Natural Language Processing with Disaster Tweets
Predict which Tweets are about real disasters and which ones are not
https://www.kaggle.com/c/nlp-getting-started
Natural Language Processing with Disaster Tweets | Kaggle
www.kaggle.com
NLP 공부를 하면서 초기 논문부터 하나씩 보면서 작성해보고, 최신 트렌드를 공부해가면서,
직접 데이터 처리부터 모델을 돌려보고, 자연어를 어떻게 처리하는지 과정을 직접 경험해 보고 싶었다.
즉, NLP 모델을 돌리기 위한 직접 코딩을 하고 싶었다.
기존에 BERT Model을 공부하면서 인터넷에 있는 예제로 네이버 리뷰 감성분류를 해보았었는데,
다른 문제를 직접 풀어보고 싶어서 Kaggle을 뒤적거리다가 자연어처리의 타이타닉 같은 NLP 공부 대회가 있었다.
이를 기존에 작성했던 코드들을 응용해서 직접 대회에 참가하여 코딩을 해보았다.
이 대회는 트위터에 재난 트윗을 분류하는 대회인데, 트윗을 보고 실제로 재난상황인지, 거짓 재난상황인지 구분하여 라벨링하는 Getting Started competitions이다.
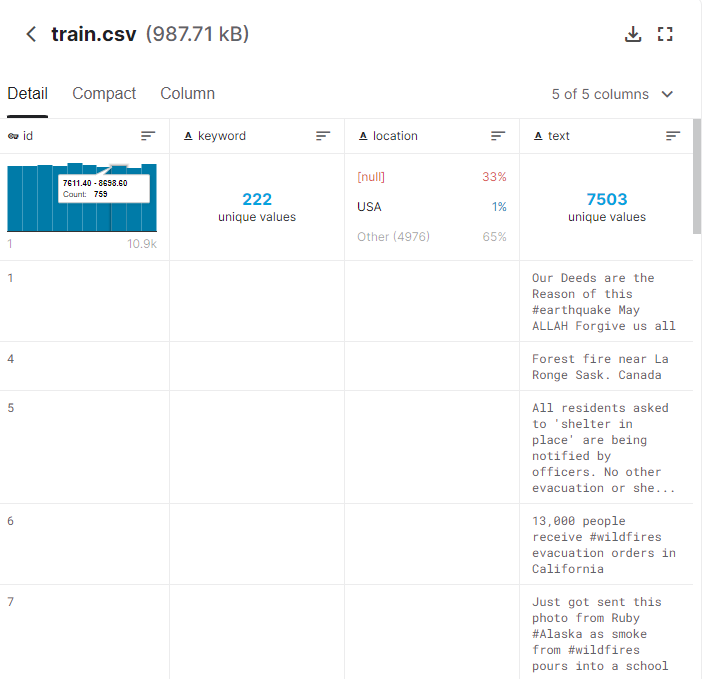
Train 데이터셋은 이러한 형식의 CSV 파일이다.
import pandas as pd
import torch
from torch.utils.data import Dataset, DataLoader
from pytorch_transformers import BertTokenizer, BertForSequenceClassification
from torch.optim import Adam
import torch.nn.functional as F
train_data = pd.read_csv('train.csv')
test_data = pd.read_csv('test.csv')
train_data.head() # 7,613 Rows 5 Columns
train_df = train_data.dropna()
test_df = test_data.dropna()
train_df.shape #5,080 Rows 5 Columns필요한 라이브러리를 불러오고 데이터셋 파일을 분석해보니 7,613개의 Rows가 있었다.
그리 많지않은 데이터이기에 NLP 공부를 하면서 모델을 돌려보기에 좋은 데이터 같았다.
그러나 다른 할일들도 있고 이 대회에 많은 시간을 투자할 수 없는 상황이며, 그렇기에 짧은 시간에 풀기 위해 간단한 전처리를 진행해 주었다.
일단, 결측치를 전부 제거하였다.
결측치를 대체하고 이 데이터를 분석하기에는 시간이 없었따..
그랬더니 7,613 -> 5,080으로 데이터가 줄었다. 5000개의 데이터로 잘 될려나 걱정했었다.
class load_dataset(Dataset) :
def __init__(self, df):
self.df = df
def __len__(self):
return len(self.df)
def __getitem__(self, item):
text = self.df.iloc[item, 3]
label = self.df.iloc[item,4]
return text, label데이터를 처리하기 위해 간단하게 class하나를 정의하여 text와 label이 return 되도록 만들었다.
train_dataset = load_dataset(train_df)
train_loader = DataLoader(train_dataset, shuffle=True)그러고 데이터를 넣어서 keywords, location, Id Column 값들은 전부 제거하고 간단하게 Text, Label 값만 뽑았다.
device = torch.device("cuda")
tokenizer = BertTokenizer.from_pretrained('bert-base-multilingual-cased')
model = BertForSequenceClassification.from_pretrained('bert-base-multilingual-cased')
model.to(device)
optimizer = Adam(model.parameters(), lr=1e-6)
""" 모델 학습 """
model.train()그러고 모델을 돌리기 위해 pretrained 된 Bert의 Classification 모델을 불러와서 이를 CUDA에 올리고 준비를 하였다.
total_corrct = 0
total_len = 0
total_loss = 0
count = 0
for epoch in range(1) :
for text, label in train_loader:
optimizer.zero_grad()
#한 문장에서 단어씩
#<CLS>, <SEP> 등의 special token을 추가
encoding_list = [tokenizer.encode(x, add_special_tokens=True) for x in text]
padding_list = [x + [0]*(256-len(x)) for x in encoding_list]
sample = torch.tensor(padding_list)
sample = sample.to(device)
#label = torch.tensor(label)
label = label.to(device)
outputs = model(sample, labels=label)
loss, logits = outputs
print(logits)
predict = torch.argmax(F.softmax(logits), dim=1)
print(predict)
corrct = predict.eq(label)
total_corrct += corrct.sum()
total_len += len(label)
total_loss += loss
loss.backward()
optimizer.step()
break
if count % 1000 ==0 :
print(f'Epoch : {epoch+1}, Iteration : {count}')
print(f'Train Loss : {total_loss/1000}')
print(f'Accuracy : {total_corrct/total_len}\n')
count +=1
model.eval()그러고 이렇게 돌려서 대회를 위한 BERT 모델을 만들고, 성능을 평가하고 이 모델을 저장하여 사용하였다.
에포크를 여러번 돌릴걸 그랬나 일단 데이터 전처리도 간단하게 했으니 에포크도 한번만 돌렸다.
아마 Accuracy가 80% 이상으로 나왔던거 같다.
그래서 만족해서 바로 끝내고 Predict로 넘어갔다.
(시간을 많이 투자할 여유가 없었기에..)
""" Predict.py """
import pandas as pd
import torch
from torch.utils.data import DataLoader
from pytorch_transformers import BertTokenizer
import csv
import re
test_data = pd.read_csv('test.csv')
test_df = test_data.fillna("null")
model = torch.load('predict_of_tweet_model.pth')똑같이 라이브러리 로드하고, test 데이터셋과 모델을 불러오고, 간단하게 결측치를 "null"로 대체해줬다.
model.to(torch.device('cpu'))
tokenizer = BertTokenizer.from_pretrained('bert-base-multilingual-cased')
test_dataset = test_df["text"] #2,158 Rows
processing_test_dataset = test_dataset.reset_index()["text"]
processing_test_dataset = DataLoader(processing_test_dataset)test 데이터셋에는 2,158개의 Rows가 있었다.
근데 이상하게 여기서는 CUDA가 메모리 초과가 계속떠서 방법찾다가 그냥 CPU로 돌려줬다.
id도 0부터 있는게 아닌 뜨문뜨문 있어서 인덱스 초기화해주고 불러왔다.
final = []
for text in processing_test_dataset:
encoding_list = [tokenizer.encode(x, add_special_tokens=True) for x in text]
padding_list = [x + [0]*(256-len(x)) for x in encoding_list]
sample = torch.tensor(padding_list)
sample = sample.to(torch.device('cpu'))
outputs = model(sample)
predict = torch.argmax(outputs[0],dim=1)
print(f'predict -> {predict}')
final.append(predict.int())이러고 이전 모델 학습할때와 같이 데이터 처리 후에 이를 모델에 넣고 Predict를 진행하였다.
이렇게 나온 predict 값들은 list로 append해서 저장해 주었는데,
0과 1로 나오는게아닌
"Tensor[1], dtype=uint32" 뭐 이런식으로 되어 나오기에 또한번 처리를 해주었다.
re_pattern = re.compile(r'\d')
temp = final
target_list = list()
for x in temp :
temp = re.findall(re_pattern, str(x))
target_list.append(temp[0])얘네들을 처리하려고 정규식을 넣어서 숫자만 뽑아주면 [예측타켓값(0 or 1), 3, 2] 이런식으로 나온다. 뒤에 데이터타입에 붙는 숫자까지 따라 나오기에 그중 첫번째 숫자만 뽑아서 새로운 리스트에 저장해주었다.
이렇게되면 list에는 [1,1,0,0,0,0,0,1,0,1,0,1,...] 이런식으로 예측값들이 나오게 된다.
with open('predict.csv', 'w', newline='') as f :
writer = csv.writer(f)
writer.writerow(target_list)
data_id = pd.DataFrame(test_data['id'])
data_target = pd.DataFrame(target_list)
result = pd.concat([data_id, data_target], axis=1)
result.to_csv("result.csv")그러면 이 나온 값과 기존의 test 데이터셋에 있는 id와 합쳐주면 최종 제출 파일이 만들어진다.
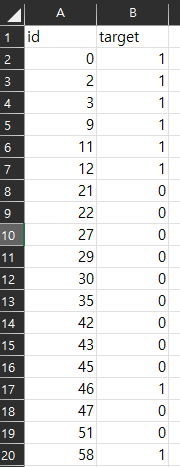
이제 이 파일을 Kaggle에 보내서 점수를 확인해 보았다.
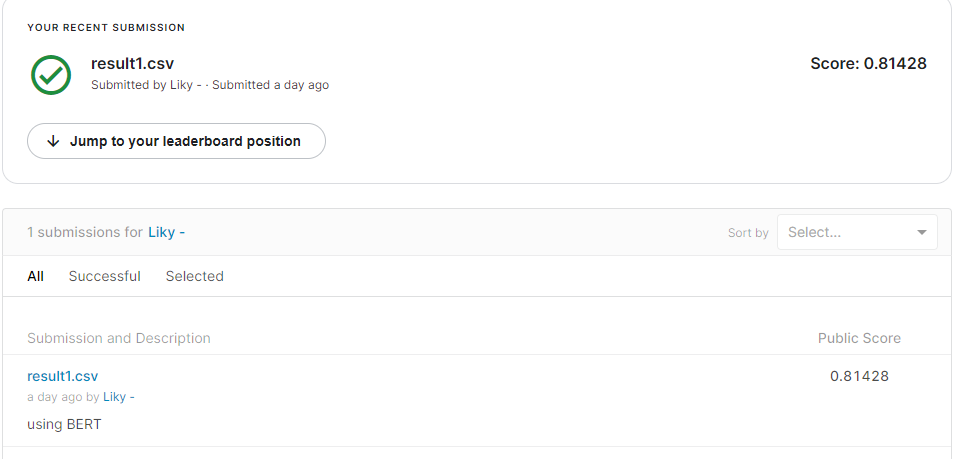
81점이 나왔다.
이 점수는 81.428% 맞추었다는 것 같다.
데이터 처리 엄청 간단하게 했는데도 생각보다 높은 점수가 나왔다.
여기서 BERT 모델의 어마무시한 성능을 느낄수가 있었다..
이렇게 해서 NLP 대회를 한번 참가해 보았는데, 그전까지만해도 NLP 어렵고 재미없게 느껴졌는데 막상 직접 풀어보니 비전과 크게 다를게 없다고 느껴졌다. 더 공부하고 더 파봐야겠다.
Natural Language Processing with Disaster Tweets
Predict which Tweets are about real disasters and which ones are not
https://www.kaggle.com/c/nlp-getting-started
Natural Language Processing with Disaster Tweets | Kaggle
www.kaggle.com
NLP 공부를 하면서 초기 논문부터 하나씩 보면서 작성해보고, 최신 트렌드를 공부해가면서,
직접 데이터 처리부터 모델을 돌려보고, 자연어를 어떻게 처리하는지 과정을 직접 경험해 보고 싶었다.
즉, NLP 모델을 돌리기 위한 직접 코딩을 하고 싶었다.
기존에 BERT Model을 공부하면서 인터넷에 있는 예제로 네이버 리뷰 감성분류를 해보았었는데,
다른 문제를 직접 풀어보고 싶어서 Kaggle을 뒤적거리다가 자연어처리의 타이타닉 같은 NLP 공부 대회가 있었다.
이를 기존에 작성했던 코드들을 응용해서 직접 대회에 참가하여 코딩을 해보았다.
이 대회는 트위터에 재난 트윗을 분류하는 대회인데, 트윗을 보고 실제로 재난상황인지, 거짓 재난상황인지 구분하여 라벨링하는 Getting Started competitions이다.
Train 데이터셋은 이러한 형식의 CSV 파일이다.
import pandas as pd
import torch
from torch.utils.data import Dataset, DataLoader
from pytorch_transformers import BertTokenizer, BertForSequenceClassification
from torch.optim import Adam
import torch.nn.functional as F
train_data = pd.read_csv('train.csv')
test_data = pd.read_csv('test.csv')
train_data.head() # 7,613 Rows 5 Columns
train_df = train_data.dropna()
test_df = test_data.dropna()
train_df.shape #5,080 Rows 5 Columns필요한 라이브러리를 불러오고 데이터셋 파일을 분석해보니 7,613개의 Rows가 있었다.
그리 많지않은 데이터이기에 NLP 공부를 하면서 모델을 돌려보기에 좋은 데이터 같았다.
그러나 다른 할일들도 있고 이 대회에 많은 시간을 투자할 수 없는 상황이며, 그렇기에 짧은 시간에 풀기 위해 간단한 전처리를 진행해 주었다.
일단, 결측치를 전부 제거하였다.
결측치를 대체하고 이 데이터를 분석하기에는 시간이 없었따..
그랬더니 7,613 -> 5,080으로 데이터가 줄었다. 5000개의 데이터로 잘 될려나 걱정했었다.
class load_dataset(Dataset) :
def __init__(self, df):
self.df = df
def __len__(self):
return len(self.df)
def __getitem__(self, item):
text = self.df.iloc[item, 3]
label = self.df.iloc[item,4]
return text, label데이터를 처리하기 위해 간단하게 class하나를 정의하여 text와 label이 return 되도록 만들었다.
train_dataset = load_dataset(train_df)
train_loader = DataLoader(train_dataset, shuffle=True)그러고 데이터를 넣어서 keywords, location, Id Column 값들은 전부 제거하고 간단하게 Text, Label 값만 뽑았다.
device = torch.device("cuda")
tokenizer = BertTokenizer.from_pretrained('bert-base-multilingual-cased')
model = BertForSequenceClassification.from_pretrained('bert-base-multilingual-cased')
model.to(device)
optimizer = Adam(model.parameters(), lr=1e-6)
""" 모델 학습 """
model.train()그러고 모델을 돌리기 위해 pretrained 된 Bert의 Classification 모델을 불러와서 이를 CUDA에 올리고 준비를 하였다.
total_corrct = 0
total_len = 0
total_loss = 0
count = 0
for epoch in range(1) :
for text, label in train_loader:
optimizer.zero_grad()
#한 문장에서 단어씩
#<CLS>, <SEP> 등의 special token을 추가
encoding_list = [tokenizer.encode(x, add_special_tokens=True) for x in text]
padding_list = [x + [0]*(256-len(x)) for x in encoding_list]
sample = torch.tensor(padding_list)
sample = sample.to(device)
#label = torch.tensor(label)
label = label.to(device)
outputs = model(sample, labels=label)
loss, logits = outputs
print(logits)
predict = torch.argmax(F.softmax(logits), dim=1)
print(predict)
corrct = predict.eq(label)
total_corrct += corrct.sum()
total_len += len(label)
total_loss += loss
loss.backward()
optimizer.step()
break
if count % 1000 ==0 :
print(f'Epoch : {epoch+1}, Iteration : {count}')
print(f'Train Loss : {total_loss/1000}')
print(f'Accuracy : {total_corrct/total_len}\n')
count +=1
model.eval()그러고 이렇게 돌려서 대회를 위한 BERT 모델을 만들고, 성능을 평가하고 이 모델을 저장하여 사용하였다.
에포크를 여러번 돌릴걸 그랬나 일단 데이터 전처리도 간단하게 했으니 에포크도 한번만 돌렸다.
아마 Accuracy가 80% 이상으로 나왔던거 같다.
그래서 만족해서 바로 끝내고 Predict로 넘어갔다.
(시간을 많이 투자할 여유가 없었기에..)
""" Predict.py """
import pandas as pd
import torch
from torch.utils.data import DataLoader
from pytorch_transformers import BertTokenizer
import csv
import re
test_data = pd.read_csv('test.csv')
test_df = test_data.fillna("null")
model = torch.load('predict_of_tweet_model.pth')똑같이 라이브러리 로드하고, test 데이터셋과 모델을 불러오고, 간단하게 결측치를 "null"로 대체해줬다.
model.to(torch.device('cpu'))
tokenizer = BertTokenizer.from_pretrained('bert-base-multilingual-cased')
test_dataset = test_df["text"] #2,158 Rows
processing_test_dataset = test_dataset.reset_index()["text"]
processing_test_dataset = DataLoader(processing_test_dataset)test 데이터셋에는 2,158개의 Rows가 있었다.
근데 이상하게 여기서는 CUDA가 메모리 초과가 계속떠서 방법찾다가 그냥 CPU로 돌려줬다.
id도 0부터 있는게 아닌 뜨문뜨문 있어서 인덱스 초기화해주고 불러왔다.
final = []
for text in processing_test_dataset:
encoding_list = [tokenizer.encode(x, add_special_tokens=True) for x in text]
padding_list = [x + [0]*(256-len(x)) for x in encoding_list]
sample = torch.tensor(padding_list)
sample = sample.to(torch.device('cpu'))
outputs = model(sample)
predict = torch.argmax(outputs[0],dim=1)
print(f'predict -> {predict}')
final.append(predict.int())이러고 이전 모델 학습할때와 같이 데이터 처리 후에 이를 모델에 넣고 Predict를 진행하였다.
이렇게 나온 predict 값들은 list로 append해서 저장해 주었는데,
0과 1로 나오는게아닌
"Tensor[1], dtype=uint32" 뭐 이런식으로 되어 나오기에 또한번 처리를 해주었다.
re_pattern = re.compile(r'\d')
temp = final
target_list = list()
for x in temp :
temp = re.findall(re_pattern, str(x))
target_list.append(temp[0])얘네들을 처리하려고 정규식을 넣어서 숫자만 뽑아주면 [예측타켓값(0 or 1), 3, 2] 이런식으로 나온다. 뒤에 데이터타입에 붙는 숫자까지 따라 나오기에 그중 첫번째 숫자만 뽑아서 새로운 리스트에 저장해주었다.
이렇게되면 list에는 [1,1,0,0,0,0,0,1,0,1,0,1,...] 이런식으로 예측값들이 나오게 된다.
with open('predict.csv', 'w', newline='') as f :
writer = csv.writer(f)
writer.writerow(target_list)
data_id = pd.DataFrame(test_data['id'])
data_target = pd.DataFrame(target_list)
result = pd.concat([data_id, data_target], axis=1)
result.to_csv("result.csv")그러면 이 나온 값과 기존의 test 데이터셋에 있는 id와 합쳐주면 최종 제출 파일이 만들어진다.
이제 이 파일을 Kaggle에 보내서 점수를 확인해 보았다.
81점이 나왔다.
이 점수는 81.428% 맞추었다는 것 같다.
데이터 처리 엄청 간단하게 했는데도 생각보다 높은 점수가 나왔다.
여기서 BERT 모델의 어마무시한 성능을 느낄수가 있었다..
이렇게 해서 NLP 대회를 한번 참가해 보았는데, 그전까지만해도 NLP 어렵고 재미없게 느껴졌는데 막상 직접 풀어보니 비전과 크게 다를게 없다고 느껴졌다. 더 공부하고 더 파봐야겠다.