Schick, Timo, and Hinrich Schütze. "Exploiting Cloze-Questions for Few-Shot Text Classification and Natural Language Inference." Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume. 2021.
Schick, Timo, and Hinrich Schütze. "It’s Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners." Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2021.
두 개의 논문에 대해서 리뷰를 하려한다.
PET 방식의 Few-shot Learning에 대하여 기술된 논문이다.



간단하게 Overview 느낌으로 Few-shot Learning이 무엇인지 설명해보자면,

이런식으로 이미지 데이터를 주고 무엇이냐고 물어보면 우리는 한번에 맞추기 어려울 것이다.

근데, 이런식으로 예제를 주고 물어보면 우리는 Pangolin이라고 맞출 수 있을 것이다.
이게 어떻게 가능할까?

인공지능을 통해서 질문한 이미지속 동물이 Pangolin 인것을 맞추려면 수많은 데이터를 사용해 특징을 학습하여 맞춰야 할수도 있다.
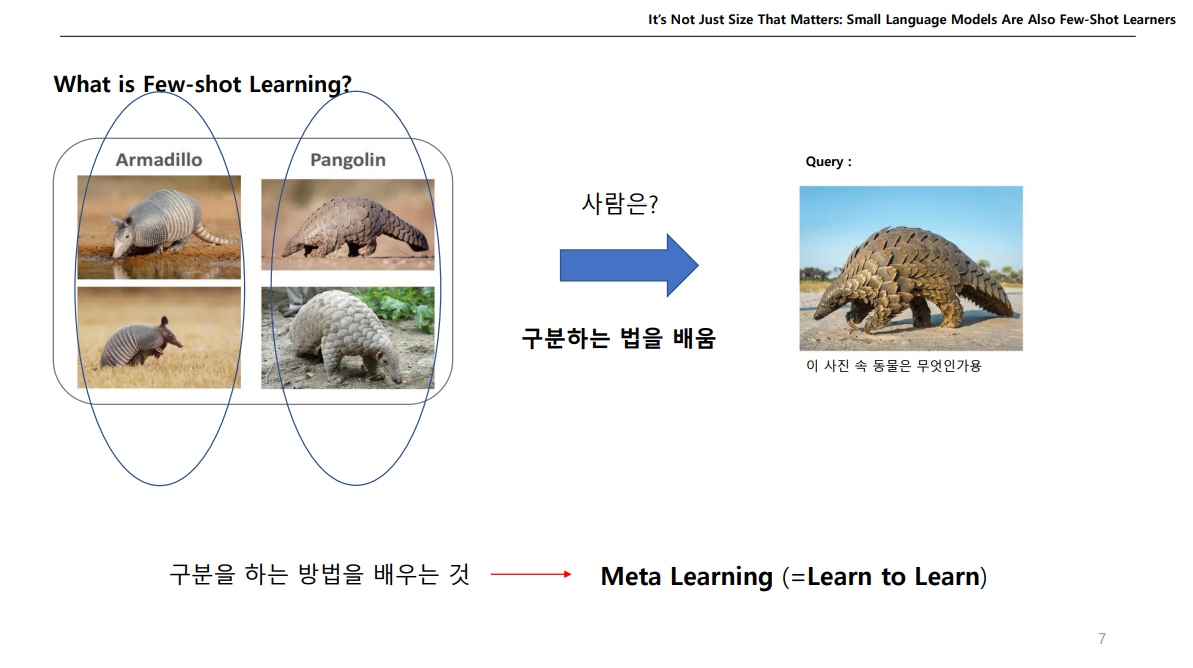
그런데 사람은 몇 장의 데이터만 있더라도 이 동물이 무엇인지 맞출 수 있다.
우리는 저 동물에 대해서 학습한 것이 아닌, 무언가를 구분하는 방법을 알고있다.
이렇게 '구분 하는 방법을 배우는 것'을 메타 러닝(Meta Learning)이라고 한다.

메타 러닝에서도 수많은 기법이 존재하지만, Application 안에 속하는 Few-shot Learning에 대해서 얘기하고자 한다.
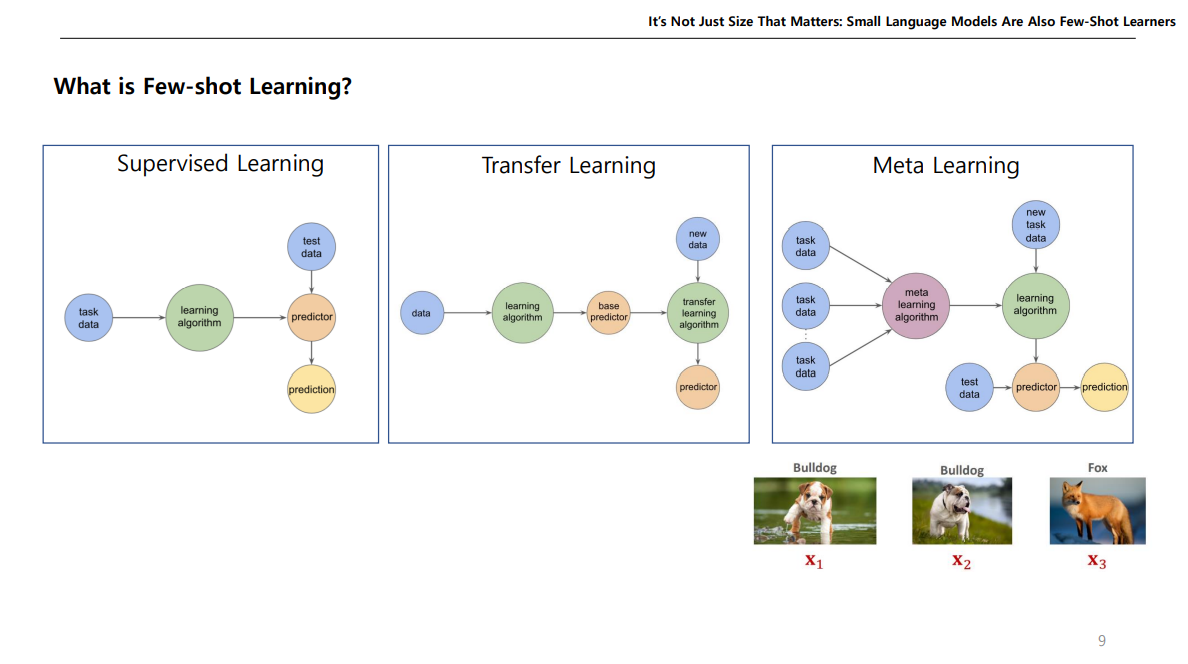
기존 지도학습(Supervised Learning) 같은 경우는 특정 Task를 정하여 이를 위한 데이터들을 모은다음에, 학습을 진행하고, 이 학습된 모델을 가지고 Test Data를 넣어서 결과를 예측한다.
전이학습(Transfer Learning)같은 경우에는, 다른 Task에서 사용한 기존 학습된 모델에서 Fine-tuning이나 동결 해제 등을 통해서 원하는 Task를 위한 전이 학습을 진행 후, 이 모델을 가지고 새로운 데이터를 넣어 결과를 예측한다.
Meta Learning 같은 경우는 Task를 정하지 않고 여러 데이터를 학습하여 그 데이터들의 특징과 패턴을 학습한 다음에, 특정 Task를 위한 예제 데이터를 모델에 넣어서 예측모델을 제작하고 여기다가 Test dataset을 넣어 결과를 예측한다.
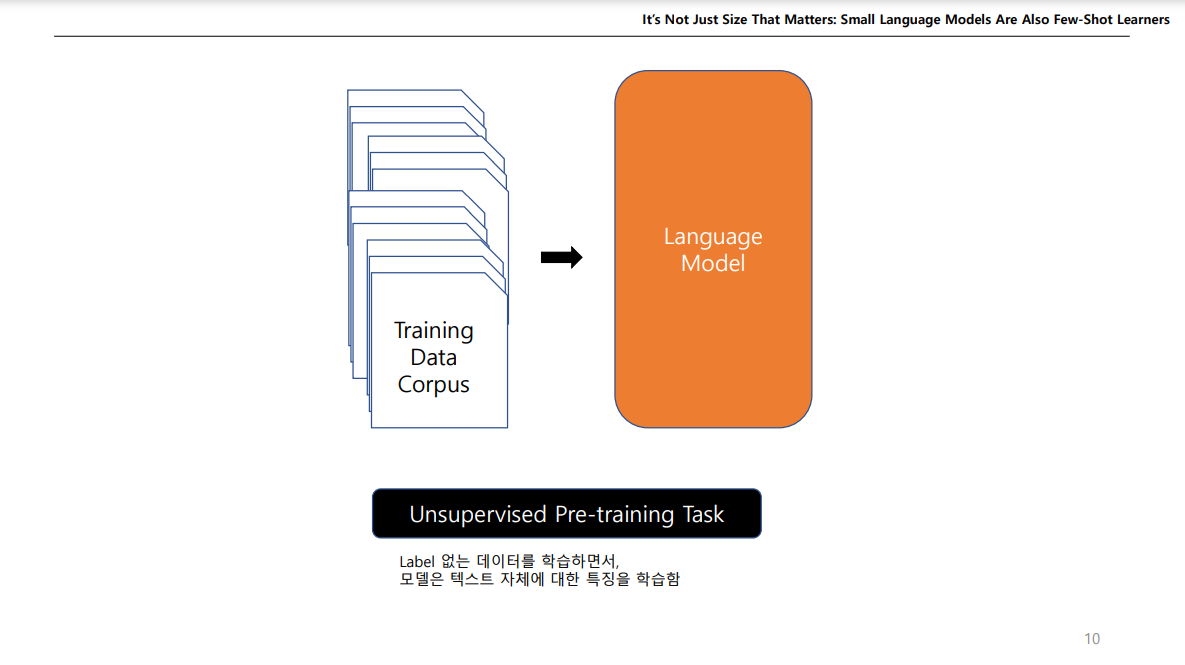
NLP 경우에도, 많은 데이터를 넣어서 LM을 제작하고, 이를 다운스트림 테스크에 이용하는 방식으로 많이 연구되고 있다.
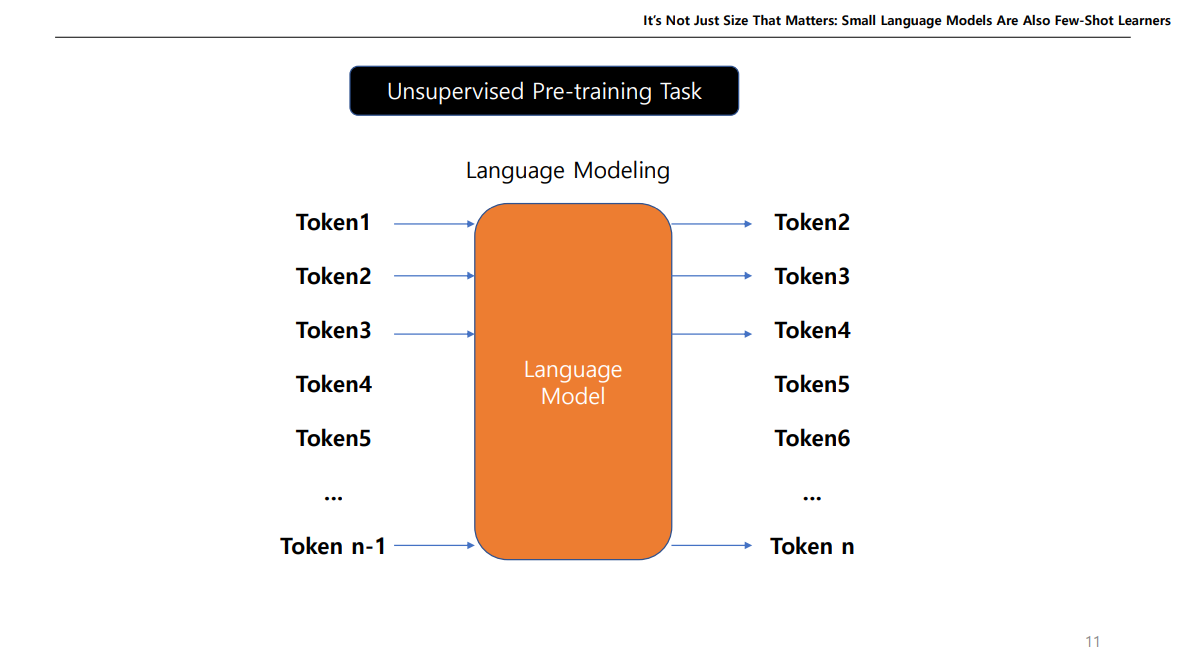
보통 LM을 학습할 때 Unsupervise pre-training Task 방식으로 학습하는데, 위와같이 다음 토큰을 예측하는 작업이나, Bert같이 Mask 토큰을 예측하는 작업 등을 말한다.

이렇게 만든 LM은 여러 NLP Task에 사용될 수 있다.
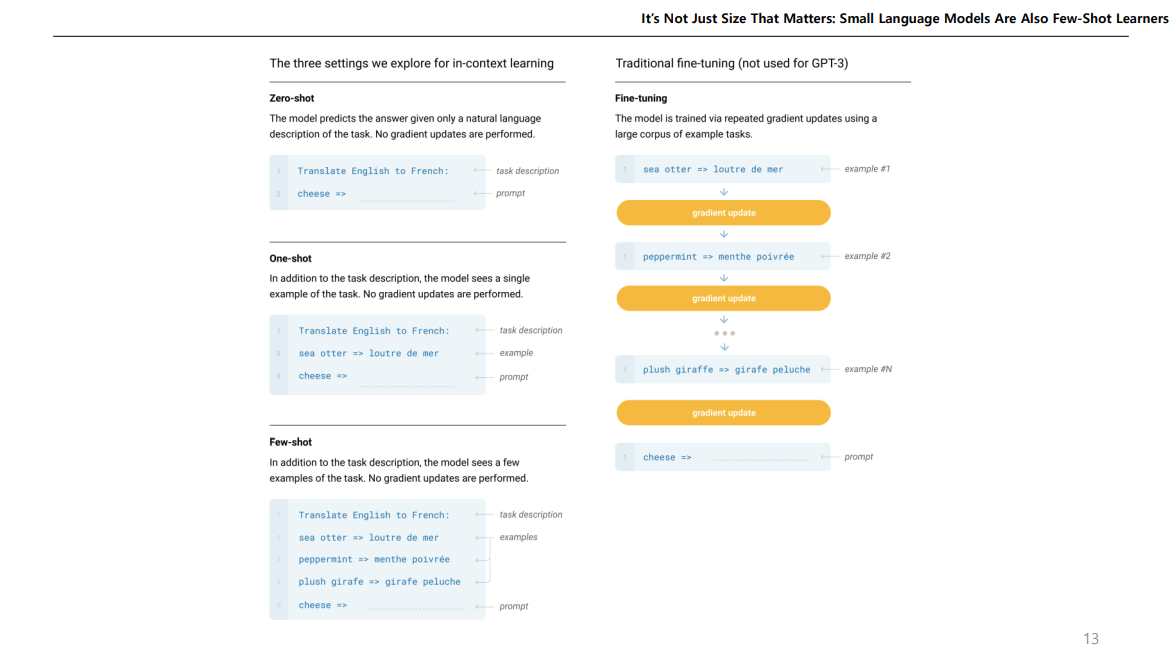
Zero-shot 은 Task에 대한 설명만 하고 바로 예측하는 것이고,
One-shot 은 설명을 해주고 하나의 예제만 주고 맞추는 것,
Few-shot 은 2개 이상의 예제를 주고 맞추는 것이다.
Fine-tuning 처럼 가중치 업데이트가 이루어지는 방식이 아닌 모델의 지식을 이용하는 예측 방법이다.
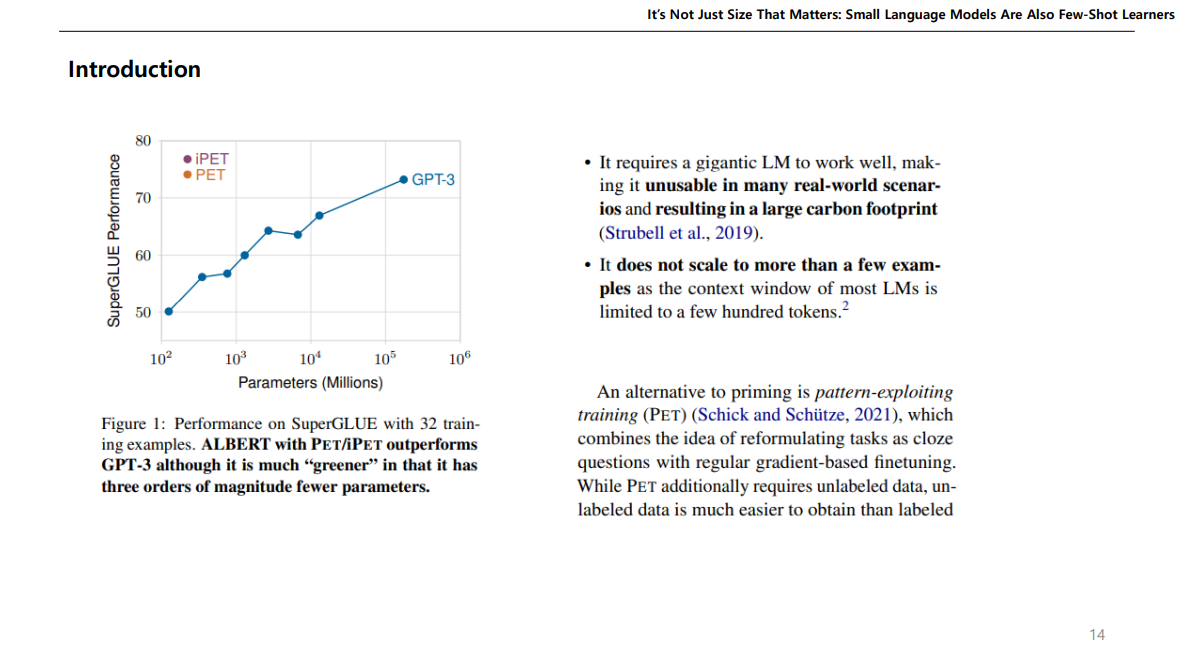
논문을 보면 LM이 잘 작동할려면 큰 LM이 요구되는데, GPT같이 큰 LM은 현실세계 시나리오에서 만들어 쓰기 힘들고 탄소도 많이 배출된다. GPT 만드는데 몇백억씩 썼으니.. 일반인들은 못만들어 씀..
근데 이런 GPT보다 몇몇 특정 Task에서 파라미터는 몇천배 적은데 성능은 훨씬 높은 PET 방식을 소개한다.

기본 아이디어를 BERT로 설명하자면, 모델에 그냥 저렇게 문장을 넣으면 모델은 모르는데, BERT의 학습방식인 Masked Token을 넣으면 잘 맞출 것이다.
LM같은 경우는 많은 Corpus를 학습하였기에, 학습되어진 모델의 지식을 이용하여 문제를 모델이 이해할 수 있도록 변형한 다음에 결과를 예측해 보자는 아이디어이다.

이 방식이 PET 인데, Pattern과 Verbalizer를 한 쌍의 Pair로 만들어서 사용하자는 개념이다.
쉽게 설명하자면,

Input에 들어가는 Sentence들을 빈칸이 뚤린 Cloze Question으로 변형하여, 빈칸을 맞추도록 하자는 건데,
원래 target값인 라벨들을 Yes나 No 처럼 바꾸어주는 Verbalizer 을 사용한 다음에 맞추는 것이다.
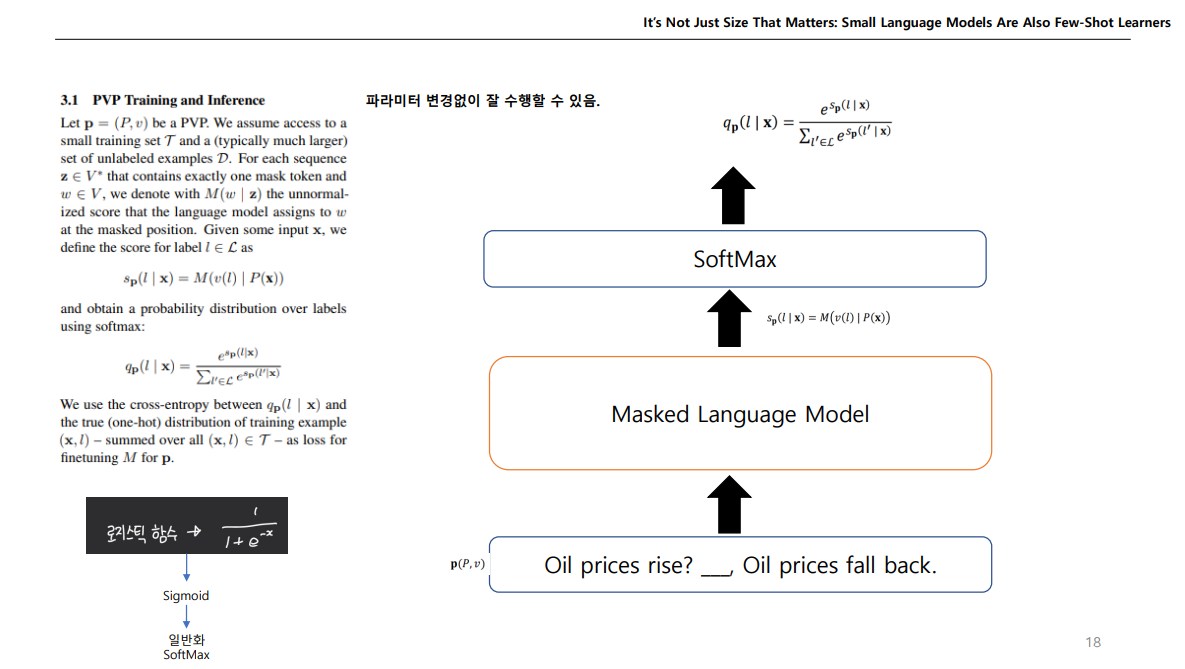
이처럼 변형된 Cloze Question을 MLM에 넣어서 로직값을 받고, Vocab에 수많은 토큰중에서 필요한 Yes, No 토큰만 가지고 이들만 softmax로 하여 빈칸이 뭐가 나올지 예측하는 것이다.
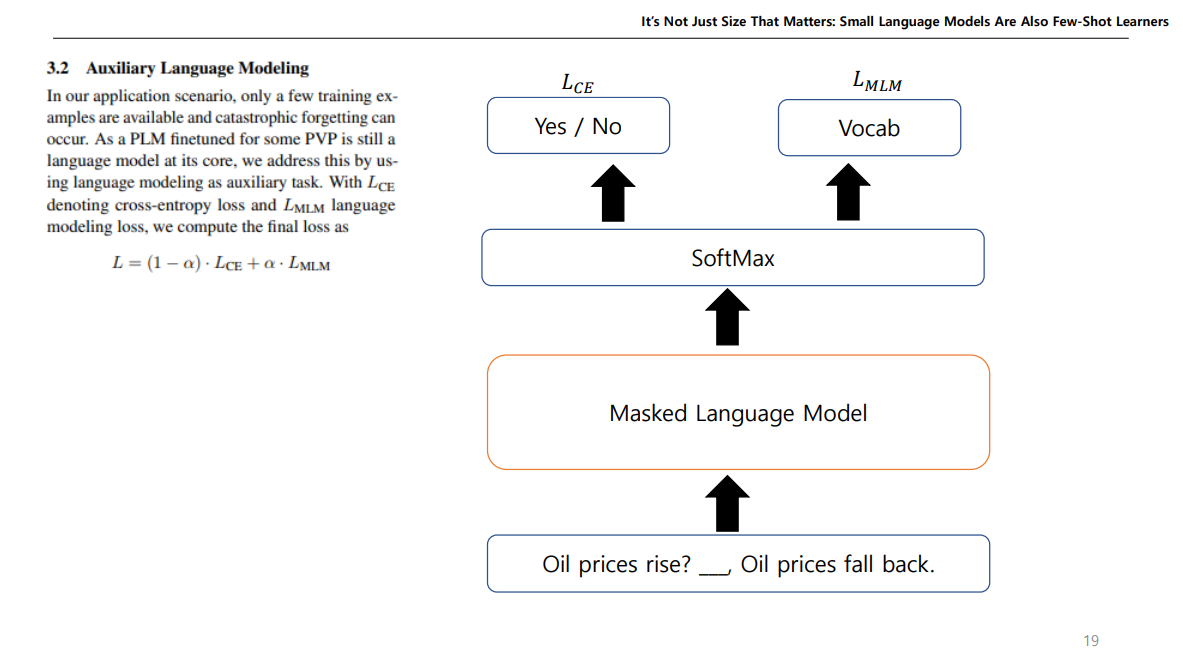
모델을 예측할때는 위와같이 하지만, 모델을 학습하고 싶다면 위에서 나온 값에서 크로스 엔트로피를 사용하여 Loss값을 구하고, Vocab에 있는 전체 토큰에 대해서도 Loss값을 구해서 이 둘을 합쳐서 전체적인 Loss를 설정하여 학습한다.
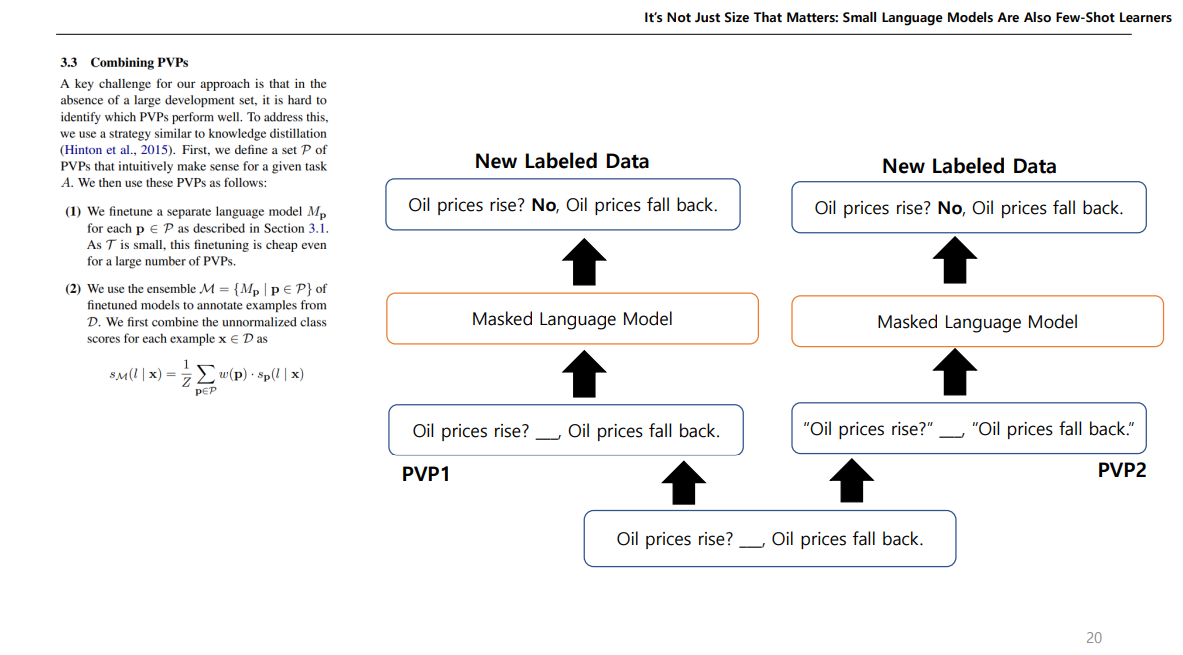
그러고 이렇게 예측하는 PVP에서 패턴을 다르게 설정하여 여러개의 PVP를 만든다음에 이를 앙상블하여 학습하면 성능이 좋다고한다. 이렇게하면 각기 다른 새로운 데이터를 얻을수 있다. 오른쪽에 새로운 데이터는 오타가 났다. "" 있어야한다.
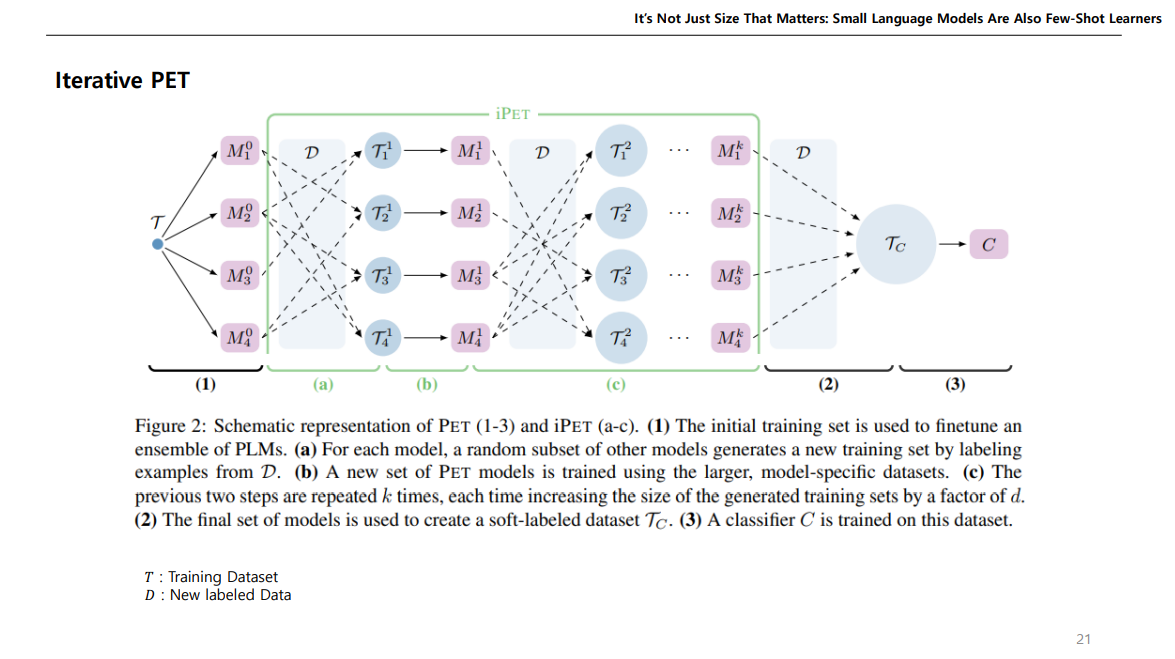
이렇게 각기 다른 패턴으로 여러 PLM에 대해 학습하는 것을 반복하는것이 iPET이다.

두번째 논문에서 나온게 멀티플 마스크드인데, 예측해야하는 토큰이 하나가 아닌 두개 이상일 수도 있으니, 빈칸 두개 뚫어놓고 각각의 확률값에 따라 높은 확률을 가진 토큰을 먼저 넣는 방식으로 진행하면 빈칸을 두개도 뚫을 수 있다는 얘기이다.

논문에서는 각 Task마다 패턴을 어떻게 하면 좋을지 써놨는데, 여기서 약간의 단점이 나온다.
정규화된 공식 없이 저자가 일일이 수기로 해본 형식이다.
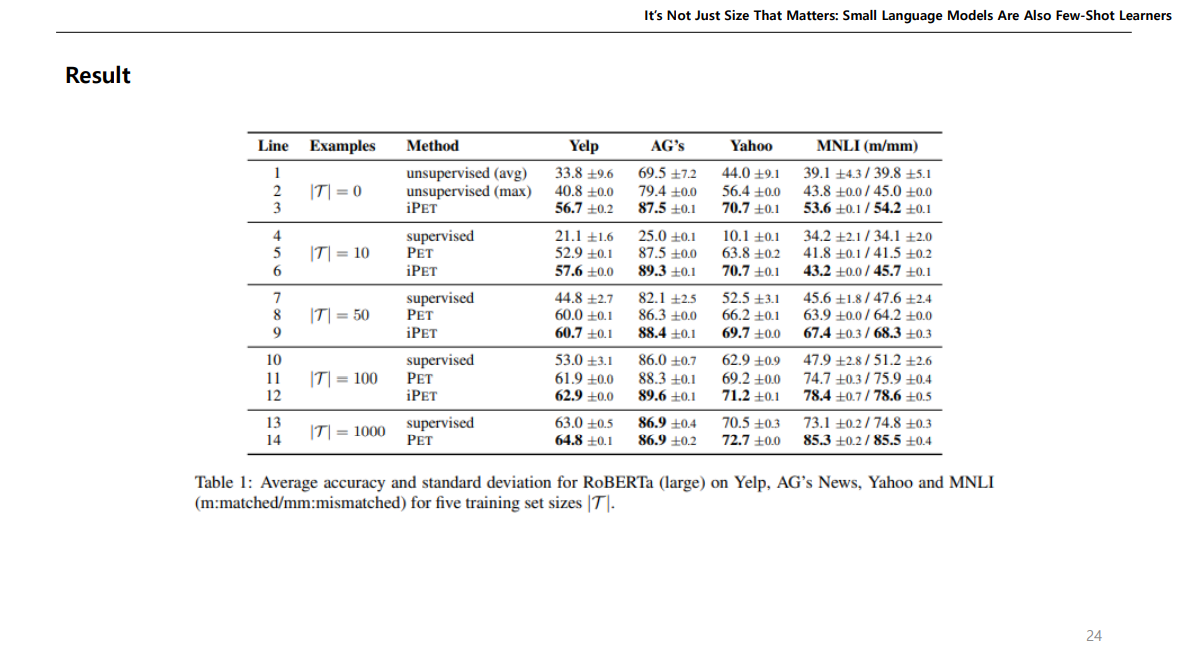
어쨌든 이런 방식으로 Roberta를 학습해보니 데이터가 많이 없을 때, iPET 방식이 다른 비지도학습 및 지도학습보다 성능이 높다고 한다.
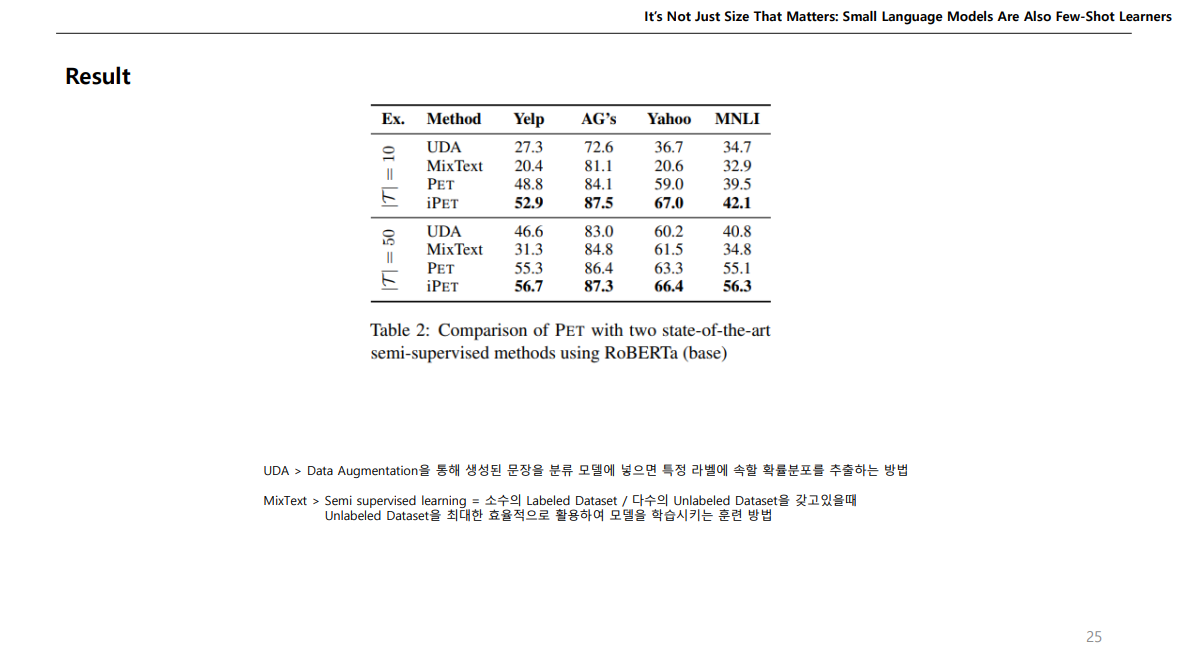
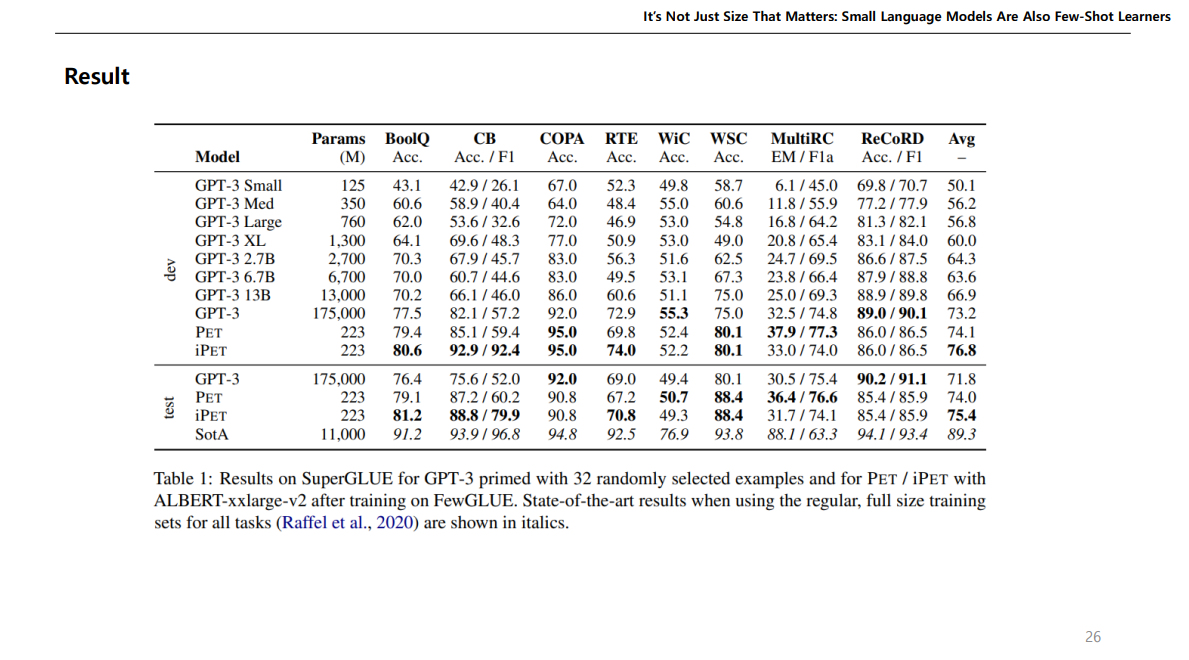
여기 결과가 중요한데, ALBERT를 사용하였을때 파라미터는 223M 이지만, 그에반해 GPT는 175,000M이다.
근데 평균을 보면 파라미터가 훨씬 큰 GPT보다 성능이 더 높게 나온다.
따라서 논문에서 주장하는 건, 작은 LM이라도 논문에서 제시한 것 처럼 그 모델의 지식을 활용하여 예측하면 더 잘나올 수도 있다는 것이다.


Schick, Timo, and Hinrich Schütze. "Exploiting Cloze-Questions for Few-Shot Text Classification and Natural Language Inference." Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume. 2021.
Schick, Timo, and Hinrich Schütze. "It’s Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners." Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2021.
두 개의 논문에 대해서 리뷰를 하려한다.
PET 방식의 Few-shot Learning에 대하여 기술된 논문이다.
간단하게 Overview 느낌으로 Few-shot Learning이 무엇인지 설명해보자면,
이런식으로 이미지 데이터를 주고 무엇이냐고 물어보면 우리는 한번에 맞추기 어려울 것이다.
근데, 이런식으로 예제를 주고 물어보면 우리는 Pangolin이라고 맞출 수 있을 것이다.
이게 어떻게 가능할까?
인공지능을 통해서 질문한 이미지속 동물이 Pangolin 인것을 맞추려면 수많은 데이터를 사용해 특징을 학습하여 맞춰야 할수도 있다.
그런데 사람은 몇 장의 데이터만 있더라도 이 동물이 무엇인지 맞출 수 있다.
우리는 저 동물에 대해서 학습한 것이 아닌, 무언가를 구분하는 방법을 알고있다.
이렇게 '구분 하는 방법을 배우는 것'을 메타 러닝(Meta Learning)이라고 한다.
메타 러닝에서도 수많은 기법이 존재하지만, Application 안에 속하는 Few-shot Learning에 대해서 얘기하고자 한다.
기존 지도학습(Supervised Learning) 같은 경우는 특정 Task를 정하여 이를 위한 데이터들을 모은다음에, 학습을 진행하고, 이 학습된 모델을 가지고 Test Data를 넣어서 결과를 예측한다.
전이학습(Transfer Learning)같은 경우에는, 다른 Task에서 사용한 기존 학습된 모델에서 Fine-tuning이나 동결 해제 등을 통해서 원하는 Task를 위한 전이 학습을 진행 후, 이 모델을 가지고 새로운 데이터를 넣어 결과를 예측한다.
Meta Learning 같은 경우는 Task를 정하지 않고 여러 데이터를 학습하여 그 데이터들의 특징과 패턴을 학습한 다음에, 특정 Task를 위한 예제 데이터를 모델에 넣어서 예측모델을 제작하고 여기다가 Test dataset을 넣어 결과를 예측한다.
NLP 경우에도, 많은 데이터를 넣어서 LM을 제작하고, 이를 다운스트림 테스크에 이용하는 방식으로 많이 연구되고 있다.
보통 LM을 학습할 때 Unsupervise pre-training Task 방식으로 학습하는데, 위와같이 다음 토큰을 예측하는 작업이나, Bert같이 Mask 토큰을 예측하는 작업 등을 말한다.
이렇게 만든 LM은 여러 NLP Task에 사용될 수 있다.
Zero-shot 은 Task에 대한 설명만 하고 바로 예측하는 것이고,
One-shot 은 설명을 해주고 하나의 예제만 주고 맞추는 것,
Few-shot 은 2개 이상의 예제를 주고 맞추는 것이다.
Fine-tuning 처럼 가중치 업데이트가 이루어지는 방식이 아닌 모델의 지식을 이용하는 예측 방법이다.
논문을 보면 LM이 잘 작동할려면 큰 LM이 요구되는데, GPT같이 큰 LM은 현실세계 시나리오에서 만들어 쓰기 힘들고 탄소도 많이 배출된다. GPT 만드는데 몇백억씩 썼으니.. 일반인들은 못만들어 씀..
근데 이런 GPT보다 몇몇 특정 Task에서 파라미터는 몇천배 적은데 성능은 훨씬 높은 PET 방식을 소개한다.
기본 아이디어를 BERT로 설명하자면, 모델에 그냥 저렇게 문장을 넣으면 모델은 모르는데, BERT의 학습방식인 Masked Token을 넣으면 잘 맞출 것이다.
LM같은 경우는 많은 Corpus를 학습하였기에, 학습되어진 모델의 지식을 이용하여 문제를 모델이 이해할 수 있도록 변형한 다음에 결과를 예측해 보자는 아이디어이다.
이 방식이 PET 인데, Pattern과 Verbalizer를 한 쌍의 Pair로 만들어서 사용하자는 개념이다.
쉽게 설명하자면,
Input에 들어가는 Sentence들을 빈칸이 뚤린 Cloze Question으로 변형하여, 빈칸을 맞추도록 하자는 건데,
원래 target값인 라벨들을 Yes나 No 처럼 바꾸어주는 Verbalizer 을 사용한 다음에 맞추는 것이다.
이처럼 변형된 Cloze Question을 MLM에 넣어서 로직값을 받고, Vocab에 수많은 토큰중에서 필요한 Yes, No 토큰만 가지고 이들만 softmax로 하여 빈칸이 뭐가 나올지 예측하는 것이다.
모델을 예측할때는 위와같이 하지만, 모델을 학습하고 싶다면 위에서 나온 값에서 크로스 엔트로피를 사용하여 Loss값을 구하고, Vocab에 있는 전체 토큰에 대해서도 Loss값을 구해서 이 둘을 합쳐서 전체적인 Loss를 설정하여 학습한다.
그러고 이렇게 예측하는 PVP에서 패턴을 다르게 설정하여 여러개의 PVP를 만든다음에 이를 앙상블하여 학습하면 성능이 좋다고한다. 이렇게하면 각기 다른 새로운 데이터를 얻을수 있다. 오른쪽에 새로운 데이터는 오타가 났다. "" 있어야한다.
이렇게 각기 다른 패턴으로 여러 PLM에 대해 학습하는 것을 반복하는것이 iPET이다.
두번째 논문에서 나온게 멀티플 마스크드인데, 예측해야하는 토큰이 하나가 아닌 두개 이상일 수도 있으니, 빈칸 두개 뚫어놓고 각각의 확률값에 따라 높은 확률을 가진 토큰을 먼저 넣는 방식으로 진행하면 빈칸을 두개도 뚫을 수 있다는 얘기이다.
논문에서는 각 Task마다 패턴을 어떻게 하면 좋을지 써놨는데, 여기서 약간의 단점이 나온다.
정규화된 공식 없이 저자가 일일이 수기로 해본 형식이다.
어쨌든 이런 방식으로 Roberta를 학습해보니 데이터가 많이 없을 때, iPET 방식이 다른 비지도학습 및 지도학습보다 성능이 높다고 한다.
여기 결과가 중요한데, ALBERT를 사용하였을때 파라미터는 223M 이지만, 그에반해 GPT는 175,000M이다.
근데 평균을 보면 파라미터가 훨씬 큰 GPT보다 성능이 더 높게 나온다.
따라서 논문에서 주장하는 건, 작은 LM이라도 논문에서 제시한 것 처럼 그 모델의 지식을 활용하여 예측하면 더 잘나올 수도 있다는 것이다.