자연어 논문의 흐름도
이전까지 자연어처리는 기계학습에서 RNN의 등장으로인해 점차 딥러닝으로 들어가게 되었음.
RNN 순환신경망에서 vanishing gradient 문제가 있어서, 기억shell을 추가한 LSTM이 나왔으며, 그뒤로 GRU도 쓰고 하다가 트랜스포머가 나온 뒤로부터 얘가 이전까지의 성능을 다 이겨버려서 자연어처리의 흐름은 트랜스포머 모델을 기반으로 한 연구가 많아졌음.
- Attention Is All You Need
- Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems 30 (2017).
- 어텐션 기법 소개 → 트랜스포머 모델 On.
- NLP 분야에서 전설의 시작
- https://arxiv.org/pdf/1706.03762.pdf
어텐션 기법이 발표되면서 NLP 분야에서는 기존 RNN, CNN 기반의 모델들이 아닌, 어텐션기법을 사용하는 트랜스포머 기반의 모델들에 대한 연구가 시작됨. 그렇게 나온 것이 BERT와 GPT.
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- Devlin, Jacob, et al. "Bert: Pre-training of deep bidirectional transformers for language understanding." arXiv preprint arXiv:1810.04805 (2018).
- 트랜스포머의 인코더를 활용한 모델 → MASK 씌워서 학습한 전이학습언어모델
- 양방향 학습이라는 점에서 NLU에 띄어남
- https://arxiv.org/pdf/1810.04805.pdf
- Improving language understanding by generative pre-training
- Radford, Alec, et al. "Improving language understanding by generative pre-training." (2018).
- GPT-1 모델 소개
- 대부분 딥러닝 학습은 labeled된 데이터를 활용한 지도학습을 활용하는데, 많은 자원 부족으로 많은 범위에 대한 활용에 제약이 생김. 따라서 원본 그대로의 텍스트를 활용하여 unsupervised learning(비지도 학습)을 통해 학습할 수 있는 모델이 필요함.
- a) 어떤 optimization objective가 전이학습에 효과적인 representation을 배우는 데 효과적인지 알 수 없다.
- b) 모델에서 학습된 표현(representation)을 다른 NLP task로 transfer하는데 가장 효율적인 방법이 정해지지 않았다.
- 이러한 원본 텍스트를 사용한 학습에 대한 문제점, pretraining에서 고려해야할 어려운 문제들을 다루면서 단방향 학습 기반의 GPT 모델이 나옴
- https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf
이때까지만해도 BERT > GPT-1 이였음.
서로 사전학습 기법 다르고, BERT가 다양한 Task에 더 뛰어난 결과를 냈음.
GPT는 언어 생성에 더 유리하고, LSTM대신 GPT도 Transformer 구조 활용해서 언어 모델링함.
- ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
- Lan, Zhenzhong, et al. "Albert: A lite bert for self-supervised learning of language representations." arXiv preprint arXiv:1909.11942 (2019).
- https://arxiv.org/pdf/1909.11942.pdf
- RoBERTa: A Robustly Optimized BERT Pretraining Approach
- Liu, Yinhan, et al. "Roberta: A robustly optimized bert pretraining approach." arXiv preprint arXiv:1907.11692 (2019).
- Language Models are Unsupervised Multitask Learners
- Radford, Alec, et al. "Language models are unsupervised multitask learners." OpenAI blog
1.8 (2019) - GPT-2 모델 소개
- https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdfD
- Radford, Alec, et al. "Language models are unsupervised multitask learners." OpenAI blog
이 논문들이 나오면서 자연어처리 성능 올리려면 = 기존보다 더더더더 데이터셋 많이 가지고와서 사전학습을 진행하자가 입증되었음.
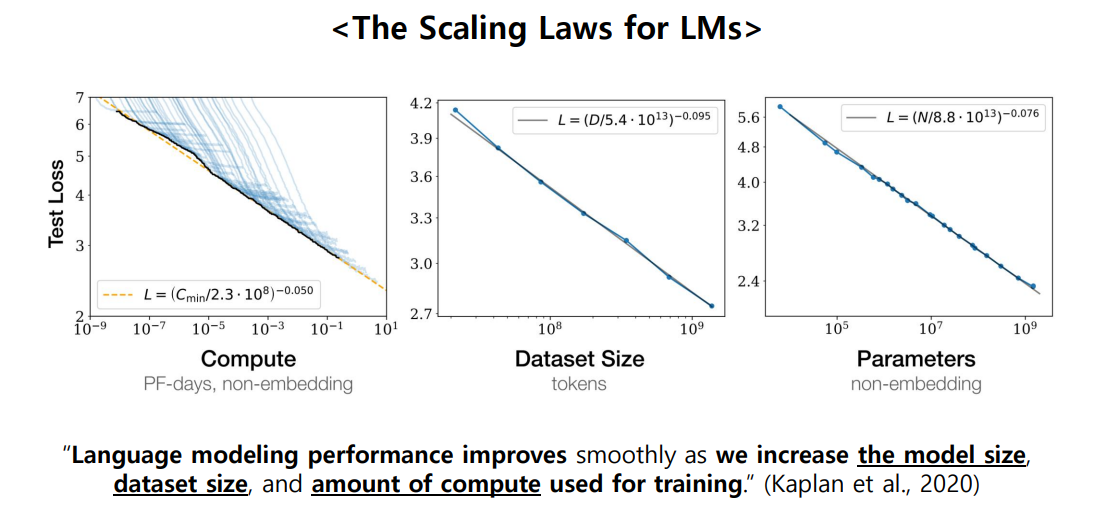
이러다가 모델이 점점 커지고 Fine-tuning의 한계(문제점)을 느끼고 연구 흐름이 점차 In-Context Learning, Prompt-based Learning 방향으로 흘러감.
In-Context Learning > 간단한 설명 + 예제 (zero-shot, one-shot, few-shot)
Prompt Learning > PLM(Pre Trained Model)의 입력방식 그대로 사용 (ex. Classifer Head(X), Only <MASK> )
- Language Models are Few-Shot Learners
- Brown, Tom, et al. "Language models are few-shot learners." Advances in neural information processing systems 33 (2020): 1877-1901.
- 트랜스포머의 디코더 활용 → GPT-3 모델 소개 (크기 엄청커짐. 약 1750억개의 파라미터라고했던가..)
- https://arxiv.org/pdf/2005.14165.pdf
- Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference
- Schick, Timo, and Hinrich Schütze. "Exploiting cloze questions for few shot text classification and natural language inference." arXiv preprint arXiv:2001.07676 (2020).
- PET 소개 → PVP이용한 Cloze 스타일의 Fewshot 학습
- https://arxiv.org/pdf/2001.07676.pdf
- It's Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners
- Schick, Timo, and Hinrich Schütze. "It's not just size that matters: Small language models are also few-shot learners." arXiv preprint arXiv:2009.07118 (2020).
- 멀티 PVP → 멀티 PET
- https://arxiv.org/pdf/2009.07118.pdf
연구는 점차 Meta-learning 안에 있는 In-context Learning(Zero-shot, One-shot, Few-shot)과 Prompt Learning으로 진행되었고, 기존 Fine-tuning기법과 맞서 성능을 끌어올림. 근데 큰 한계점이 있는데, Handcraft 방식이라는 점임. 조금만 Template을 바꿔줘도 성능이 확확 바뀌는 단점이 있음. 따라서 21년도 기준, Prompt Template을 자동으로 찾아주는 연구에 집중되어 왔음.

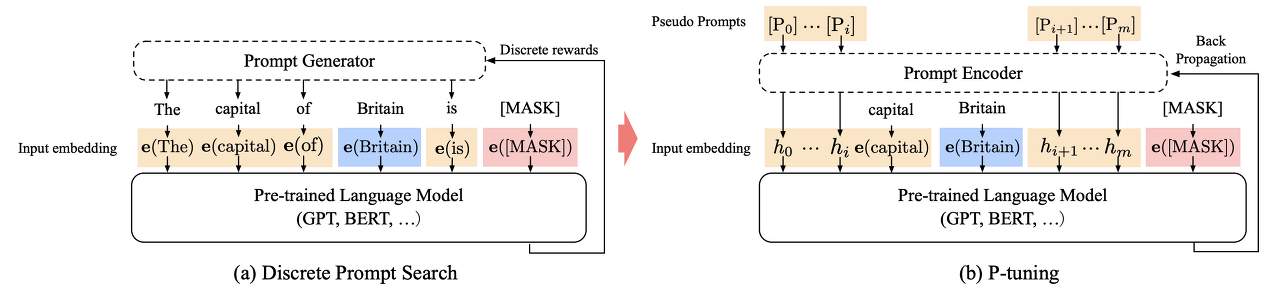
- GPT Understands, Too
- Liu, Xiao, et al. "GPT understands, too." arXiv preprint arXiv:2103.10385 (2021).
- P-Tuning을 제시
https://arxiv.org/pdf/2103.10385.pdf
💬 P-tuning이란
연속적인 공간에서 자동적으로 prompt를 검색하는 방법
NI-LSTM + ReLU activated two-layer MLP
지금까지 Prompt Learning 방식을 연구하면서 성능이 많이 좋아졌지만 그래도 문제점이 있음.Sequence lableling task 등에서는 성능이 낮음.
이를 해결하기 위해 나온게 P-tuning Ver.
모델 사이즈가 10B 이하면, Fine-tuning 기법보다 Prompt Tuning 방식이 더 성능이 낮음.
- P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks
- P-tuning Ver.2
- 모델 scale이나 NLU Task에 관련없이 최적화된 Prompt 구조 제시
- Masked Language Modeling 뿐만 아니라 Classification에서 적용 가능해짐
- Deep Prompt Tuning 구조 채택
- 모든 레이어에 Continuous prompt 적용
- Fine-tuning 대비 0.1% ~ 3%의 학습 파라미터로 메모리, 비용절약하고 성능 비슷하게 만듬
- Parameter-Efficient Prompt Tuning Makes Generalized and Calibrated Neural Text Retrievers
- P-tuning Ver.3?
- 두달전에 나온 따끈따끈한 논문인데 P-tuning에 대해서 더 설명하고 업그레이드 한듯하다.
- 아직 논문 읽지는 않았음.