자연어 추론쪽을 연구하면서, 진행중인 실험이 막혀서 잠깐 환기시킬겸 자연어 대회를 찾아봤었다.
캐글에서 진행중인 XNLI 대회, 한국 DACON에서 진행하는 평점 분류 대회 두가지를 찾아서 이를 진행해 보았다.
일단 이 대회를 찾았을 당시에 마감이 D-1이라 다른 기법을 사용하지는 못했고, 빠르게 제출하기 위한 베이스모델만 사용하여 대회에 참가하였다.
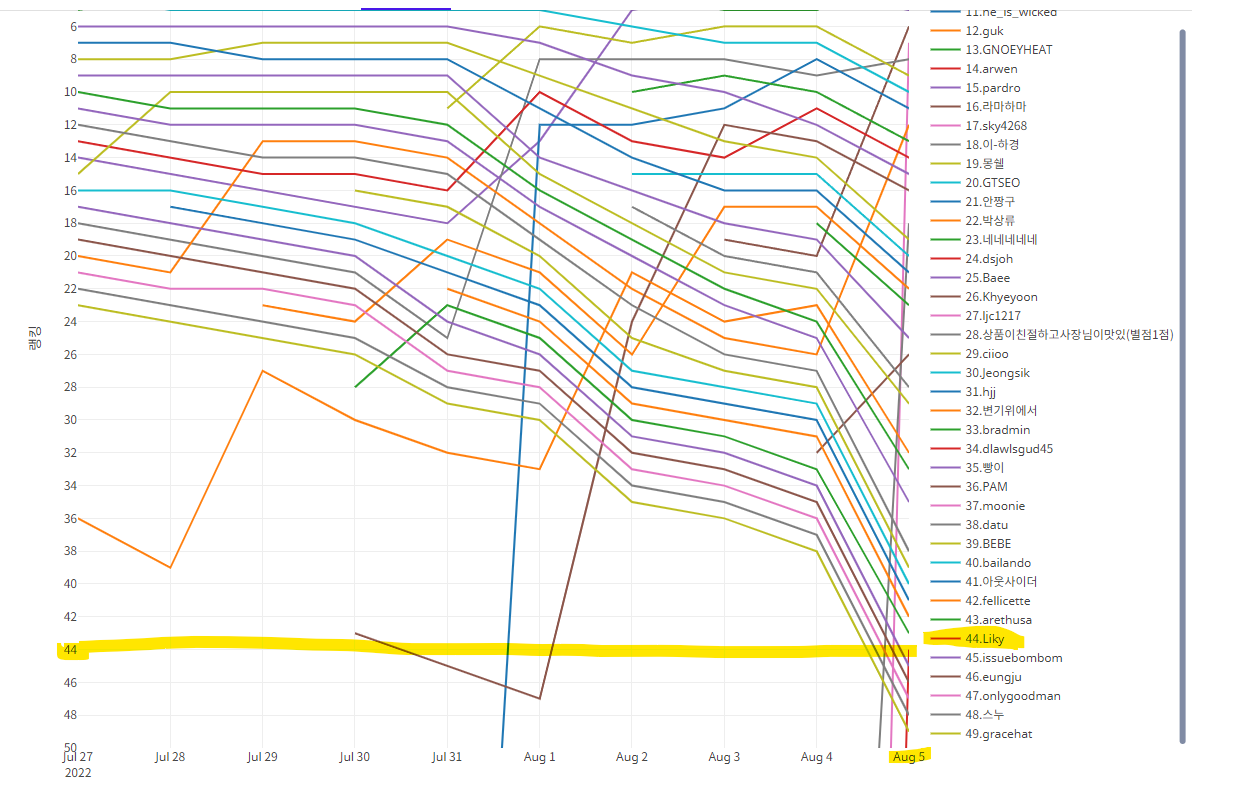
대회 참여 인원은 549명 정도였고, 1등의 점수는 0.71312 였다.
그리고 하루 투자해서 제출한 내 점수는 0.68888로, 1등과의 정확도 차이가 0.02432(약 2.4%) 차이였다.
베이직 대회인데 탑10도 못해서 현타가 오긴 했지만, 그래도 빠르게 제출할 수 있다는 거에 의의를 두었다.
처음에는 일단 한국어 커스텀 토크나이저를 만들어서 사용하기로 하였으나, 실패해버려서 3시간을 날렸다.
class tokenizer_class() :
def csv_to_text(self) :
data = pd.read_csv("dataset/train.csv")
train_pair = [(row[1], row[2]) for _, row in data.iterrows() if type(row[1]) == str] # nan 제거
# 문장 및 라벨 데이터 추출
train_data = [pair[0] for pair in train_pair]
train_label = [pair[1] for pair in train_pair]
print('문장: %s' %(train_data[:3]))
print('라벨: %s' %(train_label[:3]))
# subword 학습을 위해 문장만 따로 저장
with open('train_tokenizer.txt', 'w', encoding='utf-8') as f:
for line in train_data:
f.write(line+'\n')
# subword 학습을 위해 문장만 따로 저장
with open('train_tokenizer.txt', 'r', encoding='utf-8') as f:
test_tokenizer = f.read().split('\n')
print(test_tokenizer[:3])
num_word_list = [len(sentence.split()) for sentence in test_tokenizer]
print('\n코퍼스 평균/총 단어 갯수 : %.1f / %d' % (sum(num_word_list)/len(num_word_list), sum(num_word_list)))
return test_tokenizer
일단 데이터 셋에서 문장을 뽑고 라벨을 매긴 다음에,
각 문장의 평균 길이를 확인해보고, 총 단어가 몇개 있는지 확인하였다.

모델을 결정하고 모델에서 사용된 데이터셋 서브워드분리 알고리즘을 따라 채택하여야한다.
그 뒤로 Mecab을 이용하여 토큰화를 진행하려 하였는데,
Mecab은 윈도우에서 자동으로 설치가 안되서, 따로 설정해주어야 하는 것이 많고, 이 환경을 만드는데에 시간도 좀 걸릴 듯 해서 Okt 알고리즘으로 토큰화를 진행하였다.
def Okt(self, data):
tokenizer = Okt()
print('Okt check :', tokenizer.morphs('어릴때보고 지금다시봐도 재밌어요ㅋㅋ'))
for_generation = False
# 1: '어릴때' -> '어릴, ##때
if for_generation:
total_morph = []
for sentence in data:
# 문장단위 Okt 적용
morph_sentence = []
count = 0
for token_okt in tokenizer.morphs(sentence):
token_okt_save = token_okt
if count > 0:
token_okt_save = "##" + token_okt_save # 앞에 ##를 부친다
morph_sentence.append(token_okt_save)
else:
morph_sentence.append(token_okt_save)
count += 1
total_morph.append(morph_sentence)
else:
# 2: '어릴때' -> '어릴, 때'
total_morph = []
for sentence in data:
morph_sentence = tokenizer.morphs(sentence)
total_morph.append(morph_sentence)
print(total_morph[:3])
print(len(total_morph))
# ex) 1 line: '어릴 때 보 고 지금 다시 봐도 재밌 어요 ㅋㅋ'
with open('after_okt.txt', 'w', encoding='utf-8') as f:
for line in total_morph:
f.write(' '.join(line) + '\n')
with open('after_okt.txt', 'r', encoding='utf-8') as f:
test_tokenizer = f.read().split('\n')
return test_tokenizer
def train_tokenizer(self, tokenizer) :
corpus_file = ['after_okt.txt'] # data path
vocab_size = 32000
limit_alphabet = 6000 #merge 수행 전 initial tokens이 유지되는 숫자 제한
# output_path = 'hugging_%d' % (vocab_size)
min_frequency = 2 # n회 이상 등장한 pair만 merge 수행
# Then train it!
tokenizer.train(files=corpus_file,
vocab_size=vocab_size,
min_frequency=min_frequency, # 단어의 최소 발생 빈도, 5
limit_alphabet=limit_alphabet, # ByteLevelBPETokenizer 학습시엔 주석처리 필요
show_progress=True,
special_tokens=["<s>", "</s>", "<unk>", "<pad>", "<mask>"])
print('train complete')
sentence = '나는 오늘 아침밥을 먹었다.'
output = tokenizer.encode(sentence)
print(sentence)
print(output)
# save tokenizer
hf_model_path = 'liky_tokenizer'
if not os.path.isdir(hf_model_path):
os.mkdir(hf_model_path)
tokenizer.save_model(hf_model_path)
return tokenizer
근데 이 토크나이저를 만들었는데 제대로 안만들어졌다.
커스텀 토크나이저 제작은 시간 상 보류하고 나중에 Mecab 환경을 다시 구성해서 따로 하기로하였다.
일단 허깅페이스에 올라온 한국어 토크나이저를 사용해서 문제를 풀어보았다.
from transformers import AlbertForSequenceClassification, AlbertConfig, AlbertTokenizer
from transformers import RobertaConfig, RobertaForSequenceClassification, RobertaTokenizer, DataCollatorWithPadding
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
from sklearn.metrics import confusion_matrix
from sklearn.metrics import precision_score, recall_score, f1_score, accuracy_score, classification_report
from datasets import load_dataset, DatasetDict
from torch import nn
from torch.optim import Adam
from tqdm import tqdm
import torch
import matplotlib.pyplot as plt
from torch.utils.data import DataLoader
from transformers import AutoModelForSequenceClassification, AutoTokenizer
def train(train_dataloader,val_dataloader):
model = AutoModelForSequenceClassification.from_pretrained("klue/roberta-large", num_labels=6)
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print(device)
len_train_data = 22500
len_val_data = 2500
model.to(device)
optimizer = Adam(model.parameters(), lr=1e-5)
top_val_loss = 100
top_val_accuracy = 0
train_loss_list =[]
val_loss_list = []
train_acc_list = []
val_acc_list = []
for epoch in range(20):
model.train()
total_acc_train = 0
total_loss_train = 0
now_data_len = 0
train_dataloader = tqdm(train_dataloader, desc='Loading train dataset')
for i, batch in enumerate(train_dataloader):
optimizer.zero_grad()
batch = {k: v.to(device) for k, v in batch.items()}
output = model(input_ids=batch["input_ids"],
token_type_ids=batch['token_type_ids'],
attention_mask=batch['attention_mask'],
labels=batch['labels'])
#batch_loss = lossfunction(output.logits, batch['labels'])
output.loss.backward()
optimizer.step()
predict = torch.argmax(output.logits, dim=-1)
total_loss_train = total_loss_train + output.loss.item()
acc = (predict == batch['labels']).sum().item()
total_acc_train += acc
now_data_len += len(batch['labels'])
train_dataloader.set_description("Loss %.04f Acc %.04f | step %d Epoch %d" % (output.loss, total_acc_train / now_data_len, i,epoch))
total_acc_val = 0
total_loss_val = 0
with torch.no_grad():
model.eval()
for batch in tqdm(val_dataloader):
batch = {k: v.to(device) for k, v in batch.items()}
output = model(**batch)
predict = torch.argmax(output.logits, dim=-1)
acc = (predict == batch['labels']).sum().item()
#batch_loss = lossfunction(output.logits, batch['labels'])
total_loss_val += output.loss.item()
total_acc_val += acc
print()
print(f'Epochs: {epoch + 1} \n'
f'| Train Loss: {total_loss_train / len_train_data: .3f} \n'
f'| Train Accuracy: {total_acc_train / len_train_data: .3f} \n'
f'| Val Loss: {total_loss_val /len_val_data: .3f} \n'
f'| Val Accuracy: {total_acc_val / len_val_data: .3f}')
train_acc_list.append(total_acc_train / len_train_data)
train_loss_list.append(total_loss_train / len_train_data)
val_acc_list.append(total_acc_val / len_val_data)
val_loss_list.append(total_loss_val /len_val_data)
# if total_loss_val > top_val_loss and total_acc_val < top_val_accuracy :
#
# break
# if total_loss_val < top_val_loss:
# top_val_loss = total_loss_val
# if total_acc_val > top_val_accuracy:
# top_val_accuracy = total_acc_val
model_path = "./model" + str(epoch) + ".pth"
model.save_pretrained(model_path)
return model, train_acc_list, train_loss_list, val_acc_list, val_loss_list
def data() :
data = pd.read_csv("./dataset/train.csv")
data['target'].unique() # 1,2,4,5 만 있음.
raw_train = load_dataset('csv', data_files='./dataset/train.csv')
raw_test = load_dataset('csv', data_files='./dataset/test.csv')
train, valid = raw_train['train'].train_test_split(test_size=0.1).values()
review_dataset = DatasetDict({'train': train, 'valid': valid, 'test': raw_test['train']})
def tokenize_function(example):
return tokenizer(example["reviews"], truncation=True)
tokenized_datasets = review_dataset.map(tokenize_function, batched=True)
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
tokenized_datasets = tokenized_datasets.remove_columns(["id", "reviews"])
tokenized_datasets['train'] = tokenized_datasets['train'].rename_column("target", "labels")
tokenized_datasets['valid'] = tokenized_datasets['valid'].rename_column("target", "labels")
tokenized_datasets.set_format("torch")
train_dataloader = DataLoader(tokenized_datasets["train"], shuffle=True, batch_size=8, collate_fn=data_collator)
val_dataloader = DataLoader(tokenized_datasets["valid"], shuffle=True, batch_size=8, collate_fn=data_collator)
test_dataloader = DataLoader(tokenized_datasets["test"], shuffle=False, batch_size=8, collate_fn=data_collator)
return train_dataloader, val_dataloader, test_dataloader
def final_test(model, test_dataloader):
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
model.to(device)
prediction_list = []
label_list = []
model.eval()
with torch.no_grad():
for batch in tqdm(test_dataloader):
outputs = model(**batch.to(device))
logits = outputs.logits
predictions = torch.argmax(logits, dim=-1)
prediction_list.extend(predictions.cpu().tolist())
submission = pd.read_csv("dataset/sample_submission.csv")
submission["target"] = prediction_list
submission.to_csv("submission.csv",index=False)
return prediction_list
def confusion(prediction_list) :
# 혼동행렬
my_data = []
y_pred_list = []
for data in prediction_list :
for data2 in data :
my_data.append(data2.item())
for data in label_list :
for data2 in data :
y_pred_list.append(data2.item())
confusion_matrix(my_data, y_pred_list)
confusion_mx = pd.DataFrame(confusion_matrix(y_pred_list, my_data))
ax =sns.heatmap(confusion_mx, annot=True, fmt='g')
plt.title('confusion', fontsize=20)
plt.show()
print(f"precision : {precision_score(my_data, y_pred_list, average='macro')}")
print(f"recall : {recall_score(my_data, y_pred_list, average='macro')}")
print(f"f1 score : {f1_score(my_data, y_pred_list, average='macro')}")
print(f"accuracy : {accuracy_score(my_data, y_pred_list)}")
f1_score_detail= classification_report(my_data, y_pred_list, digits=3)
print(f1_score_detail)
def result_graph(train_acc_list, train_loss_list, val_acc_list, val_loss_list):
epochs = [x for x in range(len(train_loss_list))]
print(epochs)
plt.plot(epochs, train_loss_list, 'r', label='Training loss')
epochs = [x for x in range(len(val_loss_list))]
plt.plot(epochs, val_loss_list, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
epochs = [x for x in range(len(train_acc_list))]
plt.plot(epochs, train_acc_list, 'r', label='Training Accuracy')
epochs = [x for x in range(len(val_acc_list))]
plt.plot(epochs, val_acc_list, 'b', label='Validation Accuracy')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
if __name__ == "__main__":
tokenizer = AutoTokenizer.from_pretrained("klue/roberta-large")
train_dataloader, val_dataloader, test_dataloader = data()
model, train_acc_list, train_loss_list, val_acc_list, val_loss_list = train(train_dataloader, val_dataloader)
result_graph(train_acc_list, train_loss_list, val_acc_list, val_loss_list)
predict_list, label_list = final_test(model, test_dataloader)
submission = pd.read_csv("dataset/sample_submission.csv")
submission["target"] = predict_list
submission.to_csv("submission.csv",index=False)
#%% 저장된 모델 사용해서 다시 테스트
model = AutoModelForSequenceClassification.from_pretrained("model19.pth")
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
model.to(device)
prediction_list = []
label_list = []
model.eval()
with torch.no_grad():
for batch in tqdm(test_dataloader):
outputs = model(**batch.to(device))
logits = outputs.logits
predictions = torch.argmax(logits, dim=-1)
prediction_list.extend(predictions.cpu().tolist())
submission = pd.read_csv("dataset/sample_submission.csv")
submission["target"] = prediction_list
submission.to_csv("submission3.csv",index=False)허깅페이스에 올라온 "klue/roberta-large"를 사용하여 토크나이저와 모델을 가지고와서 학습을 진행하였다.
처음에 학습 조기 종료 알고리즘을 작성하여 모델을 학습시키려다가, 제출 기한 시간내에 다시 실험을 진행하기에 어려움이 있을 것 같아서 Epoch만큼 쭉 학습시키고 각각의 학습 모델들을 저장하였다.
그런 다음 Validation loss와 accuracy가 가장 높은 모델을 불러와서 Test 데이터셋을 Prediction 하였다.
코드를 중간중간에 보고 지우고 주석처리하고 해서 꼬이긴 했는데, 전체 코드이다.
간단하게 전처리하고, 토큰화 시킨 다음에 Roberta 모델위에 분류를 위한 층을 얹힌 다음에, loss값 구하면서 학습을 진행했다. num_label이 6인 이유는, 데이터셋에 있는 라벨값을 출력해보니 1,2,4,5 점만 있어서 6으로 설정해서 학습하였다.

이런식으로 학습 과정을 보면서, 에포크가 끝날때 마다 아래와 같이 표를 출력하였다.
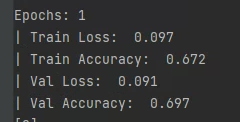
원래는 그래프로 나와서 그거보고 최종 모델을 채택했는데, 그래프를 저장 안해서 날라갔다.
어쨋든 그걸 기반으로 실험한 결과 제출하니
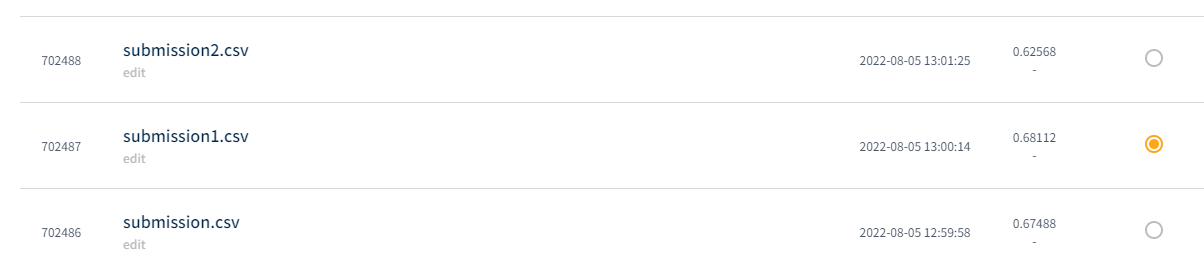
이런식으로 나와서 제출하고 리더보드에 올라갔다.
제출과 동시에 대회가 끝나가서 사람들이 코드 공유를 시작하였다.
1등코드부터 보는데 Voting 알고리즘부터 죄다 앙상블해서 풀고, 데이터셋도 분석 빡세게 해서 많은 도움이 되었다.
대회를 통해 느낀점
1. 난 쓰레기다. 자연어 한다면서 top3는 무슨 top10도 못하냐
2. 그래도 하루만에 코드 작성해서 제출할 정도는 되는구나
3. 정확도 3%올릴려고 사람들은 여러 기법들을 추가해서 실험했구나.
4. 탑코드 보면서, 연구하는데에 아이디어도 얻고 도움이 되었다.
4-1 ex. 트랜스포머 모델의 마지막 레이어에 self explaining을 위한 층을 추가하여 각 간어의 feature값을 뽑고,,,,, k-fold를 이용해서 학습을 진행하는데.... 모델을 ensemble해서 풀거고... voting 알고리즘을 추가하여 실험을 진행하면 성능향상이 ... 등등
아래는 추가적인 코드
k_folds = 5
data_size = len(df)
fold_size = data_size // k_folds
for fold in range(k_folds):
print(f"Training on Fold {fold + 1}")
val_start_idx = fold * fold_size
val_end_idx = min((fold + 1) * fold_size, data_size) #인덱스초과방지
val_data = df.iloc[val_start_idx:val_end_idx].reset_index(drop=True)
train_data = pd.concat([df.iloc[:val_start_idx], df.iloc[val_end_idx:]]).reset_index(drop=True) if acc_top < accuracy_score(prediction_list, label_list):
if os.path.exists(f"{acc_top:.5f}.pth"):
os.remove(f"{acc_top:.5f}.pth")
acc_top = accuracy_score(prediction_list, label_list)
torch.save(model.state_dict(),
f"{accuracy_score(prediction_list, label_list):.5f}.pth")