Learning rate는 backpropagation 과정에서 모델의 weight인 gradient의 변화(업데이트의 보폭 step-size)이다.
역전파 과정에서 모델의 가중치(Weight)는 손실 함수의 오류 추정치를 줄이기 위해 업데이트된다.
학습률 * 추정 가중치 오류(가중치에 대한 기울기 or 전체 오류 변화) >>>> Weight 업데이트
Learning rate는 Optimizer가 Loss function의 최소값에 도달하도록 만드는 변화의 크기를 제어한다.
성능에 영향을 주는 요소인 learning rate를 잘못 설정하면 아예 학습이 안될 수도 있다.
그래서 모델 학습에서는 learning rate를 어떻게 설정할 지가 매우 중요한 요소이다.
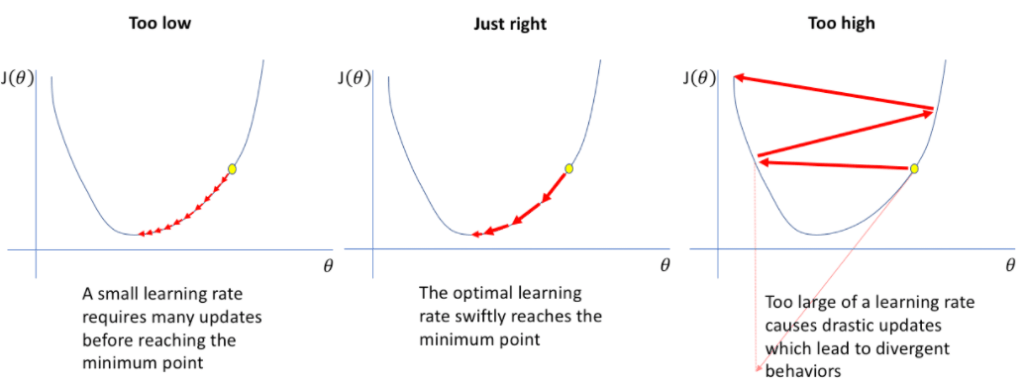
학습률이 크면 알고리즘은 빠르게 학습함.
but 알고리즘이 최소값으로 가지않고 왔다갔다하거나 다른 곳으로 뛰어넘을 수도 있음.
+ 가중치 업데이트하는 수준이 커서 가중치가 overflow 될 수도 있습니다.
학습률이 낮으면 가중치 업데이트가 작아서 옵티마이저가 최소값을 향해 천천히 움직임.
= 옵티마이저가 수렴하는 데 너무 시간이 오래 걸리거나 정체 상태 또는 글로벌 최소값이 아닌 로컬 최소값에 갇힐 수 있음.
학습률을 잘 설정할수만 있다면 성능 대박남.
알고리즘이 빠르게 수렴 가능할 수 있음.
알고리즘이 글로벌 최소값에 도달하지 않고 앞뒤로 점프할 가능성이 줄어듬.
근데 이 학습률을 정확하게 찍기가 어려움. 노가다임.
적절한 학습률을 찾는 이론적인 원리는 간단하지만, 너무 크지도 않고 너무 작지도 않는, 정말 딱 맞는 학습률을 찾는 것은 어려움.
이 문제를 해결하기 위해 나온 것 >>> "Learning rate schedule"
모델 학습 과정에서 처음부터 끝까지 똑같은 learning rate를 사용할 수도 있지만, 학습과정에서 learning rate를 조정하는 learning rate scheduler를 사용하면 더 좋은 성능을 기대할 수 있음.
처음엔 큰 learning rate(보폭)으로 빠르게 optimize를 하고, 최적값에 가까워질수록 learning rate(보폭)를 줄여 미세조정을 하는 것이 학습이 잘된다고 알려져있음.
learning rate를 그냥 쭉 decay(감쇠)하는 방법 말고, learning rate를 줄였다 늘렸다 하는 것이 더 성능향상에 도움이 된다는 연구결과가 있음.
Learning rate schedule = 학습이 진행됨에 따라 epoch or iteration 간에 학습률을 조정하는 사전 정의된 프레임워크.
Learning rate schedule에 대한 가장 일반적인 두 가지 기술
- 일정한 Learning rate:
학습률을 초기화하고 훈련 중에 변경 X
- Learning rate 감소:
초기 학습률을 선택한 다음 스케줄러에 따라 점차적으로 감소.
훈련 초기의 학습률> 충분히 괜찮은 가중치에 도달하기 위해 크게 설정.
시간이 지남에 따라 가중치는 작은 학습률을 활용하여 더 높은 정확도에 도달하도록 미세 조정.
즉, 점점 줄어드는거.
다른 작업에서 모델 돌릴 때 마다, 상황마다 조건이 다르기 때문에, 언제 학습률의 증가를 규제(Learning Rate Decay)해야 하는 지를 확실히 아는 것은 쉽지 않을 수 있음.
Learning Rate가 높으면, loss 값을 빠르게 내릴 수는 있지만, 최적의 학습을 벗어나게 만들고,
Learning Rate가 낮으면, 최적의 학습을 할 수 있지만 그 단계까지 너무 오랜 시간이 걸리게 됌.
따라서, 처음 모델 돌릴 때 Learning Rate 값을 크게 준 다음, 일정 epoch 마다 값을 감소시켜서 최적의 학습까지 더 빠르게 도달할 수 있게 하는 방법을 Learning Rate Decay라고 말함.
Step Decay > Learning Rate Decay를 특정 epoch를 기준으로 단계별로 learning rate을 감소시키는 것임.
특정 epoch 구간(step) 마다 일정한 비율로 감소 시켜주는 방법을 Step Decay라고 부름.
실제로 학습률을 조정하는데 있어 가장 널리 사용되는 방법이 Step Decay임.
상수값의 비율과 Epoch 단위만으로 학습률을 조정하는 것이기 때문에 사용하기 쉽고, 복잡한 연산의 이해를 요구하지 않으므로 직관적인 방법임.
근데, Step Decay를 사용하면 기존보다 생각해야하는 Hyper Parameter가 늘어나니 세팅해야하는 값들이 증가하고 세팅 값의 경우의 수가 더 많이 생겨서, 당시 사람들은 Hyper Parameter를 조금 덜 사용할 수 있는 다른 방법을 찾게 되었음.
그렇게해서 나온 연속적인 방법이 Cosine Decay.
Cosine Decay의 loss 그래프를 보면 Step Decay와는 달리 안정적으로 끊김없이 loss가 감소하는 것을 볼 수 있음.
Hyper Paremeters를 좀 덜 사용하고 learning rate도 연속적으로 사용하니 Cosine Decay를 Learning Rate Decay로 좀 더 고려를 많이 한다고 함.
다른 방법으로 Linear Decay, Inverse Sqrt(Inverse Square Root) Decay 등이 있음.
from transformers import get_cosine_schedule_with_warmup
from transformers import AdamW
# 옵티마이저 설정
optimizer = AdamW(
model.parameters(),
lr = 1e-5, # 학습률
eps = 1e-8 # 0으로 나누는 것을 방지하기 위한 epsilon 값,
)
epochs = 3
# 총 훈련 스텝
total_steps = len(train_dataloader) * epochs
# Learning rate decay를 위한 스케줄러
scheduler = get_cosine_schedule_with_warmup(
optimizer,
warmup_steps=5,
base_lr=0.3,
final_lr=0.01
)ex)
Optimizer = AdamW
Epoch= 3
총 학습 단계 수 = ( 특정한 batch로 나뉘어진 데이터셋의 batch 수 * epoch )
Scheduler에 이를 활용하여 총 학습 단계 수(num_training_steps)를 정의해줌.
num_warmup_steps는 활용하지 않아 0으로 설정이 되어있음.
이렇게 해서 정해진 학습률(lr)이, 매 학습 단계마다 제어되며, Step Decay를 활용한 학습률 Scheduling을 적용하게 됌.
LambdaLR
Lambda 표현식으로 작성한 함수를 통해 learning rate를 조절.
초기 learning rate에 lambda함수에서 나온 값을 곱해줘서 learning rate를 계산
optimizer = torch.optim.SGD(model.parameters(), lr=0.001)
scheduler = optim.lr_scheduler.LambdaLR(optimizer=optimizer,
lr_lambda=lambda epoch: 0.95 ** epoch)
MultiplicativeLR
LambdaLR랑 똑같음
optimizer = torch.optim.SGD(model.parameters(), lr=0.001)
scheduler = optim.lr_scheduler.MultiplicativeLR(optimizer=optimizer,
lr_lambda=lambda epoch: 0.95 ** epoch)
StepLR
step size마다 gamma 비율로 lr을 감소시킴. (step_size 마다 gamma를 곱함)
optimizer = torch.optim.SGD(model.parameters(), lr=0.001)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.5)
MultiStepLR
step size가 아니라 learning rate를 감소시킬 epoch을 지정해줌.
optimizer = torch.optim.SGD(model.parameters(), lr=0.001)
scheduler = optim.lr_scheduler.MultiStepLR(optimizer, milestones=[30,80], gamma=0.5)
ReduceLROnPlateau
성능이 향상이 없을 때 learning rate를 감소시킴.
validation loss나 metric(평가 지표)을 learning rate step함수의 input으로 넣어주어야 함.
그래서 metric이 향상되지 않을 때, patience횟수(epoch)만큼 대기했다가, 그 이후에는 learning rate를 줄임.
optimizer에 momentum을 설정해야 사용할 수 있다.
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
scheduler = ReduceLROnPlateau(optimizer, 'min') # min은 metric이 감소를 멈출 때/ max는 metric이 증가를 멈출 때
for epoch in range(100):
train(...)
val_loss = validate(...)
# Note that step should be called after validate()
scheduler.step(val_loss)
#patience: metric이 향상 안될 때, 몇 epoch을 참을 것인가?
#threshold: 새로운 optimum이 될 수 있는 threshold (얼마 차이나면 optimum update되었다고 볼 수 있나?)
#threshold_mode: dynamic threshold를 설정할 수 있다. 'rel' 이나 'abs' 중 하나의 모드로 설정한다. 'rel'모드이면 min일 때, best(1-threshold) max일 때, best(1+threshold)/ 'abs'모드이면 best+threshold
#cool_down: lr이 감소한 후 몇 epoch동안 lr scheduler동작을 쉴지
#min_lr: 최소 lr
#eps: 줄이기 전, 줄인 후 lr의 차이가 eps보다 작으면 무시한다.
get_cosine_schedule_with_warmup
0 ~ 옵티마이저의 설정한 초기 학습률
이 사이에서 선형적으로 증가하는 워밍업 기간 후에 옵티마이저에서 0으로 설정된 초기 lr 사이의 코사인 함수 값에 따라 감소하는 학습률로 스케줄을 생성.
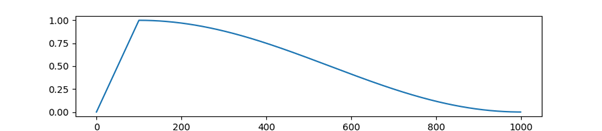
total_samples = 968
bs = 32
n_epochs = 10
num_warmup_steps = (total_samples // bs) * 2
num_total_steps = (total_samples // bs) * n_epochs
model = nn.Linear(2, 1)
optimizer = optim.SGD(model.parameters(), lr=0.01)
scheduler = transformers.get_cosine_schedule_with_warmup(optimizer,
num_warmup_steps=num_warmup_steps,
num_training_steps=num_total_steps)
lrs = []
for i in range(num_total_steps):
optimizer.step()
lrs.append(optimizer.param_groups[0]["lr"])
scheduler.step()
https://i0.wp.com/neptune.ai/wp-content/uploads/Learning-rate-scheduler.png?resize=1024%2C384&ssl=1
https://wikidocs.net/157282
Learning rate는 backpropagation 과정에서 모델의 weight인 gradient의 변화(업데이트의 보폭 step-size)이다.
역전파 과정에서 모델의 가중치(Weight)는 손실 함수의 오류 추정치를 줄이기 위해 업데이트된다.
학습률 * 추정 가중치 오류(가중치에 대한 기울기 or 전체 오류 변화) >>>> Weight 업데이트
Learning rate는 Optimizer가 Loss function의 최소값에 도달하도록 만드는 변화의 크기를 제어한다.
성능에 영향을 주는 요소인 learning rate를 잘못 설정하면 아예 학습이 안될 수도 있다.
그래서 모델 학습에서는 learning rate를 어떻게 설정할 지가 매우 중요한 요소이다.
학습률이 크면 알고리즘은 빠르게 학습함.
but 알고리즘이 최소값으로 가지않고 왔다갔다하거나 다른 곳으로 뛰어넘을 수도 있음.
+ 가중치 업데이트하는 수준이 커서 가중치가 overflow 될 수도 있습니다.
학습률이 낮으면 가중치 업데이트가 작아서 옵티마이저가 최소값을 향해 천천히 움직임.
= 옵티마이저가 수렴하는 데 너무 시간이 오래 걸리거나 정체 상태 또는 글로벌 최소값이 아닌 로컬 최소값에 갇힐 수 있음.
학습률을 잘 설정할수만 있다면 성능 대박남.
알고리즘이 빠르게 수렴 가능할 수 있음.
알고리즘이 글로벌 최소값에 도달하지 않고 앞뒤로 점프할 가능성이 줄어듬.
근데 이 학습률을 정확하게 찍기가 어려움. 노가다임.
적절한 학습률을 찾는 이론적인 원리는 간단하지만, 너무 크지도 않고 너무 작지도 않는, 정말 딱 맞는 학습률을 찾는 것은 어려움.
이 문제를 해결하기 위해 나온 것 >>> "Learning rate schedule"
모델 학습 과정에서 처음부터 끝까지 똑같은 learning rate를 사용할 수도 있지만, 학습과정에서 learning rate를 조정하는 learning rate scheduler를 사용하면 더 좋은 성능을 기대할 수 있음.
처음엔 큰 learning rate(보폭)으로 빠르게 optimize를 하고, 최적값에 가까워질수록 learning rate(보폭)를 줄여 미세조정을 하는 것이 학습이 잘된다고 알려져있음.
learning rate를 그냥 쭉 decay(감쇠)하는 방법 말고, learning rate를 줄였다 늘렸다 하는 것이 더 성능향상에 도움이 된다는 연구결과가 있음.
Learning rate schedule = 학습이 진행됨에 따라 epoch or iteration 간에 학습률을 조정하는 사전 정의된 프레임워크.
Learning rate schedule에 대한 가장 일반적인 두 가지 기술
- 일정한 Learning rate:
학습률을 초기화하고 훈련 중에 변경 X
- Learning rate 감소:
초기 학습률을 선택한 다음 스케줄러에 따라 점차적으로 감소.
훈련 초기의 학습률> 충분히 괜찮은 가중치에 도달하기 위해 크게 설정.
시간이 지남에 따라 가중치는 작은 학습률을 활용하여 더 높은 정확도에 도달하도록 미세 조정.
즉, 점점 줄어드는거.
다른 작업에서 모델 돌릴 때 마다, 상황마다 조건이 다르기 때문에, 언제 학습률의 증가를 규제(Learning Rate Decay)해야 하는 지를 확실히 아는 것은 쉽지 않을 수 있음.
Learning Rate가 높으면, loss 값을 빠르게 내릴 수는 있지만, 최적의 학습을 벗어나게 만들고,
Learning Rate가 낮으면, 최적의 학습을 할 수 있지만 그 단계까지 너무 오랜 시간이 걸리게 됌.
따라서, 처음 모델 돌릴 때 Learning Rate 값을 크게 준 다음, 일정 epoch 마다 값을 감소시켜서 최적의 학습까지 더 빠르게 도달할 수 있게 하는 방법을 Learning Rate Decay라고 말함.
Step Decay > Learning Rate Decay를 특정 epoch를 기준으로 단계별로 learning rate을 감소시키는 것임.
특정 epoch 구간(step) 마다 일정한 비율로 감소 시켜주는 방법을 Step Decay라고 부름.
실제로 학습률을 조정하는데 있어 가장 널리 사용되는 방법이 Step Decay임.
상수값의 비율과 Epoch 단위만으로 학습률을 조정하는 것이기 때문에 사용하기 쉽고, 복잡한 연산의 이해를 요구하지 않으므로 직관적인 방법임.
근데, Step Decay를 사용하면 기존보다 생각해야하는 Hyper Parameter가 늘어나니 세팅해야하는 값들이 증가하고 세팅 값의 경우의 수가 더 많이 생겨서, 당시 사람들은 Hyper Parameter를 조금 덜 사용할 수 있는 다른 방법을 찾게 되었음.
그렇게해서 나온 연속적인 방법이 Cosine Decay.
Cosine Decay의 loss 그래프를 보면 Step Decay와는 달리 안정적으로 끊김없이 loss가 감소하는 것을 볼 수 있음.
Hyper Paremeters를 좀 덜 사용하고 learning rate도 연속적으로 사용하니 Cosine Decay를 Learning Rate Decay로 좀 더 고려를 많이 한다고 함.
다른 방법으로 Linear Decay, Inverse Sqrt(Inverse Square Root) Decay 등이 있음.
from transformers import get_cosine_schedule_with_warmup
from transformers import AdamW
# 옵티마이저 설정
optimizer = AdamW(
model.parameters(),
lr = 1e-5, # 학습률
eps = 1e-8 # 0으로 나누는 것을 방지하기 위한 epsilon 값,
)
epochs = 3
# 총 훈련 스텝
total_steps = len(train_dataloader) * epochs
# Learning rate decay를 위한 스케줄러
scheduler = get_cosine_schedule_with_warmup(
optimizer,
warmup_steps=5,
base_lr=0.3,
final_lr=0.01
)ex)
Optimizer = AdamW
Epoch= 3
총 학습 단계 수 = ( 특정한 batch로 나뉘어진 데이터셋의 batch 수 * epoch )
Scheduler에 이를 활용하여 총 학습 단계 수(num_training_steps)를 정의해줌.
num_warmup_steps는 활용하지 않아 0으로 설정이 되어있음.
이렇게 해서 정해진 학습률(lr)이, 매 학습 단계마다 제어되며, Step Decay를 활용한 학습률 Scheduling을 적용하게 됌.
LambdaLR
Lambda 표현식으로 작성한 함수를 통해 learning rate를 조절.
초기 learning rate에 lambda함수에서 나온 값을 곱해줘서 learning rate를 계산
optimizer = torch.optim.SGD(model.parameters(), lr=0.001)
scheduler = optim.lr_scheduler.LambdaLR(optimizer=optimizer,
lr_lambda=lambda epoch: 0.95 ** epoch)
MultiplicativeLR
LambdaLR랑 똑같음
optimizer = torch.optim.SGD(model.parameters(), lr=0.001)
scheduler = optim.lr_scheduler.MultiplicativeLR(optimizer=optimizer,
lr_lambda=lambda epoch: 0.95 ** epoch)
StepLR
step size마다 gamma 비율로 lr을 감소시킴. (step_size 마다 gamma를 곱함)
optimizer = torch.optim.SGD(model.parameters(), lr=0.001)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.5)
MultiStepLR
step size가 아니라 learning rate를 감소시킬 epoch을 지정해줌.
optimizer = torch.optim.SGD(model.parameters(), lr=0.001)
scheduler = optim.lr_scheduler.MultiStepLR(optimizer, milestones=[30,80], gamma=0.5)
ReduceLROnPlateau
성능이 향상이 없을 때 learning rate를 감소시킴.
validation loss나 metric(평가 지표)을 learning rate step함수의 input으로 넣어주어야 함.
그래서 metric이 향상되지 않을 때, patience횟수(epoch)만큼 대기했다가, 그 이후에는 learning rate를 줄임.
optimizer에 momentum을 설정해야 사용할 수 있다.
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
scheduler = ReduceLROnPlateau(optimizer, 'min') # min은 metric이 감소를 멈출 때/ max는 metric이 증가를 멈출 때
for epoch in range(100):
train(...)
val_loss = validate(...)
# Note that step should be called after validate()
scheduler.step(val_loss)
#patience: metric이 향상 안될 때, 몇 epoch을 참을 것인가?
#threshold: 새로운 optimum이 될 수 있는 threshold (얼마 차이나면 optimum update되었다고 볼 수 있나?)
#threshold_mode: dynamic threshold를 설정할 수 있다. 'rel' 이나 'abs' 중 하나의 모드로 설정한다. 'rel'모드이면 min일 때, best(1-threshold) max일 때, best(1+threshold)/ 'abs'모드이면 best+threshold
#cool_down: lr이 감소한 후 몇 epoch동안 lr scheduler동작을 쉴지
#min_lr: 최소 lr
#eps: 줄이기 전, 줄인 후 lr의 차이가 eps보다 작으면 무시한다.
get_cosine_schedule_with_warmup
0 ~ 옵티마이저의 설정한 초기 학습률
이 사이에서 선형적으로 증가하는 워밍업 기간 후에 옵티마이저에서 0으로 설정된 초기 lr 사이의 코사인 함수 값에 따라 감소하는 학습률로 스케줄을 생성.
total_samples = 968
bs = 32
n_epochs = 10
num_warmup_steps = (total_samples // bs) * 2
num_total_steps = (total_samples // bs) * n_epochs
model = nn.Linear(2, 1)
optimizer = optim.SGD(model.parameters(), lr=0.01)
scheduler = transformers.get_cosine_schedule_with_warmup(optimizer,
num_warmup_steps=num_warmup_steps,
num_training_steps=num_total_steps)
lrs = []
for i in range(num_total_steps):
optimizer.step()
lrs.append(optimizer.param_groups[0]["lr"])
scheduler.step()
https://i0.wp.com/neptune.ai/wp-content/uploads/Learning-rate-scheduler.png?resize=1024%2C384&ssl=1
https://wikidocs.net/157282