허깅페이스는 Tensorflow Hub와 유사한 기능을 제공하는 곳이다.
트랜스포머를 기반으로 하는 다양한 모델들이 존재하며, 각각의 Task에 맞게 미세조정을 진행한 모델들 또한 구축되어있다. 또한, 데이터를 각 모델에 맞게 전처리하기 편리하도록 Tokenizer도 전부 구현되어있다.
그 뿐만 아니라, 학습을 위해 필요한 데이터셋도 저장되어 있어, 사용자는 그저 가져온 뒤 사용하기만 하면 된다.
즉, 허깅페이스를 사용하면 기존 학습 스크립트에서 반복되는 모든 부분을 일일이 따로 구현하지 않아도 편리하게 사용할 수 있으며, 데이터 구축부터 전처리, 모델 학습 및 결과 도출까지 매우 편리하고 효율적으로 코딩할 수 있다는 장점이 있다.
허깅페이스는 다양한 트랜스포머 모델과 학습 스크립트를 제공하는 모듈로, pytorch와 tensorflow로 각각 구현되어 있다. 먼저 필요한 모델을 자신의 작업에 맞게 가져오면 된다.
간단하게 Fill-Mask를 위해 BERT 모델을 사용하고 싶다면 "bert-base-uncased" 처럼 검색을 하여 들어가서 정보를 확인하면 된다.
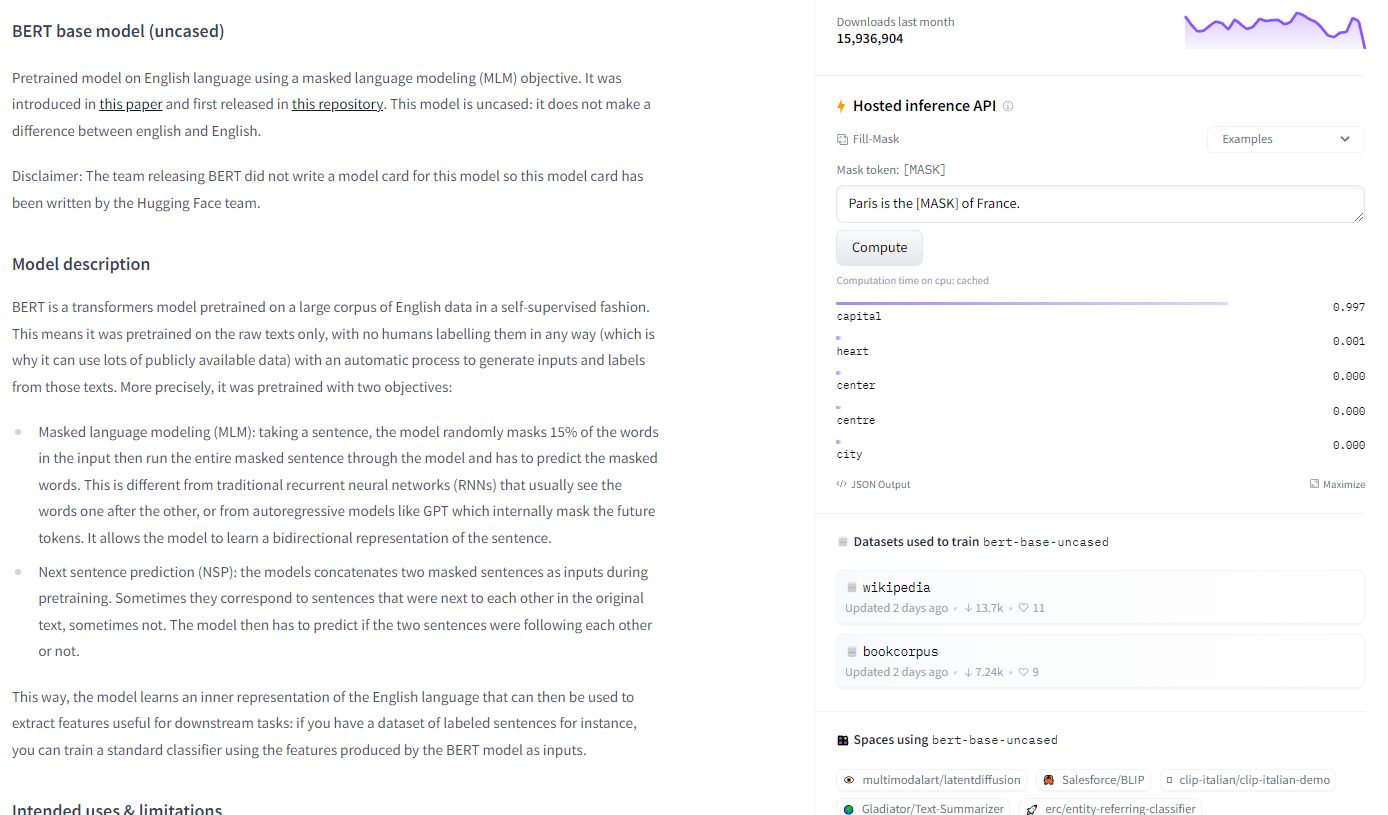
이 모델을 매우 간단하게 사용하는 방법은 아래와 같다.
#BERT 모델과 이를 위한 BERT 모델에 맞는 Tokenizer을 가져온다.
from transformers import BertTokenizer, BertModel
#토크나이저는 미리 학습된 'bert-base-uncased'에서 가져온다.
#BertTokenizer대신 AutoTokenizer을 사용해도 된다.
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
# 모델은 사전 학습된 "bert-base-uncased"을 가져와서 사용한다.
# 이또한 AutoModel을 import하여 사용할 수 있다.
model = BertModel.from_pretrained("bert-base-uncased")
#데이터를 입력한뒤
text = "Replace me by any text you'd like."
#토크나이저로 데이터를 모델에 넣을 수 있게 만들어준다.
#'pt'는 pytorch, 'tf'는 tensorflow를 의미한다.
encoded_input = tokenizer(text, return_tensors='pt')
#마지막으로 모델에 데이터를 넣으면 끝난다.
output = model(**encoded_input)데이터를 가져오는 것은 아래와 같다.
from datasets import load_dataset
# 허깅페이스에서 SNLI 데이터셋 가져오기
raw_datasets = load_dataset("snli")간단하게 가져와서 사용만 한다면 위와 같은 방법으로 가능하다.
허깅페이스에서 트랜스포머 모델을 가져와서 자신의 작업에 맞게 미세조정 하는 방법은 다음과 같다.
예시로 Text Classification 하는 모델이다.
#학습에 사용할 옵티마이저를 설정
from transformers import AdamW
optimizer = AdamW(model.parameters(), lr=2e-5)
#데이터셋을 전처리 완료했다는 가정하에, 학습을 위한 기타 설정을 진행한다.
num_epochs = 5
num_training_steps = num_epochs * len(train_dataloader)
lr_scheduler = get_scheduler(
"linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=num_training_steps,
)
#가져온 모델을 사용하여 학습을 진행한다.
for batch in train_dataloader:
model.train()
optimizer.zero_grad()
batch = {k: v.to(device) for k, v in batch.items()}
outputs = model(**batch)
loss = outputs.loss
loss.backward()
optimizer.step()
lr_scheduler.step()
torch.save(model,model_save_path)이와 같은 방법으로 학습을 진행하는데,
학습율을 작게 설정하여 자신의 데이터셋으로 미세 조정 시키면 된다.
중간에 학습되는 과정을 확인하고 싶으면, 아래와 같이 설정하여 성능을 확인할 수 있다.
# 에포크가 하나 진행되었을 때 마다 돌아가도록 설정하면 된다.
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for batch in eval_dataloader:
batch = {k: v.to(device) for k, v in batch.items()}
outputs = model(**batch)
logits = outputs.logits
predict = torch.argmax(logits, dim=-1)
metric.add_batch(predictions=predict, references=batch["labels"])
print(metric.compute())혹여나 다른 Task의 작업을 위해 만들어놓은 모델을 자신의 Task에 맞게 모델의 아웃풋을 추가하거나 수정하고 싶다면 다음과 같은 방법이 있다.
#모델정의하고 모델에 배치 전달
from transformers import AutoModelForSequenceClassification
from transformers import AutoConfig
# model을 수정할 거라고 설정
config_model = AutoConfig.from_pretrained(model_name)
# 모델의 마지막 부분에 Classification을 위해 3개의 아웃풋으로 설정함
config_model.num_labels = 3
# 수정한 모델을 사용할 거라고 설정
model =AutoModelForSequenceClassification.from_config(config_model)현재까지는 Classification을 위한 예시이며, 회귀나 다른 Task의 작업은 허깅페이스 홈페이지에 자세히 설명되어있다.
https://huggingface.co/
매우 편하고 쓰기 쉽다. 자연어 처리 공부하면서 유용하게 잘 쓰고 있다.