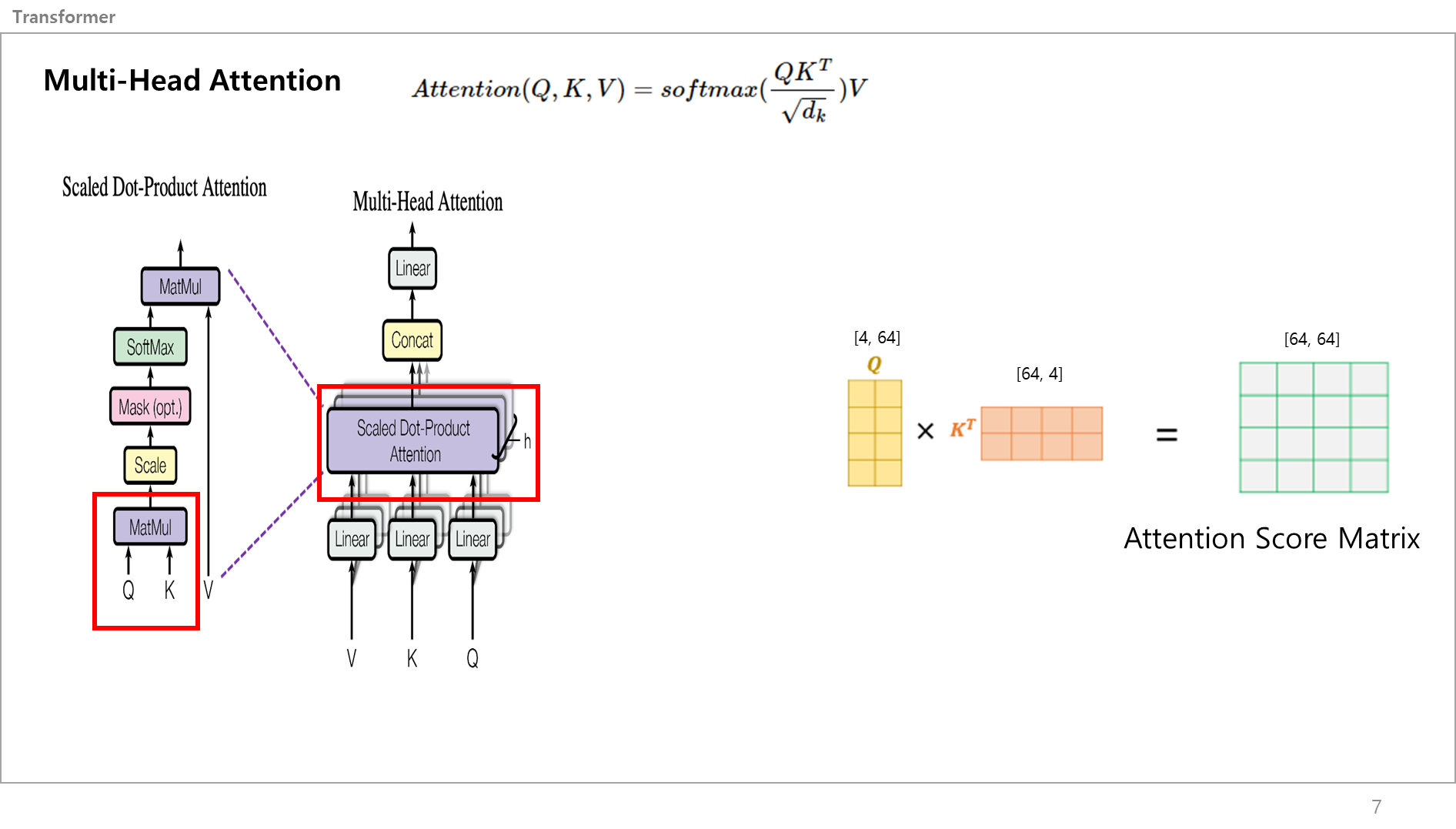
Q,K,V가 만들어졌으면 이 값들은 Scaled Dot Product Attention, 즉 Self Attention 레이어로 들어감.
이 셀프어텐션 레이어는 왼쪽의 그림처럼 구성되어 있음.
먼저 Q,K값이 MatMul(행렬곱셈)을 진행함.
오른쪽 그림 보면 아까 만든 Q와 K를 행렬곱해서 [64,64] 크기를 같은 어텐션 스코어 매트릭스를 만듬
그림만 보면 [2,4] * [4,2] = [4,4]이라서 헷갈린다고 생각할 수 있는데,
아까 예시였던 4개의 단어 I am a student에서 각각의 단어는 512개의 길이를 가지는 벡터였고, Q,K,V에서 64로 줄였으니 하나의 단어는 지금 길이가 64인 벡터라고 생각하면됌.
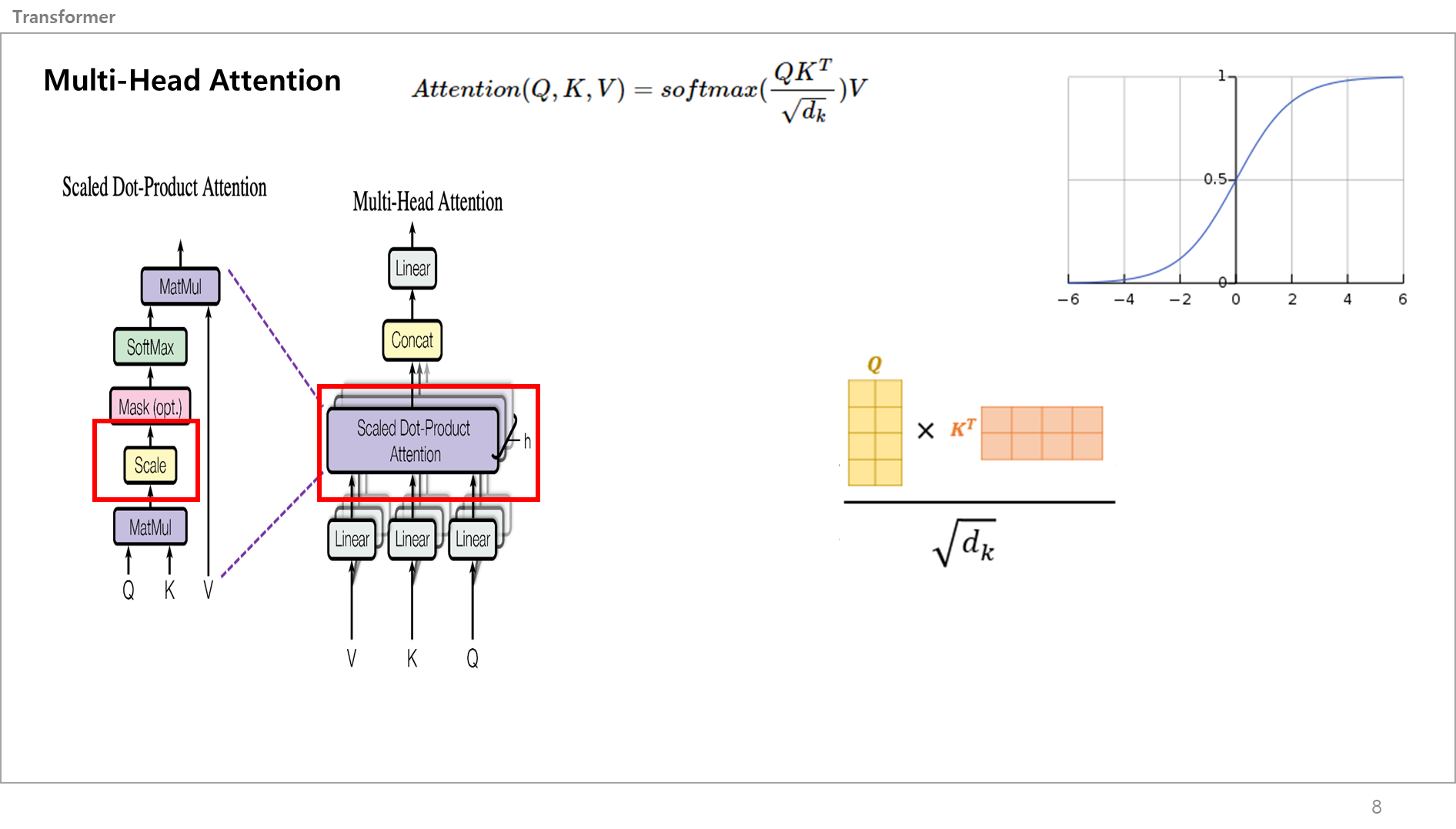
그런다음 이 어텐션 스코어 메트릭스를 스케일링을 함.
이유는 아까 말한 것처럼 > 행렬곱셈하면서 벡터값이 커지는데 Softmax를 취할때 백터값이 크면 출력값이 0 or 1값이 많아지기 떄문에 Gradient Vanishing(가중치 소실) or Exploding(폭발) 문제가 발생할 수 있고, Scale Factor를 곱해서 입력값을 작게만들어서 Softmax 함수의 출력 값을 안정적으로 만들어줌.
저 위의 그래프가 Softmax function인데 보다싶이 입력값이 계속 곱해지면서 값이 커지면 1에 근접한 출력값만 나오고 작아지면 0에 근접한 출력값이 나오겠죠?
그래서 Q랑 K랑 행렬곱 한다음에 나눠주는거임.
마스크는 건너 뛰었는데, 옆에 옵션이라고 붙어있는데, padding은 보통 Max len을 정해뒀을떄 입력 문장이 이보다 작을 때 최대 길이를 맞춰주기 위해 아주 작은 음수값을 주는 것임.
굉장히 작은 음수값을 주게되면 소프트 맥스를 지나면 0에 가깝게 되기 때문에 어텐션 학습이 안됌.
현재 예시에서는 패딩이 필요없기에 넘어갑니다.
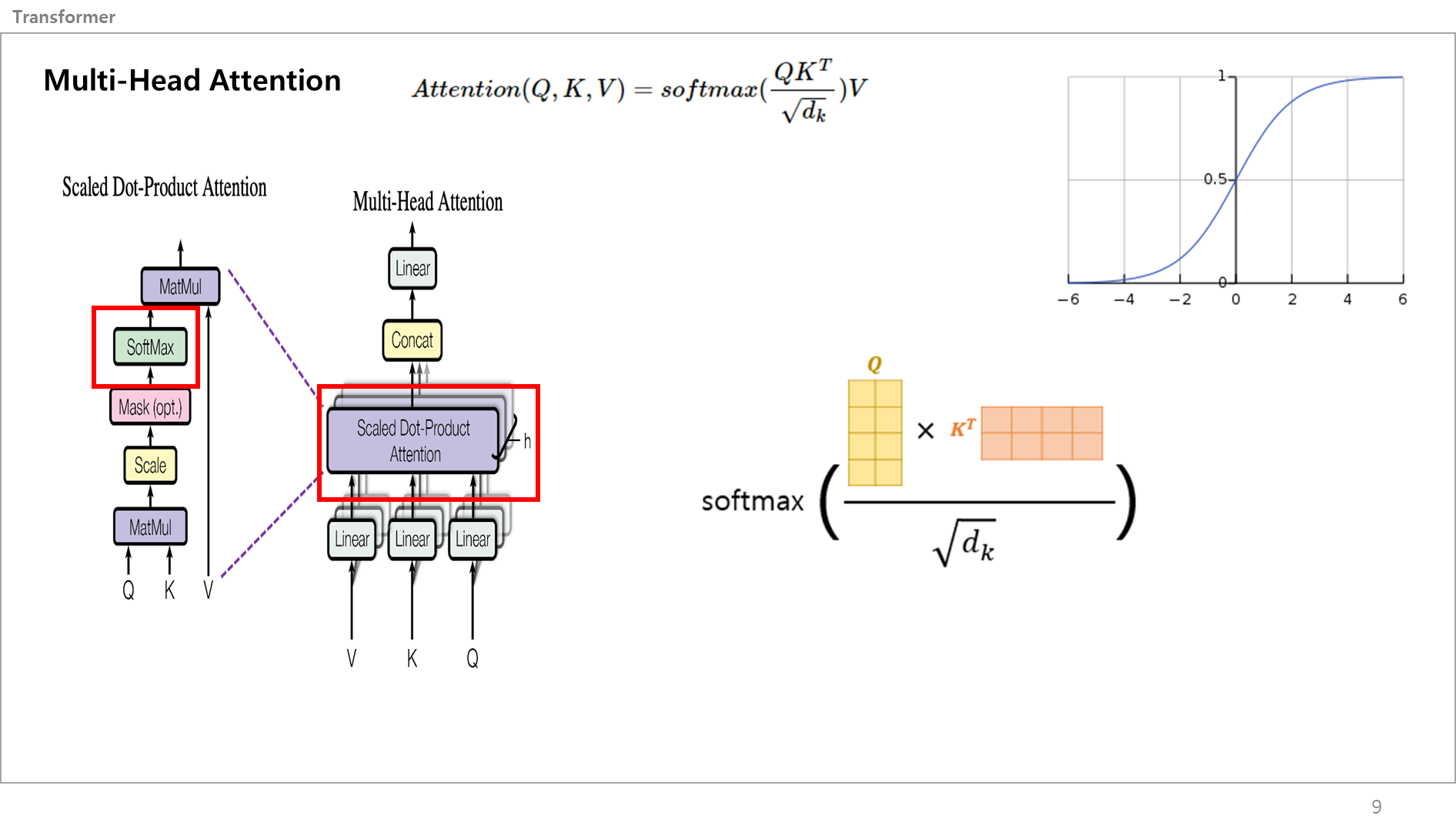
전단계에서 스케일링 한 값을 소프트 맥스 레이어에 넣어서 총 합이 1인 확률값 매트릭스, 스코어 메트릭스로 만들어줌.
즉, [0.2, 0.1, 0.3, 0.4] 처럼 만드는거임.
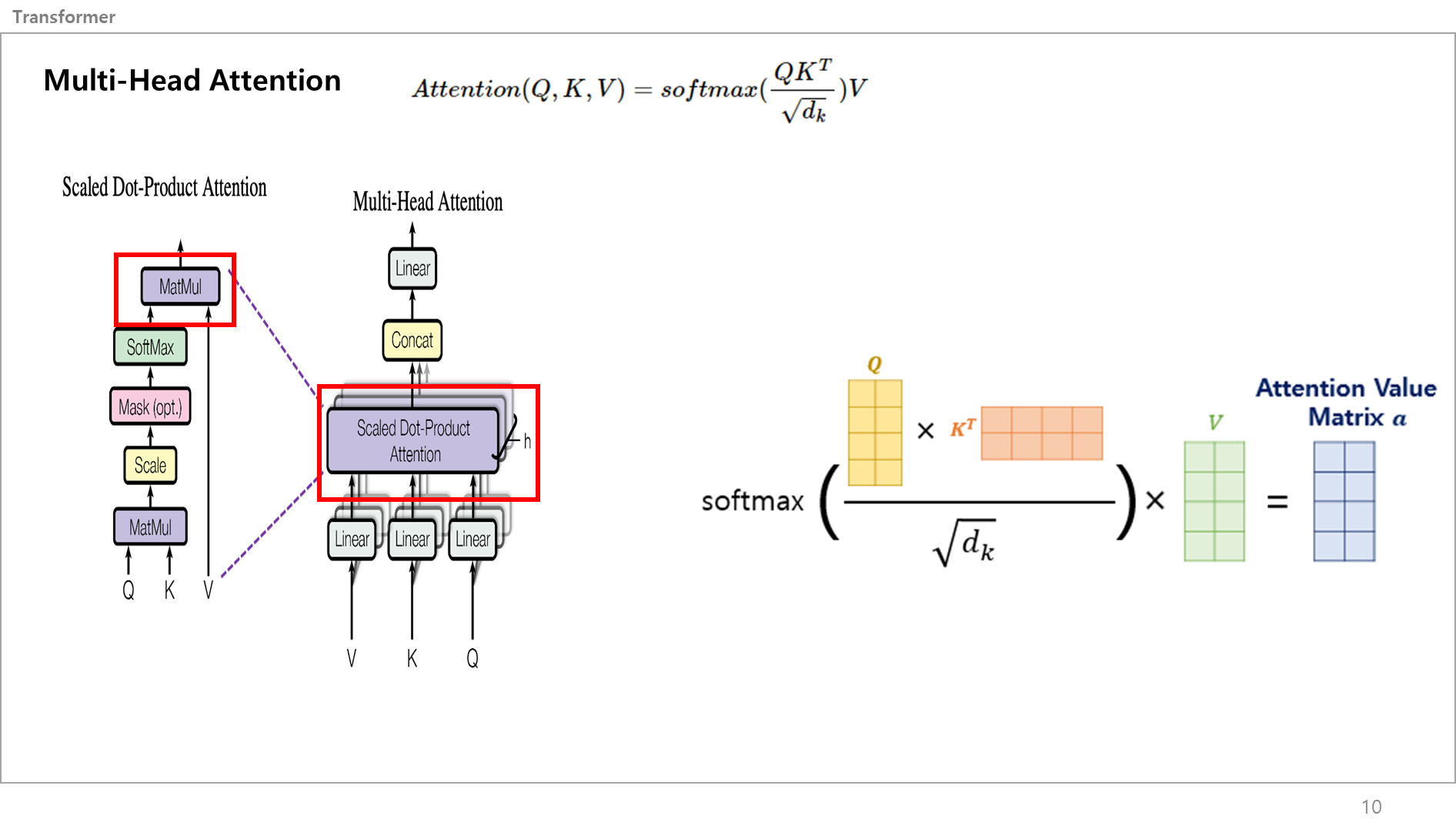
그러고나서 Score Metrix를 적용하기 위해 Value 벡터값과 곱해서 Attention Value Metrix을 만듬.
이게 그림 맨위에있는 어텐션 수식을 전부 설명한거임.
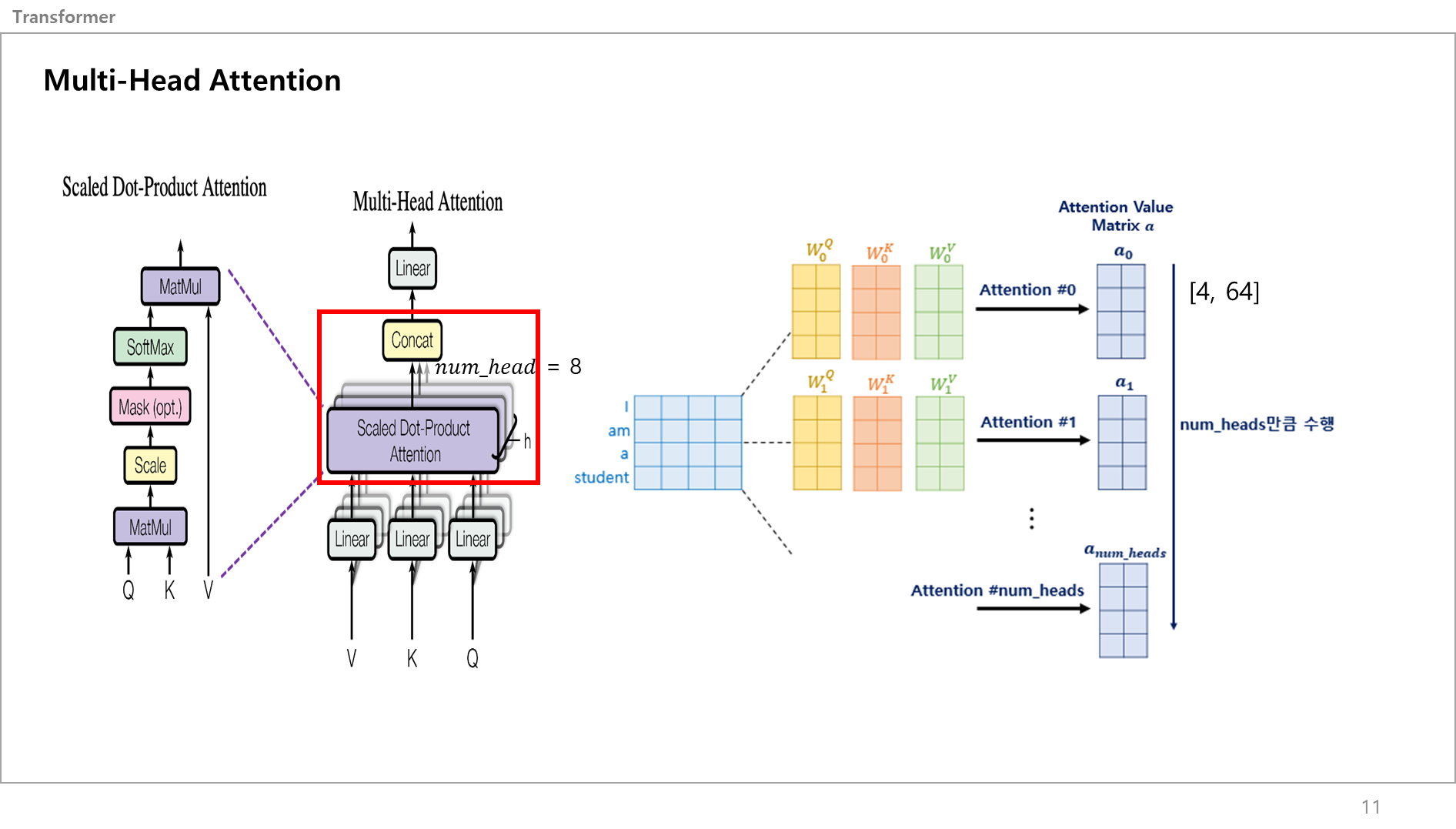
스케일 닷 프로덕트 어텐션은 이렇게 끝이 났지만, 그림에 h라고 표시된 Num Head 수만큼 병렬적으로 동시에 진행하기 떄문에 총 8개의 어텐션 벨류 메트릭스가 나옴.
이를 Concat을 함.
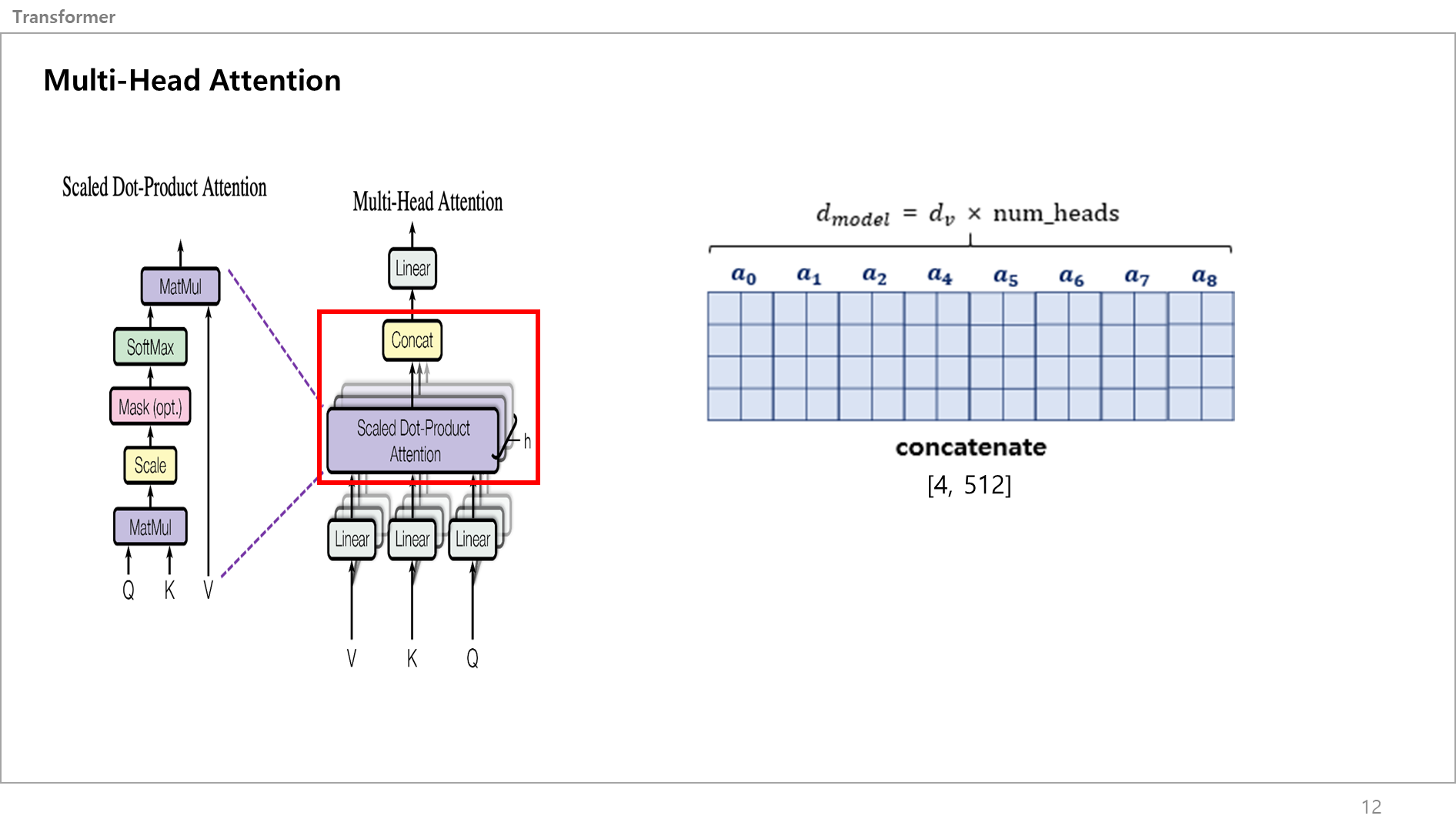
Concat을 하면 [4,64]였던 어텐션 벨류 메트릭스가 8개가 붙어 [4,512]의 크기를 가지는 하나의 텐서값을 얻음.
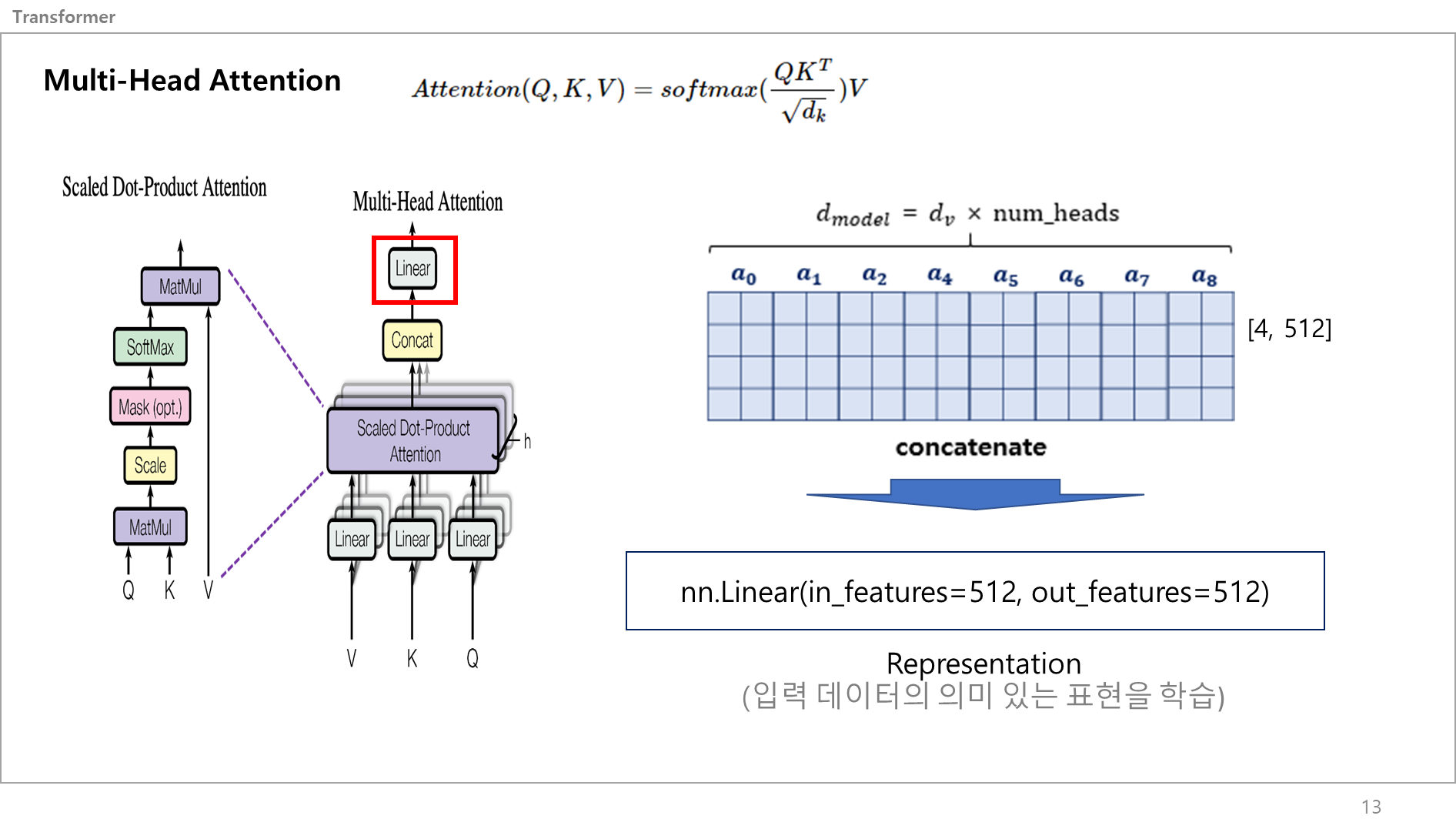
이 값을 리니어 레이어에 그대로 넣어서 Representation을 함.
딥러닝에서 "Representation"란, 입력 데이터의 의미 있는 표현을 학습하는 것을 의미함.
입력 데이터를 신경망에 주입하면, 신경망이 이를 분석하여 각 입력에 대한 적절한 표현을 추출하는 것임
아까랑 똑같이 입출력 크기가 같은 Linear 레이어에 벡터값을 넣는거임. (텐서플로로 설명하자면 입출력크기가 같은 Dense 레이어)이 값을 리니어 레이어에 그대로 넣어서 Representation을 함.
딥러닝에서 "Representation"란, 입력 데이터의 의미 있는 표현을 학습하는 것을 의미함.
입력 데이터를 신경망에 주입하면, 신경망이 이를 분석하여 각 입력에 대한 적절한 표현을 추출하는 것임
아까랑 똑같이 입출력 크기가 같은 Linear 레이어에 벡터값을 넣는거임. (텐서플로로 설명하자면 입출력크기가 같은 Dense 레이어)
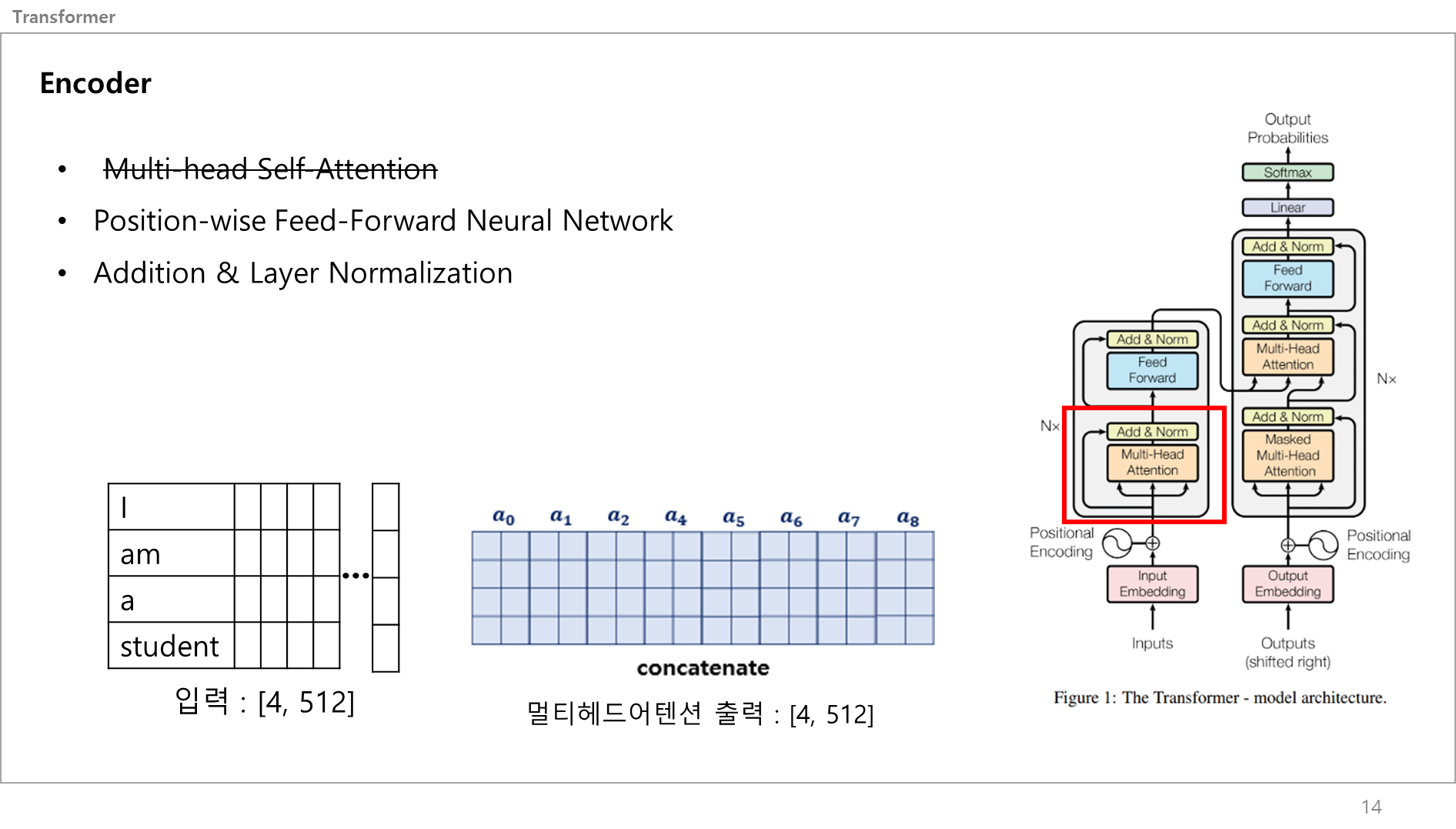
멀티헤드 어텐션은 끝났고,
그림을 보면 입력문장 임베딩값과 멀티헤드어텐션에서 나온 출력값이 Addition & Layer Normalization로 감.
일단 입력과 멀티헤드어텐션 출력은 동일한 차원을 갖고 있음.
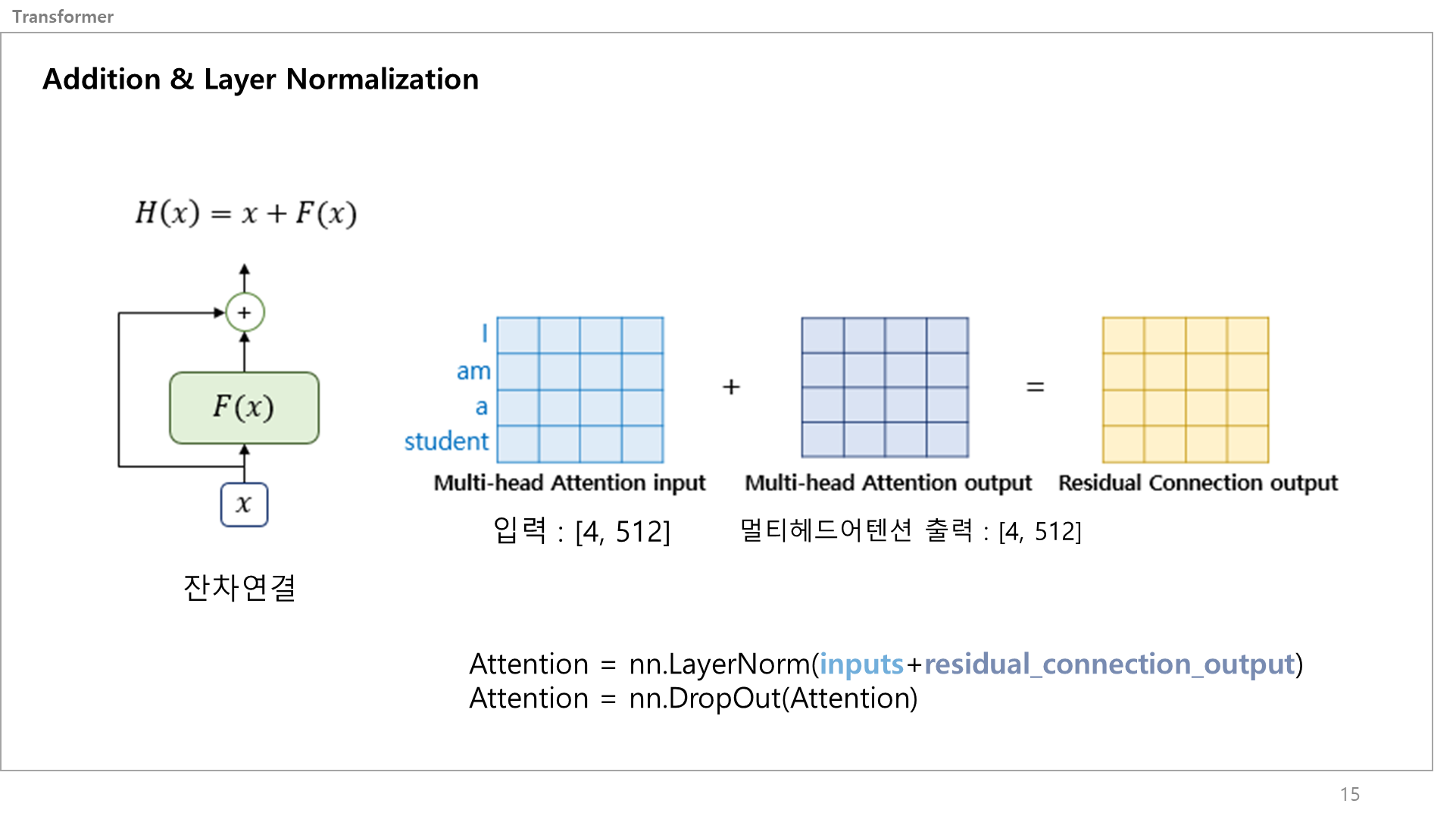
Addition & Layer Normalization은 말그대로 더하고 레이어 노말리제이션을 통해 일반화 하는 서브 레이어임.
입출력이 같은 차원을 가지니 더할 수 있음.
잔차 연결(residual connection)은 딥러닝 네트워크에서 발생할 수 있는 가중치 손실(gradient vanishing) 문제를 해결하고, 학습 속도를 향상시키는 장점이 있음.
네트워크가 깊어질수록 역전파 하면 그래디언트 값이 작아져 사라질 수 있기 때문에, 서브레이어에 들어가기 전의 값을 추력값과 더해서 완화시킴.
이 서브레이어를 코드로 설명하자면 레지듀얼 커넥션 아웃풋을 레이어 노말리제이션 하고 드랍아웃하는 게 끝임
참고로 왜 Layer Norm을 했냐? Batch Norm은?? 라고 물어본다면,
Batch Norm과 동일하지만 적용되는 Dimension이 다름. 자연어는 이미지와 달리 입력 시퀀스가 매번 다르기에 Padding을 넣어주는데, 이러한 특성때문에 Batch normalization으로 Layer Norm이 적합함. 더 자세하고 깊게 배울려면 검색 ㄱㄱ
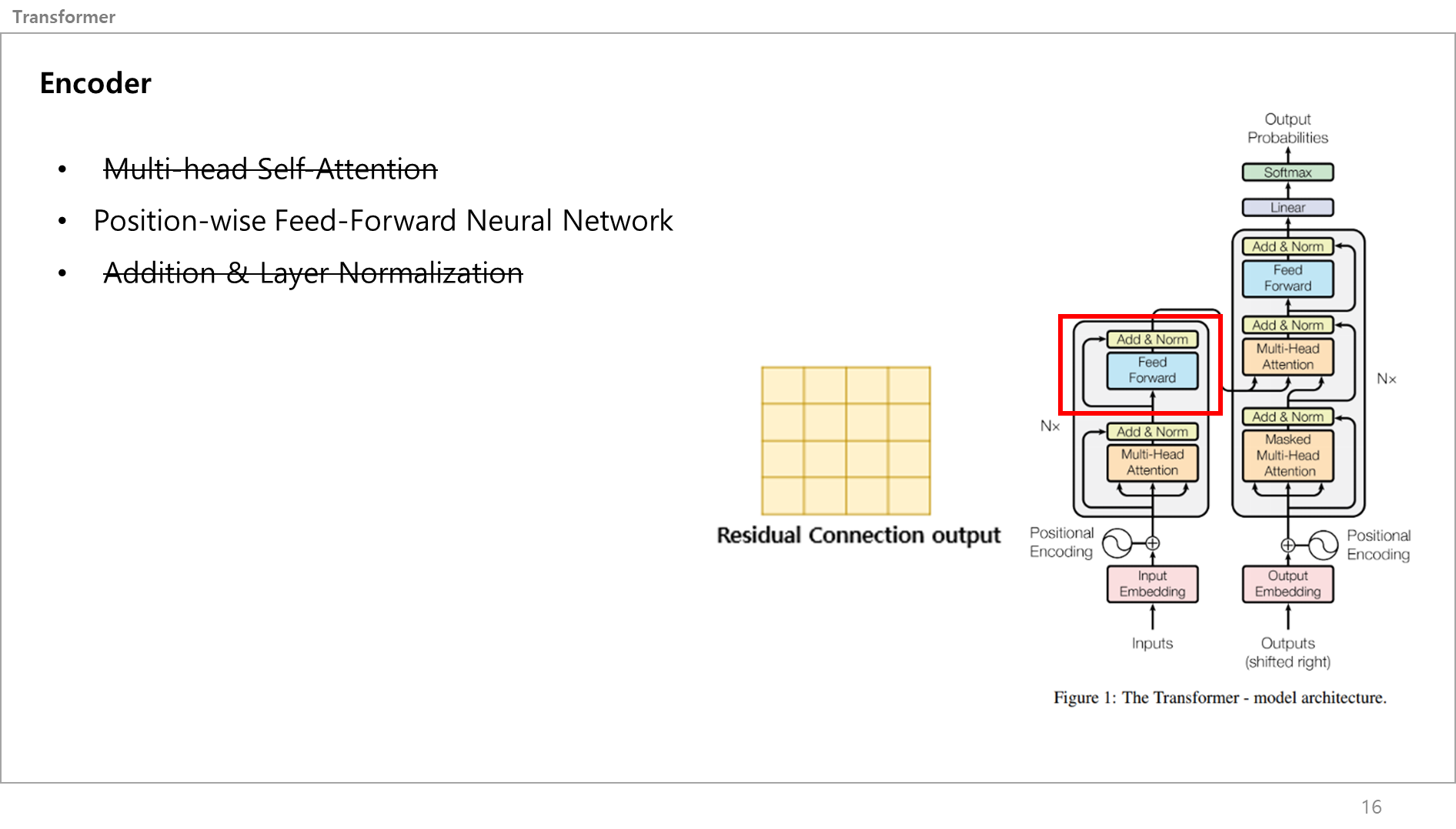
레지듀얼 커넥션 아웃풋 값은 똑같이 Addition & Layer Normalization과 Feed Forward로 감.
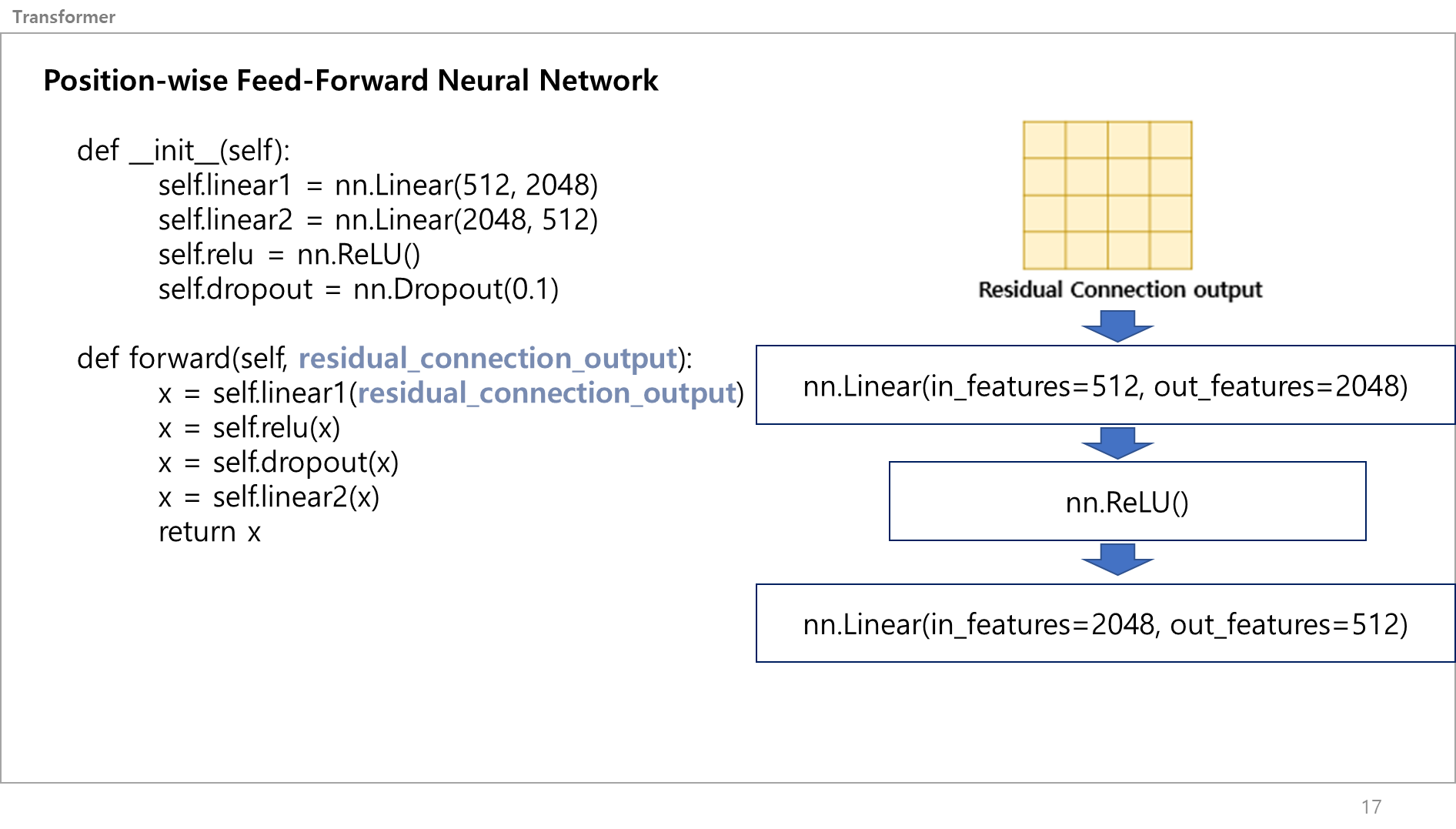
여긴 코드로 설명하는게 더 쉬워보임.
그 벡터값이 지금 512차원이니, 이를 4배 늘렸다가 다시 4배 줄이는 레이어임.
왜 늘렸다 줄여! 라고 하면,
4배 늘린다 : 데이터를 더 넓은 공간에서 표현해본다.
4배 줄인다: 넓은 공간에서 표현한 데이터 중에 더 중요한 특징들을 선택하고 학습하도록 한다.
즉, Representation 하는거임.
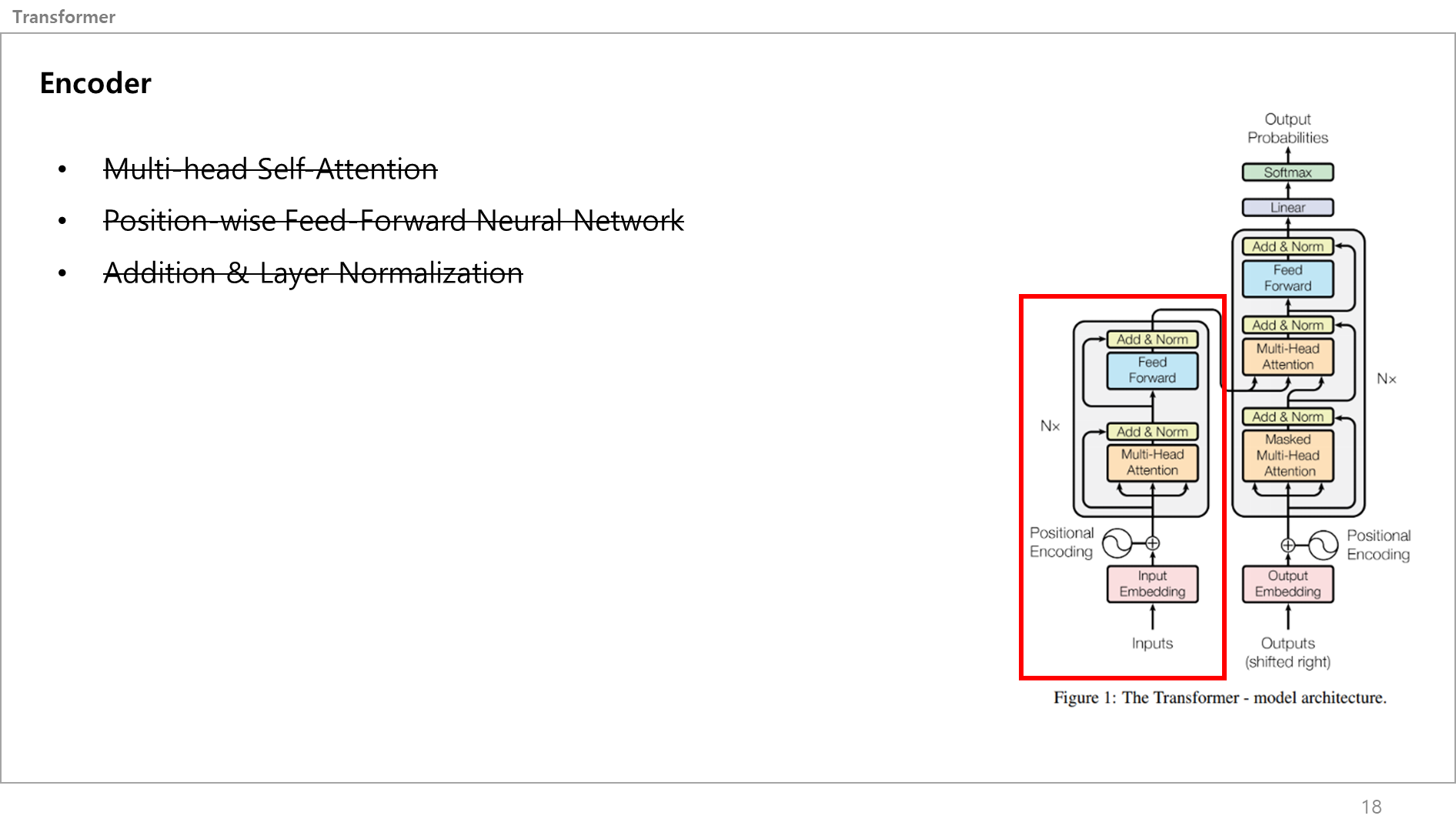
이러면 트랜스포머의 인코더 부분 설명 끝임!
이 포스팅이 도움이 되었으면 좋겠습니다.
다시 연구하러 가겠습니다
오늘은 트랜스포머의 인코더 부분을 쉽게 설명하고자함.
많은 사람들이 트랜스포머의 기법에 대해서 물어보면 "Self-attention 기법 사용... 특정 단어에 포커싱.." 혹은 "Q,K,V 사용해서...조합해서 가중치주는 기법..." 정도로만 대답함.
실제 어떤 식으로 돌아가는지 쉽고 자세하게 설명하기 위해 본 포스팅을 진행함.
애매하게 아는 분 환영
트랜스포머의 인코더 레이어는 그림에서 보이다 싶이 크게 3가지로 나눠볼 수 있음.
- 멀티헤드 셀프어텐션
- 포지셔닝 와이즈 피드포워드 뉴럴네트워크
- 에디션 앤 레이어 노말리제이션
한글로 쓰니 형편없어 보이긴 하지만 그냥 넘어가겠음.
일단 입력 문장이 모델에 입력되면 > 포지셔닝 인코딩을 통과 > 벡터화(각 단어의 위치정보가 포함)된 입력 문장이 들어옴.
이 벡터값은 트랜스포머의 인코더로 들어옴.
그러면 그림의 가장 좌측처럼 입력값이 하나는 바로 Add&Norm으로 가고, 하나는 3개로 나눠져서 Multi-head self attention 서브레이어로 들어감. 이 서브레이어를 통과하니 다시 하나의 출력값으로 변하고, 곧바로 Add&Norm으로 갔던 입력값과 멀티헤드셀프어텐션 서브레이어에서 나온 출력값이 더해지고 일반화됨. 이 값을 또 둘로 나눠서 하나는 다이렉트로 가고 하나는 Position-wise FFNN 서브레이어를 갔다가 또 합쳐짐. 이게 트랜스포머의 Encoder 끝임.
이제 하나씩 설명하겠음.
먼저 Attention이 뭔지부터 알아야함.
어텐션(Attention)이란 각 문장에서 각각의 단어가 서로 어떤 연관성을 가지고 있는지에 대한 정보인데, 쉽게말해서 특정 단어에 집중하는 거임. 어라? It이 뭘 뜻하는 거지? 아, The Monkey 혹은 that banana에 집중하고 있구나. 이런 느낌.
이 Attention 기술을 적용하면 전반적인 입력 문장에 대해 모델이 문맥 정보를 학습할 수 있음.
Transformer은 어텐션 기법을 사용하는데, 왜 앞에 Self-attention이라고 하냐면, 하나의 문장 내에서 어텐션을 취하고 있는거라서 앞에 셀프가 붙음. 즉, 각각의 문장간의 집중이 아닌, 하나의 문장 내에서 각 단어가 뭐에 집중하는지를 보는거임.
이런 셀프 어텐션은 다른말로 (Scaled dot product Attention)이라고 말함.
자, 오른쪽 그림과 같이 입력 문장이 벡터화 되고 가장 먼저 가는 서브레이어는 Multi-Head Attention 레이어임.
이를 크게보면 가운데 그림처럼 되고, 여기서 Scaled Dot product attention (=Self-Attention) 레이어를 확대해보면 좌측의 그림처럼 표현할 수 있음.
먼저 용어부터 간단히 설명할게요.
좌측 그림 상하단을 보면 MatMul이라고 있는데, 이건 Matrix Multiplication의 약자로 한국어는 "행렬곱셈"임.
Scale은 스케일링(Scailing)하는건데, 이게 행렬곱셈하면서 벡터값이 점점 커지는데 이게 그 위에 Softmax를 통과할때 문제가 됌. 이게 벡터값이 크면 출력값이 Gradient Vanishing(가중치 소실) 문제가 발생할 수 있기 때문에 저기 Scale 서브레이어에서는 Scale Factor라는 특수 값을 벡터에 곱해서 입력값을 작게만들어줌. 이러면 소프트맥스 함수 출력값이 안정적이게 됌.
이해안되었다면 이따 더 쉽게 설명할테니 일단 패스
자 각각의 서브레이어를 하나씩 자세하게 봐봅시다.
논문에서 모델의 입력차원은 512로 설정하였고, num_head는 8로 정했어요.
이말이 뭐냐, 쉽게 설명하자면 입력된 문장에서 하나의 단어를 하나의 벡터라고 생각했을 때, 각 벡터의 길이가 512라는 얘기입니다. 즉, Student라는 단어는 512개의 길이를 가진 벡터로 치환된다 생각하면 굳.
num_head는 각각의 이 셀프 어텐션을 총 몇개를 병렬로 계산할거냐 라는 값인데, 논문에서는 한번에 8개가 동시에 병렬적으로 계산되도록 설정하였음.
512 차원의 단어벡터를 [모델의 dimension, 모델의 dimension/numhead]값인 [512,512/8] = [512, 64]의 크기를 가지는 가중치 행렬을 만들어서 이를 곱해줘서 Q,K,V를 만듬.
이게 다른 설명같은데서 보면 가중치 행렬을 원래 값에 곱해서 만든다 정도로만 설명하는데 더 쉽게 이해할려면 다음과 같음.
그림 아래에 있는 코드처럼, 512차원의 입력데이터를 넣으면 64차원으로 나오도록 하는 것임.
케라스 텐서플로우에서는 일반적인 Dense층으로 생각하면됌.
각각의 Linear 레이어를 만들어서 64차원의 Query, Key, Value 벡터값을 만드는게 끝임.
그림을 예시로 보면 [1,512] 짜리 벡터 (=Student) 가 각 레이어 통과해서 서로 다른 [1,64] 크기를 가지는 벡터가 3개 만들어지는거임.
방금 전에는 1개의 단어 벡터에 대해서 얘기한거고, 실제 멀티헤드어텐션은 모든 입력에 대해 병렬적으로 동시에 진행함.
똑같은 원리로 하나의 입력 문장에 대해 512차원을 각각 다른 64차원 벡터로 나오게 하면 이 서브레이어의 역할은 끝임.
Q,K,V가 만들어졌으면 이 값들은 Scaled Dot Product Attention, 즉 Self Attention 레이어로 들어감.
이 셀프어텐션 레이어는 왼쪽의 그림처럼 구성되어 있음.
먼저 Q,K값이 MatMul(행렬곱셈)을 진행함.
오른쪽 그림 보면 아까 만든 Q와 K를 행렬곱해서 [64,64] 크기를 같은 어텐션 스코어 매트릭스를 만듬
그림만 보면 [2,4] * [4,2] = [4,4]이라서 헷갈린다고 생각할 수 있는데,
아까 예시였던 4개의 단어 I am a student에서 각각의 단어는 512개의 길이를 가지는 벡터였고, Q,K,V에서 64로 줄였으니 하나의 단어는 지금 길이가 64인 벡터라고 생각하면됌.
그런다음 이 어텐션 스코어 메트릭스를 스케일링을 함.
이유는 아까 말한 것처럼 > 행렬곱셈하면서 벡터값이 커지는데 Softmax를 취할때 백터값이 크면 출력값이 0 or 1값이 많아지기 떄문에 Gradient Vanishing(가중치 소실) or Exploding(폭발) 문제가 발생할 수 있고, Scale Factor를 곱해서 입력값을 작게만들어서 Softmax 함수의 출력 값을 안정적으로 만들어줌.
저 위의 그래프가 Softmax function인데 보다싶이 입력값이 계속 곱해지면서 값이 커지면 1에 근접한 출력값만 나오고 작아지면 0에 근접한 출력값이 나오겠죠?
그래서 Q랑 K랑 행렬곱 한다음에 나눠주는거임.
마스크는 건너 뛰었는데, 옆에 옵션이라고 붙어있는데, padding은 보통 Max len을 정해뒀을떄 입력 문장이 이보다 작을 때 최대 길이를 맞춰주기 위해 아주 작은 음수값을 주는 것임.
굉장히 작은 음수값을 주게되면 소프트 맥스를 지나면 0에 가깝게 되기 때문에 어텐션 학습이 안됌.
현재 예시에서는 패딩이 필요없기에 넘어갑니다.
전단계에서 스케일링 한 값을 소프트 맥스 레이어에 넣어서 총 합이 1인 확률값 매트릭스, 스코어 메트릭스로 만들어줌.
즉, [0.2, 0.1, 0.3, 0.4] 처럼 만드는거임.
그러고나서 Score Metrix를 적용하기 위해 Value 벡터값과 곱해서 Attention Value Metrix을 만듬.
이게 그림 맨위에있는 어텐션 수식을 전부 설명한거임.
스케일 닷 프로덕트 어텐션은 이렇게 끝이 났지만, 그림에 h라고 표시된 Num Head 수만큼 병렬적으로 동시에 진행하기 떄문에 총 8개의 어텐션 벨류 메트릭스가 나옴.
이를 Concat을 함.
Concat을 하면 [4,64]였던 어텐션 벨류 메트릭스가 8개가 붙어 [4,512]의 크기를 가지는 하나의 텐서값을 얻음.
이 값을 리니어 레이어에 그대로 넣어서 Representation을 함.
딥러닝에서 "Representation"란, 입력 데이터의 의미 있는 표현을 학습하는 것을 의미함.
입력 데이터를 신경망에 주입하면, 신경망이 이를 분석하여 각 입력에 대한 적절한 표현을 추출하는 것임
아까랑 똑같이 입출력 크기가 같은 Linear 레이어에 벡터값을 넣는거임. (텐서플로로 설명하자면 입출력크기가 같은 Dense 레이어)이 값을 리니어 레이어에 그대로 넣어서 Representation을 함.
딥러닝에서 "Representation"란, 입력 데이터의 의미 있는 표현을 학습하는 것을 의미함.
입력 데이터를 신경망에 주입하면, 신경망이 이를 분석하여 각 입력에 대한 적절한 표현을 추출하는 것임
아까랑 똑같이 입출력 크기가 같은 Linear 레이어에 벡터값을 넣는거임. (텐서플로로 설명하자면 입출력크기가 같은 Dense 레이어)
멀티헤드 어텐션은 끝났고,
그림을 보면 입력문장 임베딩값과 멀티헤드어텐션에서 나온 출력값이 Addition & Layer Normalization로 감.
일단 입력과 멀티헤드어텐션 출력은 동일한 차원을 갖고 있음.
Addition & Layer Normalization은 말그대로 더하고 레이어 노말리제이션을 통해 일반화 하는 서브 레이어임.
입출력이 같은 차원을 가지니 더할 수 있음.
잔차 연결(residual connection)은 딥러닝 네트워크에서 발생할 수 있는 가중치 손실(gradient vanishing) 문제를 해결하고, 학습 속도를 향상시키는 장점이 있음.
네트워크가 깊어질수록 역전파 하면 그래디언트 값이 작아져 사라질 수 있기 때문에, 서브레이어에 들어가기 전의 값을 추력값과 더해서 완화시킴.
이 서브레이어를 코드로 설명하자면 레지듀얼 커넥션 아웃풋을 레이어 노말리제이션 하고 드랍아웃하는 게 끝임
참고로 왜 Layer Norm을 했냐? Batch Norm은?? 라고 물어본다면,
Batch Norm과 동일하지만 적용되는 Dimension이 다름. 자연어는 이미지와 달리 입력 시퀀스가 매번 다르기에 Padding을 넣어주는데, 이러한 특성때문에 Batch normalization으로 Layer Norm이 적합함. 더 자세하고 깊게 배울려면 검색 ㄱㄱ
레지듀얼 커넥션 아웃풋 값은 똑같이 Addition & Layer Normalization과 Feed Forward로 감.
여긴 코드로 설명하는게 더 쉬워보임.
그 벡터값이 지금 512차원이니, 이를 4배 늘렸다가 다시 4배 줄이는 레이어임.
왜 늘렸다 줄여! 라고 하면,
4배 늘린다 : 데이터를 더 넓은 공간에서 표현해본다.
4배 줄인다: 넓은 공간에서 표현한 데이터 중에 더 중요한 특징들을 선택하고 학습하도록 한다.
즉, Representation 하는거임.
이러면 트랜스포머의 인코더 부분 설명 끝임!
이 포스팅이 도움이 되었으면 좋겠습니다.
다시 연구하러 가겠습니다